
As Alexa expands into new countries, she usually has to be trained on new languages. But sometimes, she has to be re-trained on languages she’s already learned. British English, American English, and Indian English, for instance, are different enough that for each of them, we trained a new machine learning model from scratch.
Ideally, we wouldn’t have to do that. When Alexa moves into a new country and encounters a language she’s already familiar with, she should be able to take advantage of her previous experience. That’s the idea behind a new machine learning system that my colleagues and I presented last week at the annual meeting of the North American Chapter of the Association for Computational Linguistics.
Our system is a domain classifier, which determines the topic of a customer’s request, such as music, weather, or sports. It can also identify requests as “out of domain”, which is important to prevent the mishandling of unintentional or garbled speech.
The domain classifier is a multi-task model, which means that it’s trained to perform several tasks simultaneously. One of those tasks is to learn a general statistical model for a particular language, which captures consistencies across regions. Its other tasks are to learn several different locale-specific models for the same language. It bases its domain classifications on the outputs of both the general and the locale-specific models.
In experiments in which we trained our model on four different variants of English, it showed accuracy improvements of 18%, 43%, 116%, and 57% versus models trained on each variant individually.
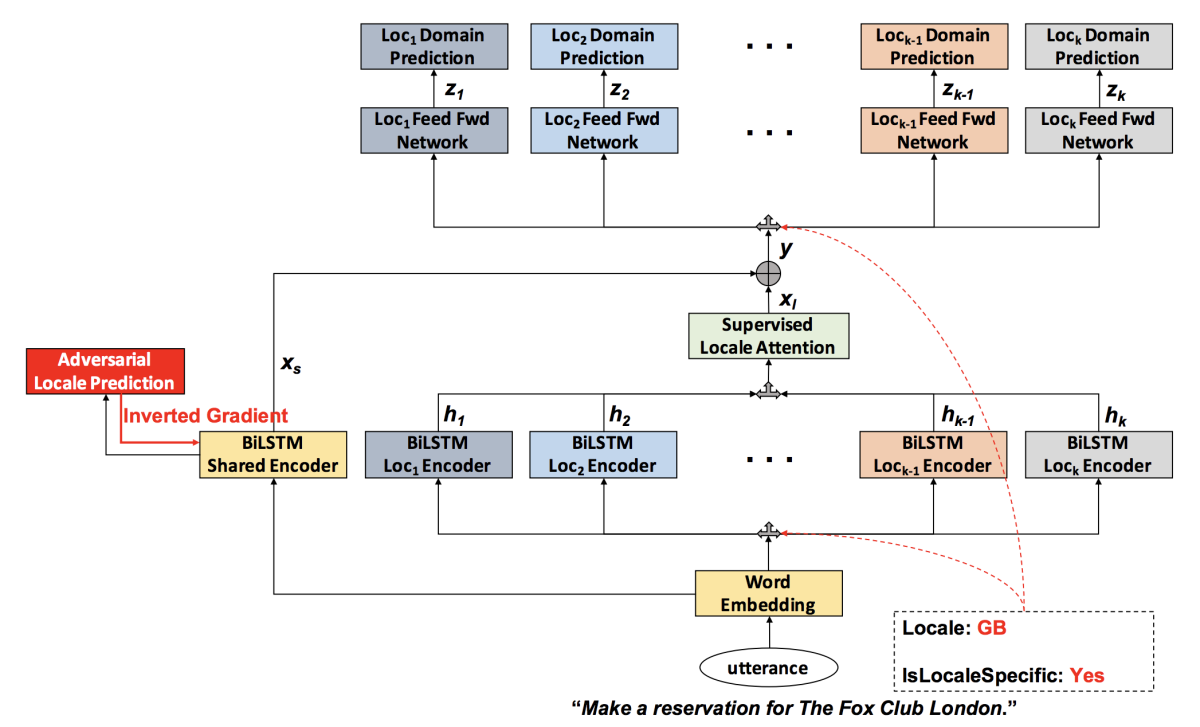
One reason multi-task training for domain classification is challenging is that requests to the same domain could look wildly different in different locales. Requests to the restaurant domain, for instance, would feature much different restaurant names in Mumbai than they would in London, even though customers are requesting the same services — address information, menu information, reservations, and so on.
In such cases, relying on a single locale-specific classifier, trained on data unique to that locale, would probably yield better results than pooling the outputs of several locale-specific classifiers. In other cases, however, where requests are more uniform across locales, the outputs of several different locale-specific models could reinforce each other, improving accuracy.
To strike a balance between these two types of cases, we use an attention mechanism, which gives different emphases — or weights — to the outputs of different locale-specific models, depending on the input. Ideally, in cases like the restaurant example, in which input data is very locale-dependent, the attention mechanism would assign almost of all of its weight to a single locale-specific model, ignoring the outputs of the other locale-specific models.
In advance, we can identify domains that should receive this kind of treatment, because their input data is highly locale dependent. But at run time, our system doesn’t know which domain a request is intended for. Answering that question is precisely what it’s trying to do.
We resolve this conundrum by modifying the training mechanism. At training time, we do know which domain each input is intended for, because the training data is labeled. During training, we evaluate the system not only on how accurately it classifies domains but also on how consistently the attention mechanism prioritizes the right locale-specific model when it receives locale-dependent data.
The outputs of the locale-specific models are combined into a single vector, with heavily weighted outputs contributing more to the vector’s final values than lower-weighted outputs. That vector is concatenated with the output of the locale-independent model, and the combined vector passes to another network layer for domain classification.
We evaluated this architecture using English-language data from the U.S., the U.K., India, and Canada. We trained our multi-task model on all four data sets and compared its performance to that of locale-specific models trained separately on the same data sets. That’s the experiment that yielded the accuracy improvements reported above.
We also conducted one more experiment, in which we used adversarial training to enforce the neutrality of the locale-independent model. That is, during training, in addition to evaluating the system’s performance on domain classification accuracy and routing of locale-dependent data, we also evaluated it on how badly the locale-independent model predicted locales.
This was an attempt to force the locale-independent model to extract only those characteristics of the data that were consistent across locales. In general, however, this hurt the system’s overall performance. The one exception was on the U.K. data set, where adversarial training conferred a slight performance boost. In ongoing work, we’re trying to determine the reason for that improvement.
Acknowledgments: Jihwan Lee, Ruhi Sarikaya



