
Natural-language understanding (NLU) has long been a central focus of the papers that Amazon researchers publish at the Conference on Empirical Methods in Natural-Language Processing (EMNLP), but at this year's conference, which starts today, Amazon's NLU research shows a particular interest in harnessing the power of large language models (LLMs). Question answering also remains an active research topic, while query reformulation and text summarization emerge as new areas of concentration.
Automatic speech recognition
AdaBERT-CTC: Leveraging BERT-CTC for text-only domain adaptation in ASR
Tyler Vuong, Karel Mundnich, Dhanush Bekal, Veera Raghavendra Elluru, Srikanth Ronanki, Sravan Bodapati
Continual learning
Coordinated replay sample selection for continual federated learning
Jack Good, Jimit Majmudar, Christophe Dupuy, Jixuan Wang, Charith Peris, Clement Chung, Richard Zemel, Rahul Gupta
Data extraction
InsightNet: Structured insight mining from customer feedback
Sandeep Mukku, Manan Soni, Chetan Aggarwal, Jitenkumar Rana, Promod Yenigalla, Rashmi Patange, Shyam Mohan
Knowledge-selective pretraining for attribute value extraction
Hui Liu, Qingyu Yin, Zhengyang Wang, Chenwei Zhang, Haoming Jiang, Yifan Gao, Zheng Li, Xian Li, Chenwei Zhang, Bing Yin, William Wang, Xiaodan Zhu
Data selection
Influence scores at scale for efficient language data sampling
Nikhil Anand, Joshua Tan, Maria Minakova
Document understanding
A multi-modal multilingual benchmark for document image classification
Yoshinari Fujinuma, Siddharth Varia, Nishant Sankaran, Bonan Min, Srikar Appalaraju, Yogarshi Vyas
Semantic matching for text classification with complex class descriptions
Brian de Silva, Kuan-Wen Huang, Gwang Lee, Karen Hovsepian, Yan Xu, Mingwei Shen
Embodied task completion
Multimodal embodied plan prediction augmented with synthetic embodied dialogue
Aishwarya Padmakumar, Mert Inan, Spandana Gella, Patrick Lange, Dilek Hakkani-Tür
Entity linking
MReFinED: An efficient end-to-end multilingual entity linking system
Peerat Limkonchotiwat, Weiwei Cheng, Christos Christodoulopoulos, Amir Saffari, Jens Lehmann
Few-shot learning
Automated few-shot classification with instruction-finetuned language models
Rami Aly, Xingjian Shi, Kaixiang Lin, Aston Zhang, Andrew Wilson
Information retrieval
Deep metric learning to hierarchically rank—An application in product retrieval
Kee Kiat Koo, Ashutosh Joshi, Nishaanth Reddy, Ismail Tutar, Vaclav Petricek, Changhe Yuan, Karim Bouyarmane
KD-Boost: Boosting real-time semantic matching in e-commerce with knowledge distillation
Sanjay Agrawal, Vivek Sembium, Ankith M S
Multi-teacher distillation for multilingual spelling correction
Jingfen Zhang, Xuan Guo, Sravan Bodapati, Christopher Potts
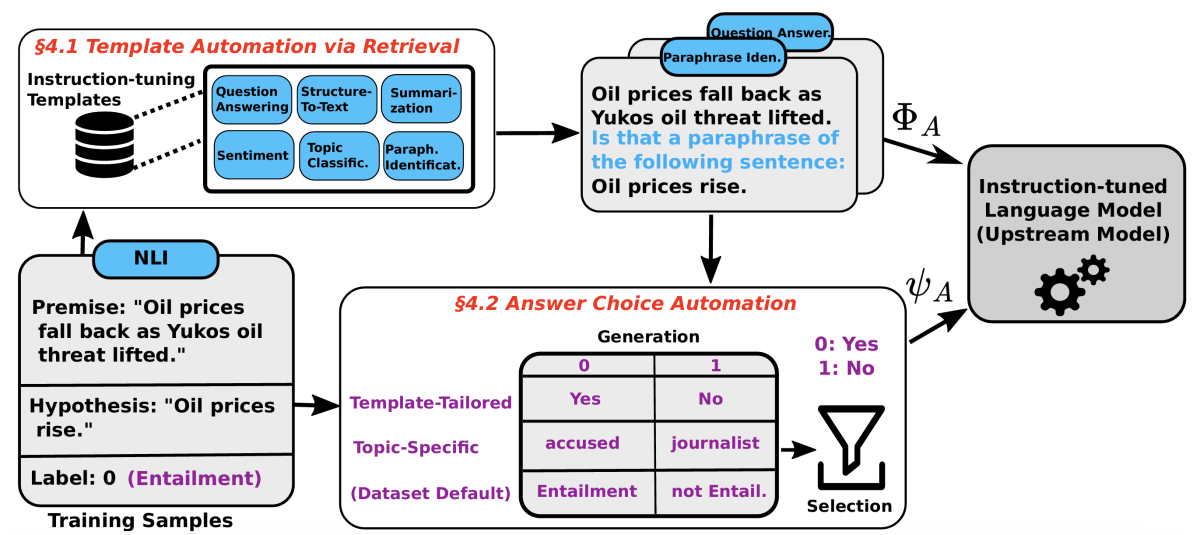
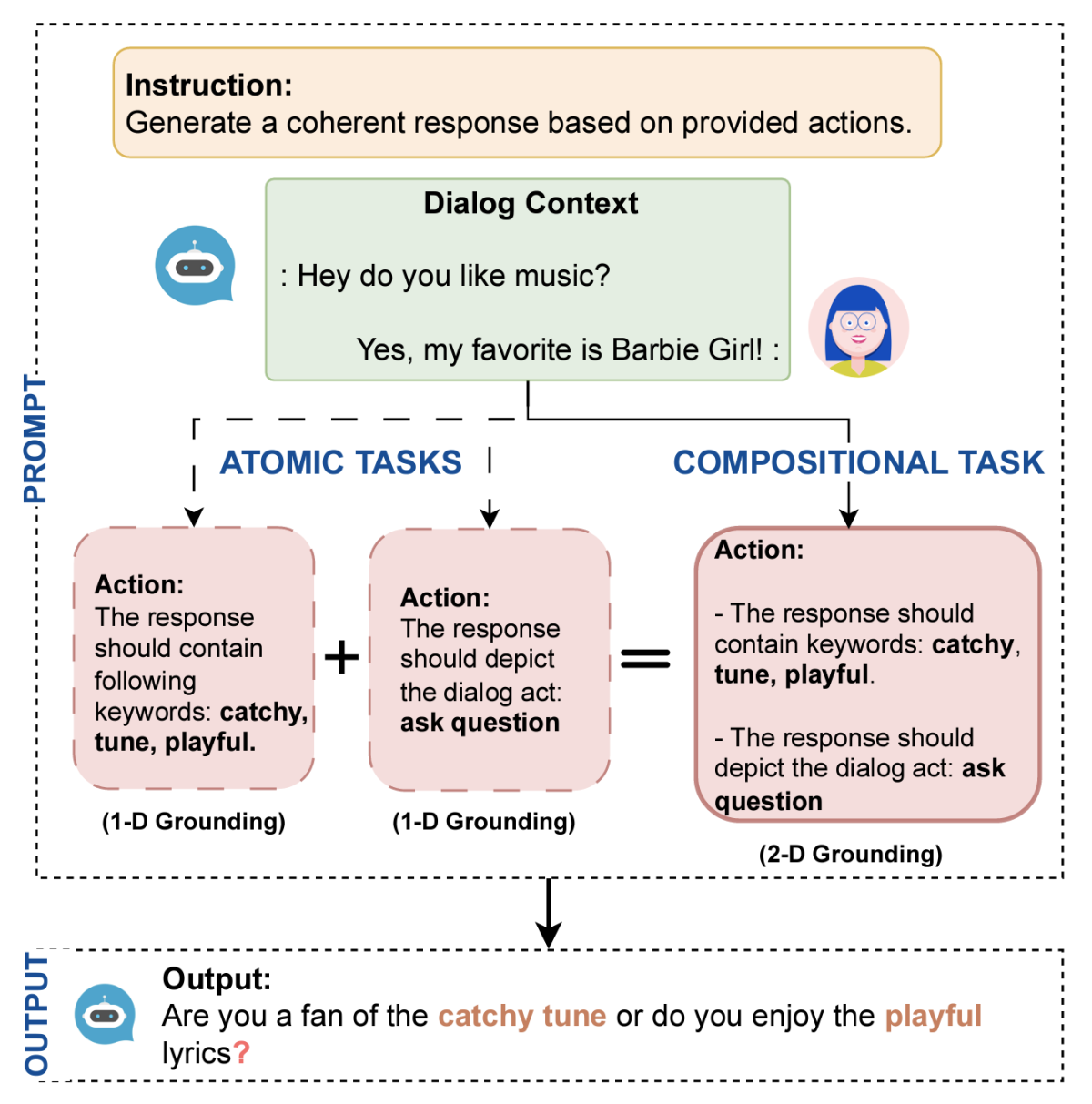
Instruction tuning
CESAR: Automatic induction of compositional instructions for multi-turn dialogs
Taha Aksu, Devamanyu Hazarika, Shikib Mehri, Seokhwan Kim, Dilek Hakkani-Tür, Yang Liu, Mahdi Namazifar
LLM hallucination
INVITE: A testbed of automatically generated invalid questions to evaluate large language models for hallucinations
Anil Ramakrishna, Rahul Gupta, Jens Lehmann, Morteza Ziyadi
Machine learning
Efficient long-range transformers: You need to attend more, but not necessarily at every layer
Qingru Zhang, Dhananjay Ram, Cole Hawkins, Sheng Zha, Tuo Zhao
Natural-language processing
NameGuess: Column name expansion for tabular data
Jiani Zhang, Zhengyuan Shen, Balasubramaniam Srinivasan, Shen Wang, Huzefa Rangwala, George Karypis
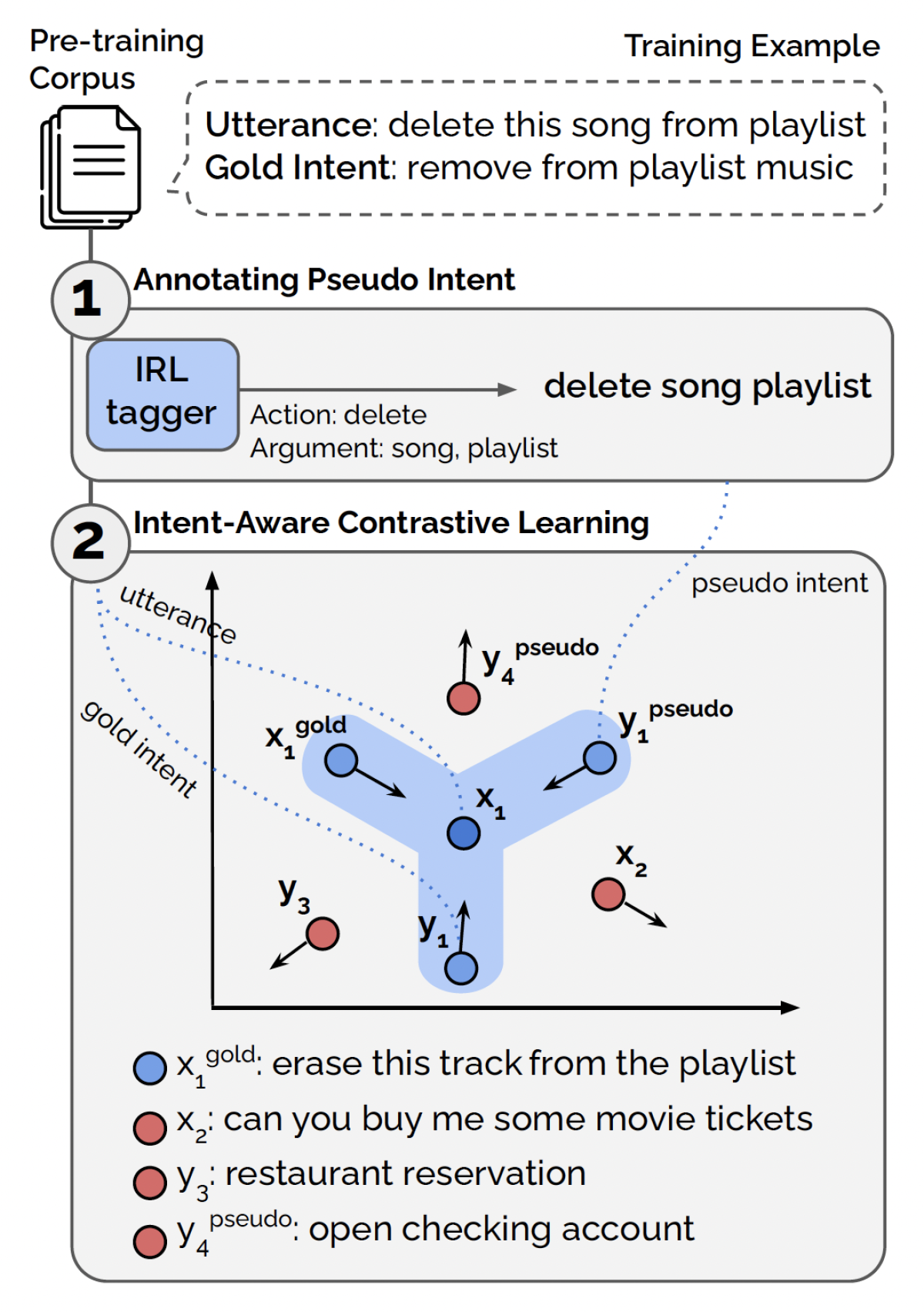
Natural-language understanding
Adversarial robustness for large-language NER models using disentanglement and word attributions
Xiaomeng Jin, Bhanu Vinzamuri, Sriram Venkatapathy, Heng Ji, Pradeep Natarajan
Measuring and mitigating dialog-to-API constraint violations of in-context learning
Shufan Wang, Sebastien Jean, Sailik Sengupta, James Gung, Nikolaos Pappas, Yi Zhang
MultiCoNER v2: A large multilingual dataset for fine-grained and noisy named entity recognition
Besnik Fetahu, Zhiyu Chen, Sudipta Kar, Oleg Rokhlenko, Shervin Malmasi
Pre-training intent-aware encoders for zero- and few-shot intent classification
Mujeen Sung, James Gung, Elman Mansimov, Nikolaos Pappas, Raphael Shu, Salvatore Romeo, Yi Zhang, Vittorio Castelli
Personalization
Personalized dense retrieval on global index for voice-enabled conversational systems
Masha Belyi, Charlotte Dzialo, Chaitanya Dwivedi, Prajit Reddy Muppidi, Kanna Shimizu
Retrieve and copy: Scaling ASR personalization to large catalogs
Sai Muralidhar Jayanthi, Devang Kulshreshtha, Saket Dingliwal, Srikanth Ronanki, Sravan Bodapati
Query reformulation
CL-QR: Cross-lingual enhanced query reformulation for multi-lingual conversational AI agents
Zhongkai Sun, Zhengyang Zhao, Sixing Lu, Chengyuan Ma, Xiaohu Liu, Xing Fan, Wei (Sawyer) Shen, Chenlei (Edward) Guo
Graph meets LLM: A novel approach to collaborative filtering for robust conversational understanding
Zheng Chen, Ziyan Jiang, Fan Yang, Eunah Cho, Xing Fan, Xiaojiang Huang, Yanbin Lu, Aram Galstyan
Improving contextual query rewrite for conversational AI agents through user-preference feedback learning
Zhongkai Sun, Yingxue Zhou, Jie Hao, Xing Fan, Yanbin Lu, Chengyuan Ma, Wei (Sawyer) Shen, Chenlei (Edward) Guo
Question-answer databases
Protege: Prompt-based diverse question generation from web articles
Vinayak Puranik, Anirban Majumder, Vineet Chaoji
QUADRo: Dataset and models for question-answer database retrieval
Stefano Campese, Ivano Lauriola, Alessandro Moschitti
Question answering
Strong and efficient baselines for open domain conversational question answering
Andrei C. Coman, Gianni Barlacchi, Adrià de Gispert
Tokenization consistency matters for generative models on extractive NLP tasks
Kaiser Sun, Peng Qi, Yuhao Zhang, Lan Liu, William Yang Wang, Zhiheng Huang
Too much of product information: Don’t worry, let’s look for evidence!
Aryan Jain, Jitenkumar Rana, Chetan Aggarwal
Reasoning
Plan, verify and switch: Integrated reasoning with diverse x-of-thoughts
Tengxiao Liu, Qipeng Guo, Yuqing Yang, Xiangkun Hu, Yue Zhang, Xipeng Qiu, Zheng Zhang

Responsible AI
Geographical erasure in language generation
Pola Schwöbel, Jacek Golebiowski, Michele Donini, Cédric Archambeau, Danish Pruthi
Speech translation
End-to-end single-channel speaker-turn aware conversational speech translation
Juan Pablo Zuluaga Gomez, Zhaocheng Huang, Xing Niu, Rohit Paturi, Sundararajan Srinivasan, Prashant Mathur, Brian Thompson, Marcello Federico
Text summarization
Enhancing abstractiveness of summarization models through calibrated distillation
Hwanjun Song, Igor Shalyminov, Hang Su, Siffi Singh, Kaisheng Yao, Saab Mansour
Generating summaries with controllable readability levels
Leonardo Ribeiro, Mohit Bansal, Markus Dreyer
Improving consistency for text summarization with energy functions
Qi Zeng, Qingyu Yin, Zheng Li, Yifan Gao, Sreyashi Nag, Zhengyang Wang, Bing Yin, Heng Ji, Chao Zhang
InstructPTS: Instruction-tuning LLMs for product title summarization
Besnik Fetahu, Zhiyu Chen, Oleg Rokhlenko, Shervin Malmasi
Multi document summarization evaluation in the presence of damaging content
Avshalom Manevich, David Carmel, Nachshon Cohen, Elad Kravi, Ori Shapira
Re-examining summarization evaluation across multiple quality criteria
Ori Ernst, Ori Shapira, Ido Dagan, Ran Levy
Topic modeling
DeTiME: Diffusion-enhanced topic modeling using encoder-decoder based LLM
Weijie Xu, Wenxiang Hu, Fanyou Wu, Srinivasan Sengamedu, "SHS"



