
The Association for the Advancement of Artificial Intelligence’s annual Conference on Artificial Intelligence (AAAI) received around 9,000 paper submissions this year, which required a proportionally large program committee, with two program chairs and four associate program chairs.

One of the associate program chairs is Kai-Wei Chang, an associate professor of computer science at the University of California, Los Angeles, and an Amazon Visiting Academic in the Alexa AI organization. This year, Chang was also named a senior member of the Association for the Advancement of Artificial Intelligence — and he chairs the AAAI conference’s best-paper committee. So he has an unusually good vantage point on trends in this year’s AAAI submissions.
With more than 1,600 accepted papers, the AAAI program naturally spans a huge range of topics. “There are papers from all different areas — computer vision, natural-language processing, neural networks,” Chang says. “Roboticists have a large portion of the conference, and there are papers in traditional areas, like searching and planning.”
Still, Chang says, two topics stand out to him: prompt engineering and reasoning.
Prompt engineering
“Prompt engineering” refers to efforts to extract accurate, consistent, and fair outputs from large generative models, such text-to-image synthesizers or large language models (LLMs). LLMs are trained on large-scale bodies of text, so they encode a great deal of factual information about the world. But they’re trained to produce sequences of words that are probable in the general case — not accurate in the particular case.
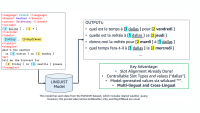
“For example, I asked a model to generate a bio sketch of me, and it actually generated something that’s pretty good,” Chang says. “Maybe the model was trained on my home page, but it said I'm a professor at UCLA and that I'm doing NLP research and submit papers to conferences like ACL, which is all true. But it also gave some random facts — for example, that I won a certain award, which I didn't.
“It's important for these models to have some kind of fact checker to filter out content that is inappropriate. There are several AAAI papers on how to ensure that the generated texts are personalized, reliable, and consistent.”
At Amazon, one of the topics that Chang researches is LLMs’ fairness. Again, because LLMs’ output is based on statistical averages, it can reinforce stereotypes prevalent in the models’ training data. For instance, if an LLM receives an input (a prompt) that mentions a doctor, it may default to using male pronouns to refer to that doctor in its generated output.
“Similar observations happen in text-to-image generation,” Chang adds. “If you ask the model to generate a doctor, it is likely to generate a male doctor. We find that you can correct this by giving a description together with the prompt — like ‘all individuals can be lawyers irrespective of their gender and skin tone.’ Alternatively, you can improve the diversity of generation by adding in more diverse training data.”
Reasoning
Reasoning involves drawing inferences about the logical relationships between entities or concepts in order to execute tasks that are more complicated than the type of classification that machine learning models currently excel at. Many researchers believe that this will necessarily involve symbolic reasoning — an approach to AI that, for years, machine learning appeared to supersede.

“You can define a loss function or a layer of a neural network called a semantic probabilistic layer to enable the model to learn to use symbolic knowledge for reasoning,” Chang explains. “For example, you can define some rules and define a loss based on how likely the model’s prediction is to violate those rules. Then you can train the model by minimizing the loss to avoid violations of the rules.”
“For example, for language generation, you can say, ‘I want to generate a sentence, and it must contain certain concepts or certain words’ — or the other way around, that it cannot contain any bad words. The constraints can be also ‘soft’. For example, if you are doing robotic planning, then you can have a constraint that says the robot should not go into a certain area unless necessary. So it's not that the robot cannot enter the region, but the model is trained to avoid it.”
Indeed, Chang, says, he has also been working on just such an approach, in which a second, ancillary network helps guide the primary model toward outputs that meet a set of constraints.
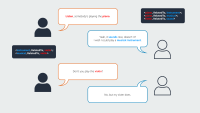
“You can train an ancillary neural network to help you decompose complicated constraints into smaller pieces, so it's easier to incorporate into the model,” Chang explains. “So in the language generation example, say you want to generate a story that must contain certain user-defined words, but also the sentiment of the story should be positive. Those constraints are hard to incorporate into text generation, as the generated output has to be coherent, and the model might not know where to insert these words and keep the sentiment positive. The neural network can learn to decompose those rules into token-level constraints and produce the corresponding probabilities to guide the primary model.”
Chang emphasizes, however, that while prompt engineering and reasoning are popular topics at this year’s AAAI, they still account for only a small fraction of the conference’s program. “AI is very popular nowadays,” he says. “There are several subareas, like machine learning, computer vision, NLP, and robotics. And there are quite diverse submissions from all these different fields.”



