
Singing synthesis — the use of computer models to synthesize a human singing voice — has been studied since the 1950s. Like the related field of text-to-speech (TTS), it initially revolved around two paradigms: statistical parametric synthesis, which uses statistical models to reproduce features of the voice, and unit selection, in which snippets of vocal recordings are recombined on the fly.
Recently, TTS has shifted toward neural text-to-speech (NTTS), or models based on deep neural networks, which increase the perceived quality of the generated speech. An important class of NTTS models, called attention-based sequence-to-sequence (AS2S), has become the industry standard.
In a paper at this year's Interspeech, we are presenting a singing synthesis model called UTACO, which was built using AS2S. To our knowledge, we were the first to do this, in the fall of 2019, although several successful AS2S architectures have been introduced in the singing synthesis field since then.

UTACO is simpler than previous models: it doesn’t depend on sub-models that separately generate input features such as vibrato and note and phoneme durations; instead, it simply takes notated music — with lyrics — as input. It also autonomously sings in tune, which is not true of all neural models.
Most important, UTACO achieves a high level of naturalness. In our paper, we compare it to the most recent fully neural model in the literature, which obtained a naturalness score of 31 out of 100 in a test using the MUSHRA (multiple stimuli with hidden reference and anchor) methodology. UTACO’s score was 60, while the training examples of humans singing got an 82.
Finally, because AS2S models are a very active field of research, UTACO can naturally take advantage of many improvements and extensions already reported in the literature.
Simplifying singing synthesis
When we began investigating singing synthesis, we noticed a stark contrast between it and NTTS. Singing synthesis models seemed to be conceptually more complex. Most singing models required a number of different inputs, such as the pitch pattern of the singing voice over time (called F0) or almost imperceptible errors whose absence makes the singing sound unnatural. Producing each of these inputs required a separate sub-model.
The only input required by an AS2S TTS model, by contrast, is a sequence of phonemes, the individual sounds from which any spoken word is made. Before AS2S, speech models also required specification of a number of other features, such as speed, rhythm, and intonation (collectively called prosody). AS2S models learn all of this on their own, from training examples.
We wondered whether an AS2S model could learn everything necessary to synthesize a singing voice, too. A trained human can sing a song just by reading a score, so we built a simple AS2S speech architecture and fed it only the information contained in the score, showing it corresponding examples of how that score should be sung. To the best of our knowledge, we were the first to do this, in the fall of 2019, although several successful AS2S architectures have been introduced in the singing synthesis field since then.
Measurable advances
In our paper, we compare UTACO to WGANSing, which was at the time of submission the most recent fully neural singing synthesis model in the literature. In our MUSHRA test, 40 listeners were asked to compare three versions of the same short song clip and score them from 0 to 100 in terms of perceived “naturalness”. The versions are
- the audio produced by UTACO;
- the audio produced by WGANSing;
- the recording of the human voice used to train the model.
The listeners do not know which is which, so they are not biased. The results appear below. The mean differences in score are statistically significant (the p-value of all paired t-tests is below 10-16).
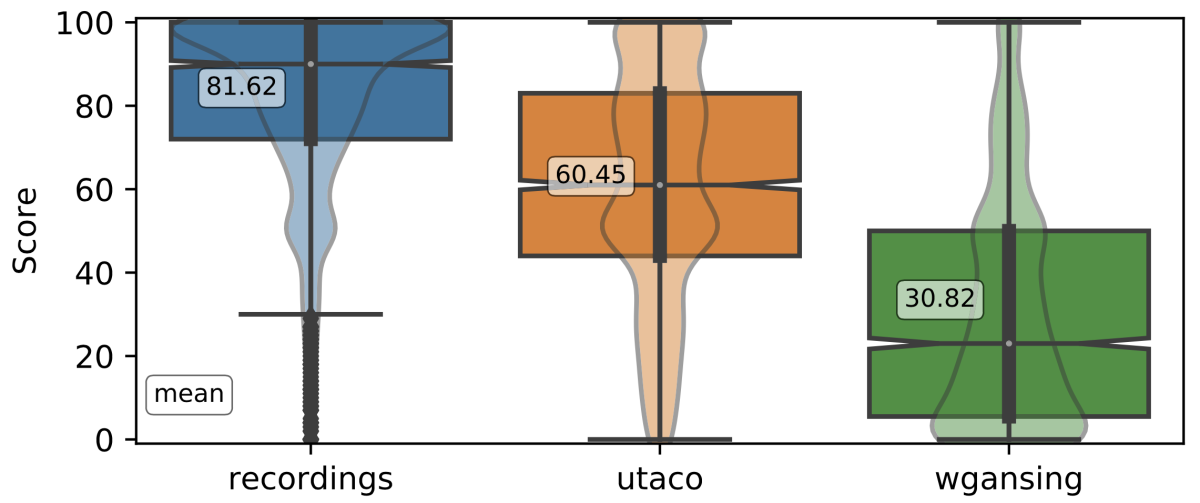
We take WGANSing as representative of the state of the art in neural singing synthesis circa fall 2019. WGANSing has a different architecture (it’s not based on AS2S), and at synthesis time, it needs to be fed the pitch pattern and the duration of each phoneme, which are extracted from the original recording. UTACO generates all of these features on its own.
One interesting result is that UTACO is capable of reproducing a good vibrato autonomously, even “deciding” where to apply it: in the sample input below, note that there is no vibrato indication. Before UTACO, researchers created whole sub-models devoted to representing vibrato.
UTACO is a jump forward for singing synthesis, but it does have its drawbacks. For example, rests in a score can sometimes cause it to break down (a known problem in AS2S architectures). And its timing is not quite perfect, something that a musician can detect instantly.
AS2S architectures, however, are being intensely researched in the text-to-speech field, and many of the resulting innovations may be directly applicable to our model.
Model architecture
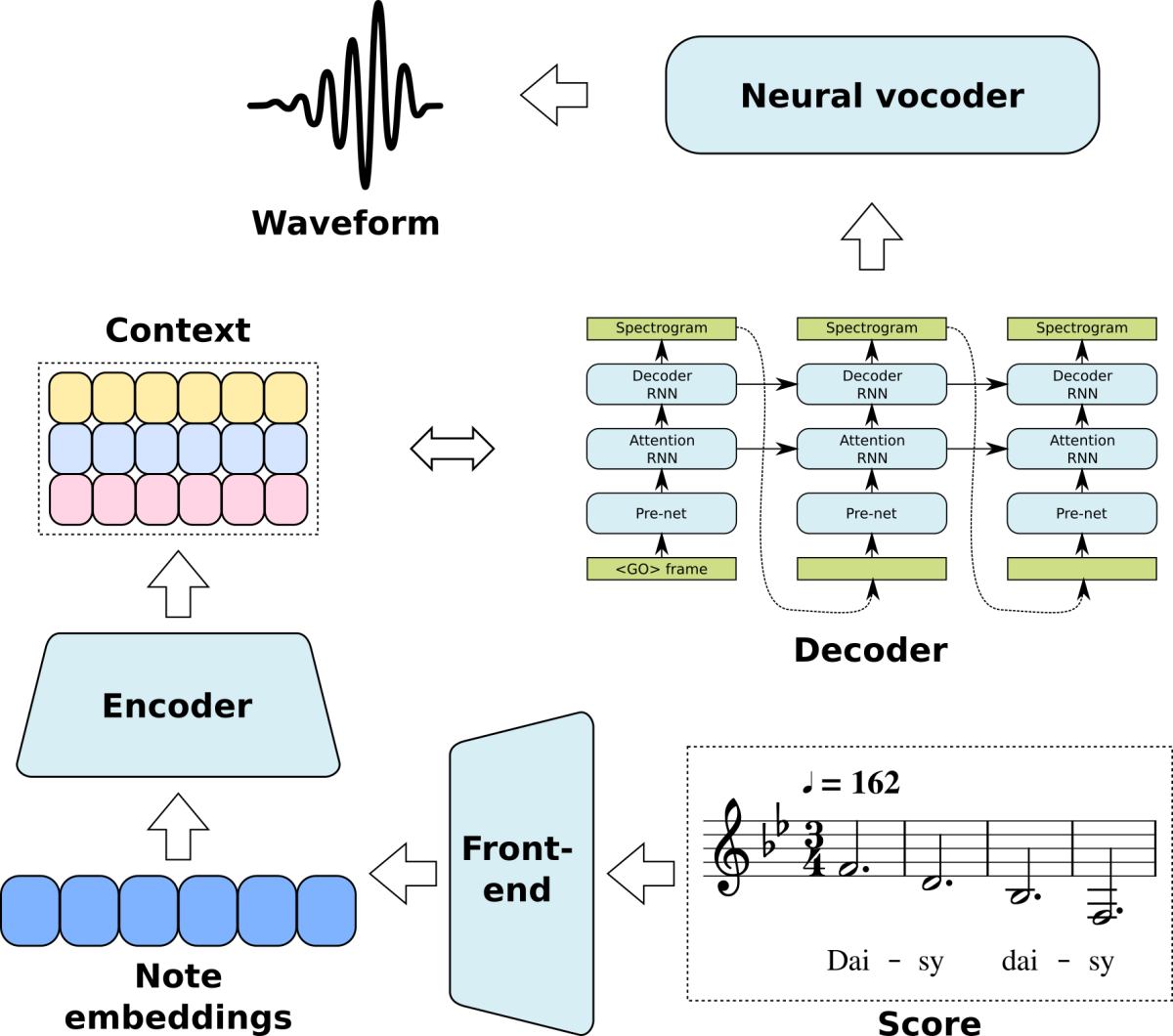
In more detail, to turn a score into the input for UTACO, we use a representation we call note embeddings. We take a score (in MusicXML format) and perform linguistic analysis on the lyrics to figure out which phonemes must be pronounced on each note.
The sequence of phonemes is what a text-to-speech model would normally see as input. But to each phoneme, we add information about the note that contains it: octave (pitch range), step (which of the 12 notes in the pitch range it is), and duration in seconds. We also add a “progress” stream, which is 1 at the beginning of a note and 0 at the end, so UTACO knows where notes begin and end. (See illustration, above.)
As in a typical NTTS system, the model produces a spectrogram, which is turned into a waveform by a neural vocoder based on dilated causal convolutions.
We are pleased with the results of our experiments with UTACO. But this is just the beginning of a major change in the field of singing synthesis that will enhance its capabilities in ways that were unthinkable until just a few years ago.



