
Amazon's papers at Interspeech 2023, sorted by research topic.
Automatic speech recognition
A metric-driven approach to conformer layer pruning for efficient ASR inference
Dhanush Bekal, Karthik Gopalakrishnan, Karel Mundnich, Srikanth Ronanki, Sravan Bodapati, Katrin Kirchhoff
Conmer: Streaming Conformer without self-attention for interactive voice assistants
Martin Radfar, Paulina Lyskawa, Brandon Trujillo, Yi Xie, Kai Zhen, Jahn Heymann, Denis Filimonov, Grant Strimel, Nathan Susanj, Athanasios Mouchtaris
DCTX-Conformer: Dynamic context carry-over for low latency unified streaming and non-streaming Conformer
Goeric Huybrechts, Srikanth Ronanki, Xilai Li, Hadis Nosrati, Sravan Bodapati, Katrin Kirchhoff
Distillation strategies for discriminative speech recognition rescoring
Prashanth Gurunath Shivakumar, Jari Kolehmainen, Yi Gu, Ankur Gandhe, Ariya Rastrow, Ivan Bulyko
Effective training of attention-based contextual biasing adapters with synthetic audio for personalised ASR
Burin Naowarat, Philip Harding, Pasquale D'Alterio, Sibo Tong, Bashar Awwad Shiekh Hasan
Human transcription quality improvement
Jian Gao, Hanbo Sun, Cheng Cao, Zheng Du

Learning when to trust which teacher for weakly supervised ASR
Aakriti Agrawal, Milind Rao, Anit Kumar Sahu, Gopinath (Nath) Chennupati, Andreas Stolcke
Model-internal slot-triggered biasing for domain expansion in neural transducer ASR models
Edie Lu, Philip Harding, Kanthashree Mysore Sathyendra, Sibo Tong, Xuandi Fu, Jing Liu, Feng-Ju (Claire) Chang, Simon Wiesler, Grant Strimel
Multi-view frequency-attention alternative to CNN frontends for automatic speech recognition
Belen Alastruey Lasheras, Lukas Drude, Jahn Heymann, Simon Wiesler
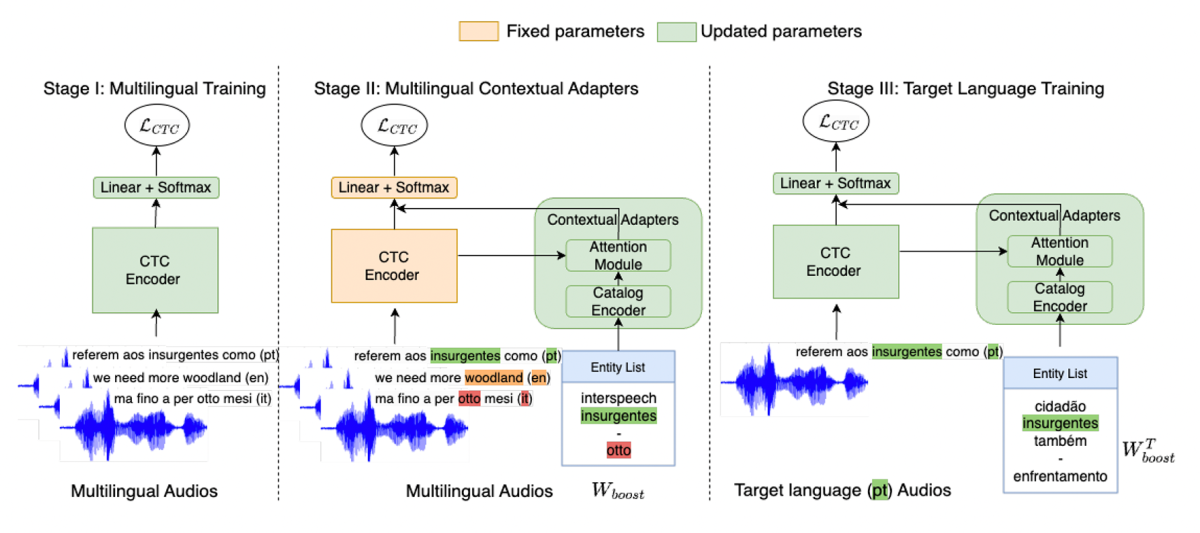
Multilingual contextual adapters to improve custom word recognition in low-resource languages
Devang Kulshreshtha, Saket Dingliwal, Brady Houston, Sravan Bodapati
PATCorrect: Non-autoregressive phoneme-augmented transformer for ASR error correction
Ziji Zhang, Zhehui Wang, Raj Kamma, Sharanya Eswaran, Narayanan Sadagopan
Personalization for BERT-based discriminative speech recognition rescoring
Jari Kolehmainen, Yi Gu, Aditya Gourav, Prashanth Gurunath Shivakumar, Ankur Gandhe, Ariya Rastrow, Ivan Bulyko
Personalized predictive ASR for latency reduction in voice assistants
Andreas Schwarz, Di He, Maarten Van Segbroeck, Mohammed Hethnawi, Ariya Rastrow
Record deduplication for entity distribution modeling in ASR transcripts
Tianyu Huang, Chung Hoon Hong, Carl Wivagg, Kanna Shimizu
Scaling laws for discriminative speech recognition rescoring models
Yi Gu, Prashanth Gurunath Shivakumar, Jari Kolehmainen, Ankur Gandhe, Ariya Rastrow, Ivan Bulyko
Selective biasing with trie-based contextual adapters for personalised speech recognition using neural transducers
Philip Harding, Sibo Tong, Simon Wiesler
Streaming speech-to-confusion network speech recognition
Denis Filimonov, Prabhat Pandey, Ariya Rastrow, Ankur Gandhe, Andreas Stolcke
Data representation
Don’t stop self-supervision: Accent adaptation of speech representations via residual adapters
Anshu Bhatia, Sanchit Sinha, Saket Dingliwal, Karthik Gopalakrishnan, Sravan Bodapati, Katrin Kirchhoff
Dialogue management
Parameter-efficient low-resource dialogue state tracking by prompt tuning
Mingyu Derek Ma, Jiun-Yu Kao, Shuyang Gao, Arpit Gupta, Di Jin, Tagyoung Chung, Violet Peng
Grapheme-to-phoneme conversion
Improving grapheme-to-phoneme conversion by learning pronunciations from speech recordings
Sam Ribeiro, Giulia Comini, Jaime Lorenzo Trueba
Keyword spotting
On-device constrained self-supervised speech representation learning for keyword spotting via knowledge distillation
Gene-Ping Yang, Yue Gu, Qingming Tang, Dongsu Du, Yuzong Liu
Natural-language understanding
Quantization-aware and tensor-compressed training of transformers for natural language understanding
Zi Yang, Samridhi Choudhary, Siegfried Kunzmann, Zheng Zhang
Sampling bias in NLU models: Impact and mitigation
Zefei Li, Anil Ramakrishna, Anna Rumshisky, Andy Rosenbaum, Saleh Soltan, Rahul Gupta
Understanding disrupted sentences using underspecified abstract meaning representation
Angus Addlesee, Marco Damonte
Paralinguistics
Towards paralinguistic-only speech representations for end-to-end speech emotion recognition
George Ioannides, Michael Owen, Andrew Fletcher, Viktor Rozgic, Chao Wang
Utility-preserving privacy-enabled Speech embeddings for emotion detection
Chandrashekhar Lavania, Sanjiv Das, Xin Huang, Kyu Han
Question answering
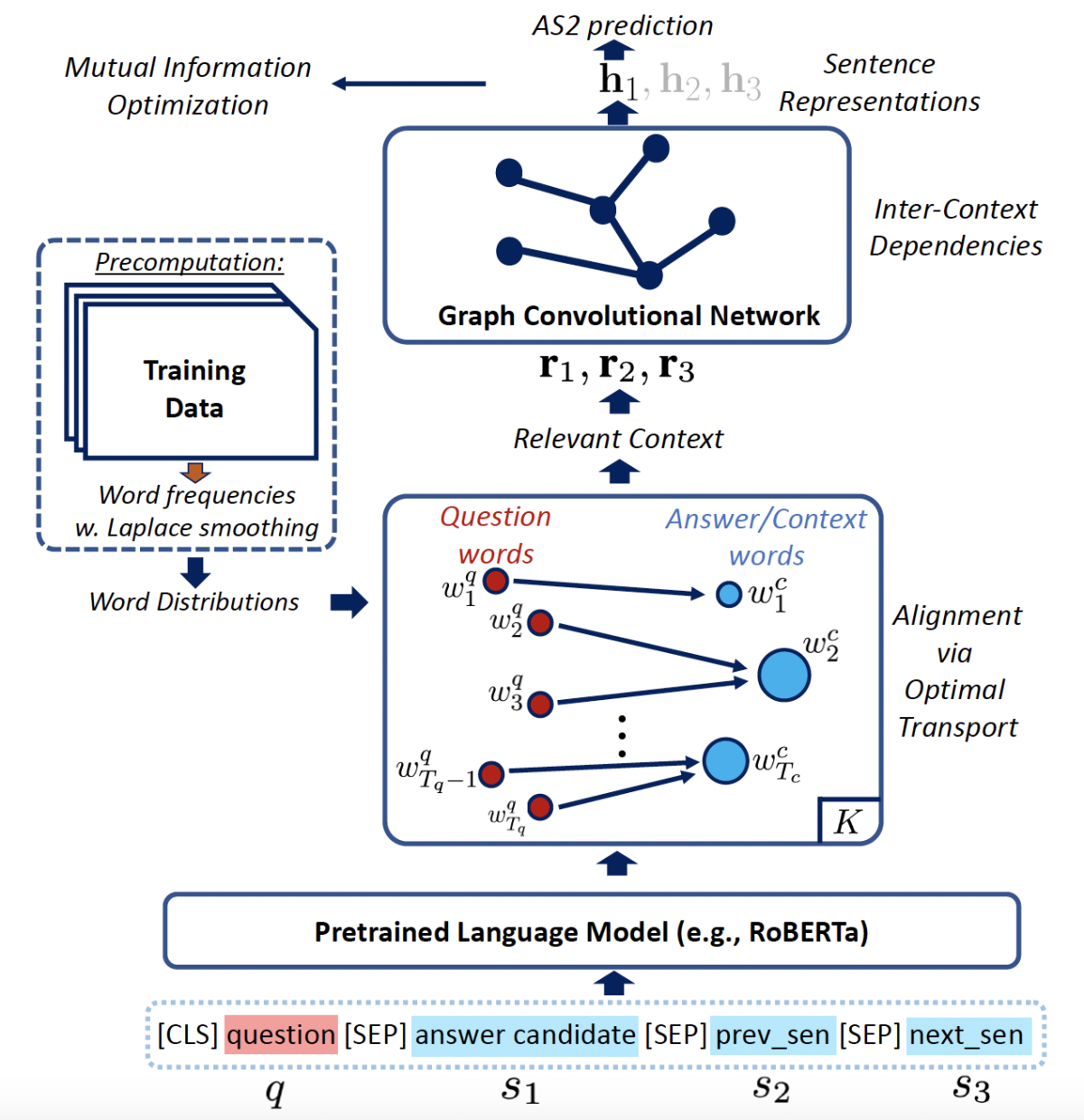
Question-context alignment and answer-context dependencies for effective answer sentence selection
Minh Van Nguyen, Kishan K C, Toan Nguyen, Thien Nguyen, Ankit Chadha, Thuy Vu
Speaker diarization
Lexical speaker error correction: Leveraging language models for speaker diarization error correction
Rohit Paturi, Sundararajan Srinivasan, Xiang Li
Speech translation
Knowledge distillation on joint task end-to-end speech translation
Khandokar Md. Nayem, Ran Xue, Ching-Yun (Frannie) Chang, Akshaya Vishnu Kudlu Shanbhogue
Text-to-speech
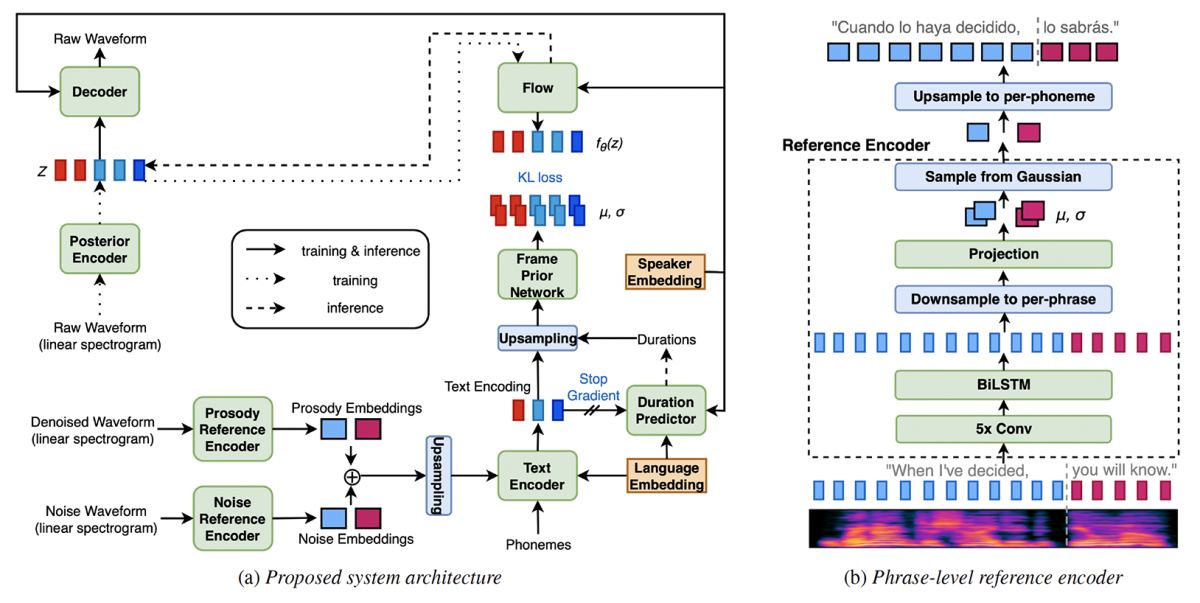
Comparing normalizing flows and diffusion models for prosody and acoustic modelling in text-to-speech
Guangyang Zhang, Tom Merritt, Sam Ribeiro, Biel Tura Vecino, Kayoko Yanagisawa, Kamil Pokora, Abdelhamid Ezzerg, Sebastian Cygert, Ammar Abbas, Piotr Bilinski, Roberto Barra-Chicote, Daniel Korzekwa, Jaime Lorenzo Trueba
Cross-lingual prosody transfer for expressive machine dubbing
Jakub Swiatkowski, Duo Wang, Mikolaj Babianski, Patrick Tobing, Ravi chander Vipperla, Vincent Pollet
Diffusion-based accent modelling in speech synthesis
Kamil Deja, Georgi Tinchev, Marta Czarnowska, Marius Cotescu, Jasha Droppo
eCat: An end-to-end model for multi-speaker TTS & many-to-many fine-grained prosody transfer
Ammar Abbas, Sri Karlapati, Bastian Schnell, Penny Karanasou, Marcel Granero Moya, Amith Nagaraj, Ayman Boustati, Nicole Peinelt, Alexis Moinet, Thomas Drugman
Expressive machine dubbing through phrase-level cross-lingual prosody transfer
Jakub Swiatkowski, Duo Wang, Mikolaj Babianski, Giuseppe Coccia, Patrick Tobing, Ravi chander Vipperla, Viacheslav Klimkov, Vincent Pollet
Multilingual context-based pronunciation learning for text-to-speech
Giulia Comini, Sam Ribeiro, Fan Yang, Heereen Shim, Jaime Lorenzo Trueba



