
As they are everywhere, large language models are a major topic of conversation at this year’s meeting of the Association for Computational Linguistics (ACL).

“We have multiple sessions on large language models, which was not a session at past conferences,” says Yang Liu, a senior principal scientist with Alexa AI and general chair of ACL. “And both keynote talks are related to this topic.”
According to the ACL website, one of the keynote speakers, Geoffrey Hinton, who won a share of the 2018 Turing Award for seminal contributions to deep learning, will address “the contentious issue of whether current multimodal LLMs have subjective experience.” The other keynote speaker, Alison Gopnik, a professor of psychology and philosophy at the University of California, Berkeley, has titled her talk “Large Language Models as Cultural Technologies”.
“We also have a panel on large language models, and there's another session on ethics and NLP [natural-language processing] as these models are becoming more and more powerful,” Liu adds. “These are the issues the entire community is paying attention to. And not just our community: the whole world is looking at the development of these technologies and their relevance to society.”
Hallucination
One of the major problems with large language models (LLMs), of course, is their tendency to “hallucinate”, or generate assertions that sound plausible but are in fact false. Currently, Liu says, NLP researchers are attempting to address this problem in several ways. One is through a post-processing step that attempts to verify the LLMs’ outputs.
“Once you have the system response, you can do knowledge retrieval,” Liu explains. “‘Can you find a source for this?’ When a model says that Joe Biden is the current president, you can easily search and find some credible source for that. And then between that source and your current system response, there are these fact-checking models, similar to entailment models, and you can check the consistency.”
Currently, however, “the error rate is pretty high,” Liu says. “Even if I give you two texts, A and B, and I ask you, ‘Do they mean the same thing?’, it's not a solved problem in NLP.”
Another approach, Liu says, is to more carefully curate the data used to train LLMs. “They are trained with trillions of tokens,” she says — where a “token” is a word, multiword term treated as a unit, or subword unit. “If you want to control the information provided to these models, the first step is to make sure the data is high-quality data.”
Researchers are also trying to modify the inner workings of trained LLMs in order to steer their outputs toward factually accurate assertions. An LLM works by computing the probability of the next token in a sequence of tokens; the LLM’s attention heads — perhaps dozens of them per network layer — determine how heavily the model should weight each past token when computing the probability of the next token.

“One line of work that aims to improve factual accuracy is by activation editing, which changes such probability distributions,” Liu explains. “These methods do not change the trained models but use different strategies to change inference or prediction results. For example, a recent paper on this topic first identifies a sparse set of attention heads that are highly correlated with truthfulness. Then they perform ‘inference intervention’: they shift activations along these truth-correlated directions. There are also various methods that change model parameters to reduce hallucination.”
“Explicit knowledge grounding can also be used to address hallucination,” she adds. “In these approaches, a knowledge retrieval component is first applied. Then the LLM grounds its response in the relevant documents.”
Training by proxy
One difficulty in preventing hallucination has to do with the way LLMs are trained, Liu explains. LLM training uses input masking, in which words in input sentences are randomly removed, and the LLM has to supply them. The masking is done automatically, and the output error is straightforward to compute. But explicitly training the models for factual accuracy would complicate the picture.
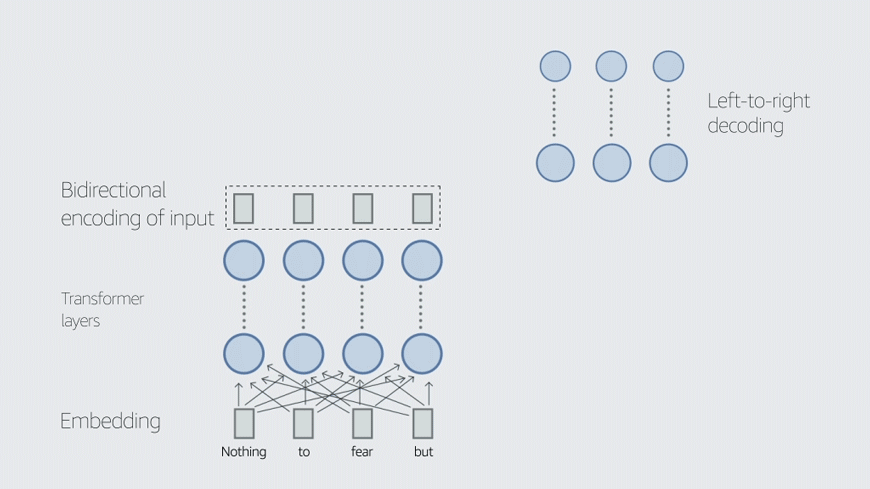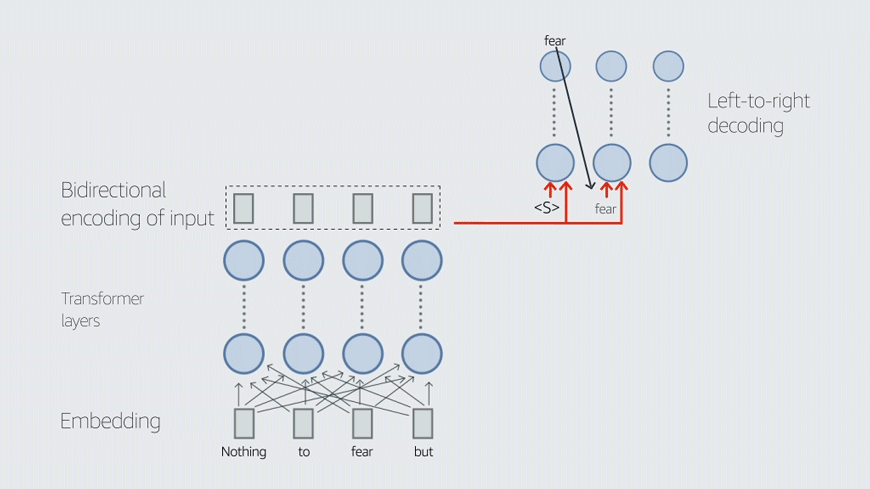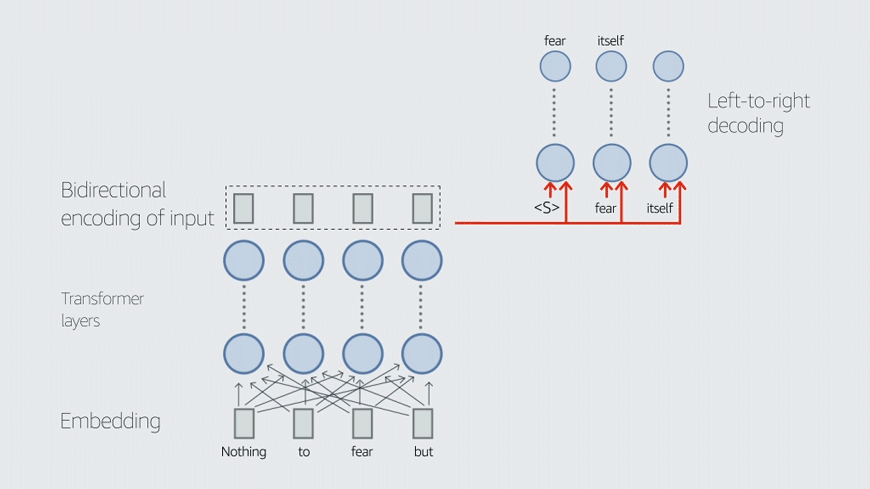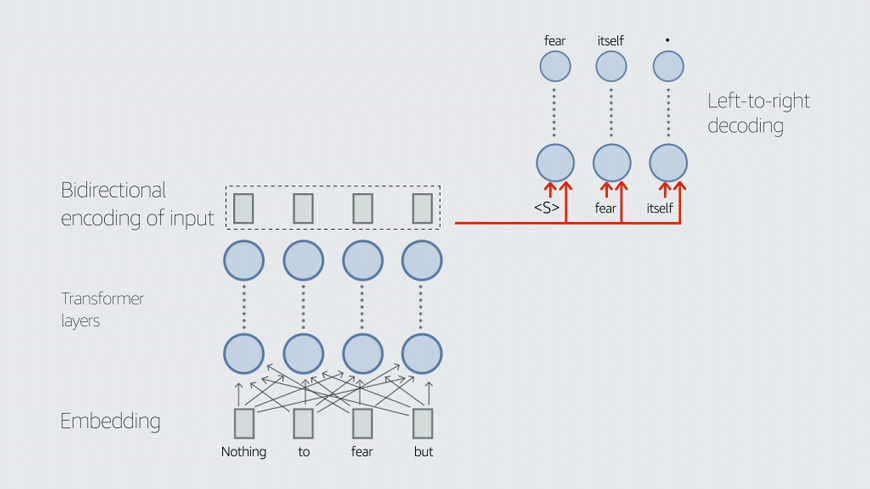
“What people have found is that predicting tokens is a good proxy for many downstream use cases,” Liu says. “That builds the basic foundation model, and then on top of it, you can try to improve it to make it follow instructions and perform various tasks. But changing that foundation model, adding some additional training loss objective, that's hard, and computationally expensive.”
“I think it makes sense to continuously improve these models after pretraining — for example, via the reward model with human feedback in the loop,” Liu adds. Reinforcement learning with human feedback is a popular method for improving the performance of LLMs, in which, during training, the model seeks human feedback to distinguish between choices to which it assigns low probabilities.
“If factual error is something you care about, you can have models optimize toward those dimensions,” Liu says. “I think the model performance along these dimensions is improving; it's just that the acceptance criterion is very high. Say, 95% — that seems very accurate from the classification point of view. But in search, if you have one single error and then people say, ‘Oh no, you're giving incorrect answers!’, it’s a problem.”

One possibility, Liu says, is that as researchers find ways to incrementally improve the factual accuracy of LLMs, the public gets better educated about how to use them.
“Maybe users will change their attitudes, and companies will also change,” she says. “People play with LLMs, they see some errors, and people do their own fact checking. You treat them just like any online news source. This is related to our panel on ethics: the entire society is looking at this new tool. How should we be treating these things? Do we take it as ground truth, or is it a tool that provides you something, and you double-check it? I think people are trying to understand these things and then live with them in harmony.”



