
March 4 marks the kickoff of the third Alexa Prize Socialbot Grand Challenge, in which university teams build socialbots capable of conversing on a wide range of topics and make them available to millions of Alexa customers through the invitation “Alexa, let’s chat”. Student teams can begin applying to the competition on March 4, and in the subsequent six weeks, the Alexa Prize team will make a series of roadshow appearances at tech hubs in the U.S. and Europe to meet with students and answer questions about the program.
As we gear up for the third Alexa Prize Socialbot Grand Challenge, the Alexa science blog is reviewing some of the technical accomplishments from the second, which were reported in a paper released in late 2018. This post examines contributions by Amazon’s Alexa Prize team; a second post will examine innovations from the participating university teams.
To ensure that Alexa Prize contestants can concentrate on dialogue systems — the core technology of socialbots — Amazon scientists and engineers built a set of machine learning modules that handle fundamental conversational tasks and a development environment that lets contestants easily mix and match existing modules with those of their own design.
The Amazon team provided contestants with five primary tools:
- An automatic-speech-recognition system, tailored to the broader vocabulary of “open-domain” conversations;
- Contextual topic and dialogue act models, which identify topics of conversation and types of utterance, such as requests for information, clarifications, and instructions;
- A sensitive-content detector;
- A conversation evaluator model, which estimates how coherent and engaging responses generated by the contestants’ dialogue systems are; and
- CoBot, a development environment that integrates tools from the Alexa Skills Kit, services from Amazon Web Services, and the Alexa Prize team’s models and automatically handles socialbot deployment.
Automatic speech recognition
Because open-domain conversations between Alexa customers and Alexa Prize socialbots can range across a wide variety of topics and named entities, the socialbots require their own general-purpose automatic speech recognizer. In the 2018 Alexa Prize, we reduced the speech recognizer’s error rate by 30% by training it on conversational data from earlier interactions with Alexa Prize socialbots.
In ongoing work, we are also modifying the speech recognizer’s statistical language model, which assigns a probability to the next word in a sentence given the previous ones. We have developed a machine-learning system that, on the fly, mixes different statistical language models based on conversational cues. In tests, we compared our system to one that does not use these cues and found that it reduces speech transcription errors by as much as 6%. It also improves the recognition of named entities such as people, locations, and businesses by up to 15%.
Contextual topic and dialogue act models
In earlier work, our team found that accurate topic tracking is strongly correlated with users’ subjective assessments of the quality of socialbot conversations. To provide Alexa Prize teams with accurate topic models, we developed a system that factors in the content of not only the target utterance but the five that immediately preceded it. It also considers the target utterance’s dialogue act classification. In our experiments, that additional information improved the accuracy of the topic classification by 35%.
Sensitive-content detection
Teams’ socialbots often draw content from forum-style websites that may include offensive remarks. To filter out such remarks, we first ranked more than 5,000 Internet forum conversations according to how frequently they featured any of the 800 prohibited words on our blacklist. Then we trained a machine learning system on data from the Toxic Comment Classification Challenge, which was labeled according to offensiveness. That system sampled comments from the highest- and lowest-ranked forum conversations, and comments that had high confidence scores for either offensiveness or inoffensiveness were added to a new training set. Once we had 10 million examples each of offensive and inoffensive text, we used them to train a new sensitive-content classifier.
Conversation evaluator
To train our conversation evaluator, we used 15,000 conversations that averaged 10 or 11 turns each. Annotators labeled socialbot responses in sequence, assigning them yes-or-no scores on five criteria: whether they were comprehensible, on topic, incorrect (which is easier to assess than correctness), and interesting and whether they pushed the conversation further. The inputs to the conversation evaluator include the current utterance and response, past utterances and responses, and a collection of natural-language-processing features, such as part of speech, topic, and dialogue act.
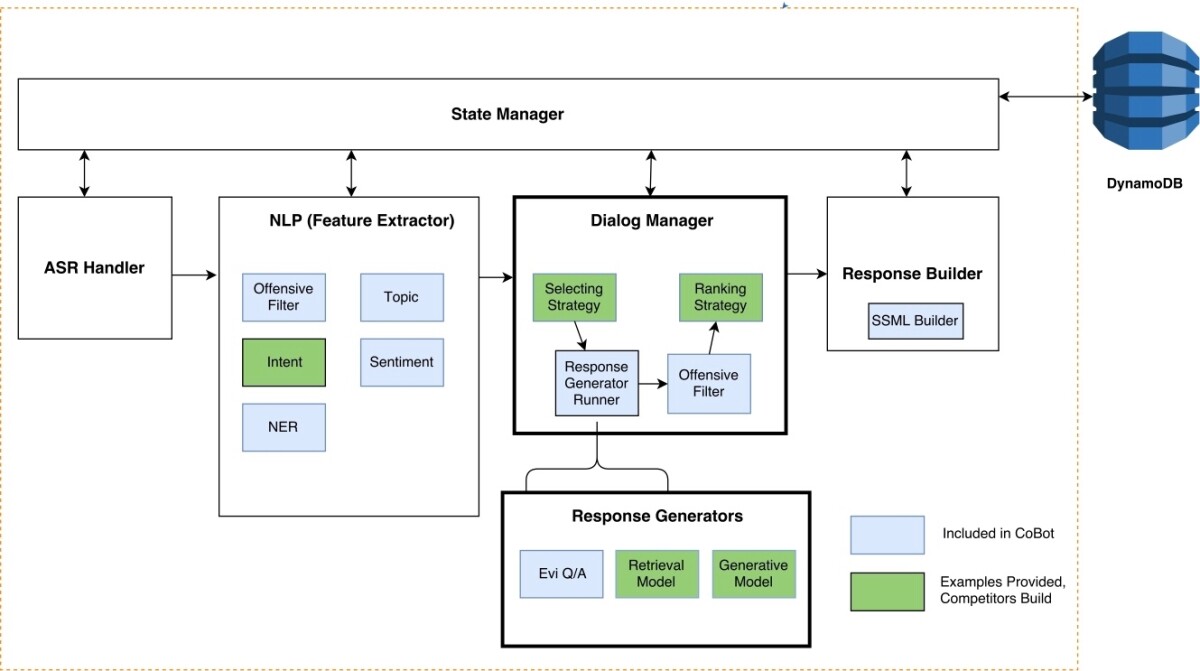
CoBot
With the launch of the 2018 Alexa Prize, we introduced the Conversational Bot Toolkit, or CoBot, a set of tools and interfaces that let the student teams concentrate more on science and less on questions of implementation, infrastructure, and scaling.
CoBot offers a single wrapper interface to three sets of tools: the Alexa Skills Kit, which lets third-party developers create new capabilities, or skills, for Alexa; a suite of cloud-computing services offered through Amazon Web Services; and the Alexa Prize Toolkit Service, which includes our natural-language-processing (NLP) models.
In our paper, we report that CoBot cut the time required to build the complex models and systems that power the contestants’ socialbots from months to weeks, and it cut the time required to address problems of scaling from one or two weeks to less than two days.
Data extracted by the NLP models — topics, named entities, dialogue acts, and so on — are stored in a very efficient DynamoDB database, offered through Amazon Web Services. The dialogue manager takes that data, as well as representations of current and past utterances and responses, and enacts a response selection strategy, which is one of the system components that the student teams provide.
For any given input utterance, the dialogue manager may generate candidate responses by querying databases, passing data to a machine learning model or a rule-based system, or all three. Candidate responses are passed to a ranker, also built by the student team, which selects a response to send to Alexa’s speech synthesizer.
CoBot enables easy A/B testing, so that the student team can compare two different models’ performance on the same inputs, and it also keeps logs of system performance, which can be used for debugging or model improvement. These testing capabilities are key to building complex socialbots that combine multiple machine learned models and knowledge sources to generate interesting and engaging responses.



