

Here’s a fairly common interaction with Alexa: “Alexa, set volume to five”; “Alexa, play music”. Even though the queries come in quick succession, the customer needs to repeat the wake word “Alexa”. To allow for more natural interactions, the device could immediately re-enter its listening state after the first query, without wake-word repetition; but that would require it to detect whether a follow-up speech input is indeed a query intended for the device (“device-directed”) or just background speech (“non-device-directed”).
In the paper we are presenting at Interspeech 2018, my colleagues and I describe a machine learning model that we developed to discriminate device-directed speech from background speech. Components of this model are already used by Alexa’s Follow-Up Mode, which, when enabled, allows customers to temporarily dispense with wake word repetition.
Most research on device-directed-speech detection has involved engineering acoustic features of the speech signal (energy and pitch trajectories, rate and duration information, etc.) and feeding them to a shallow classifier. We instead propose a deep neural-network model, whose inputs are features of the acoustic signal and features extracted from an automatic speech recognition (ASR) system, as depicted in the below figure.
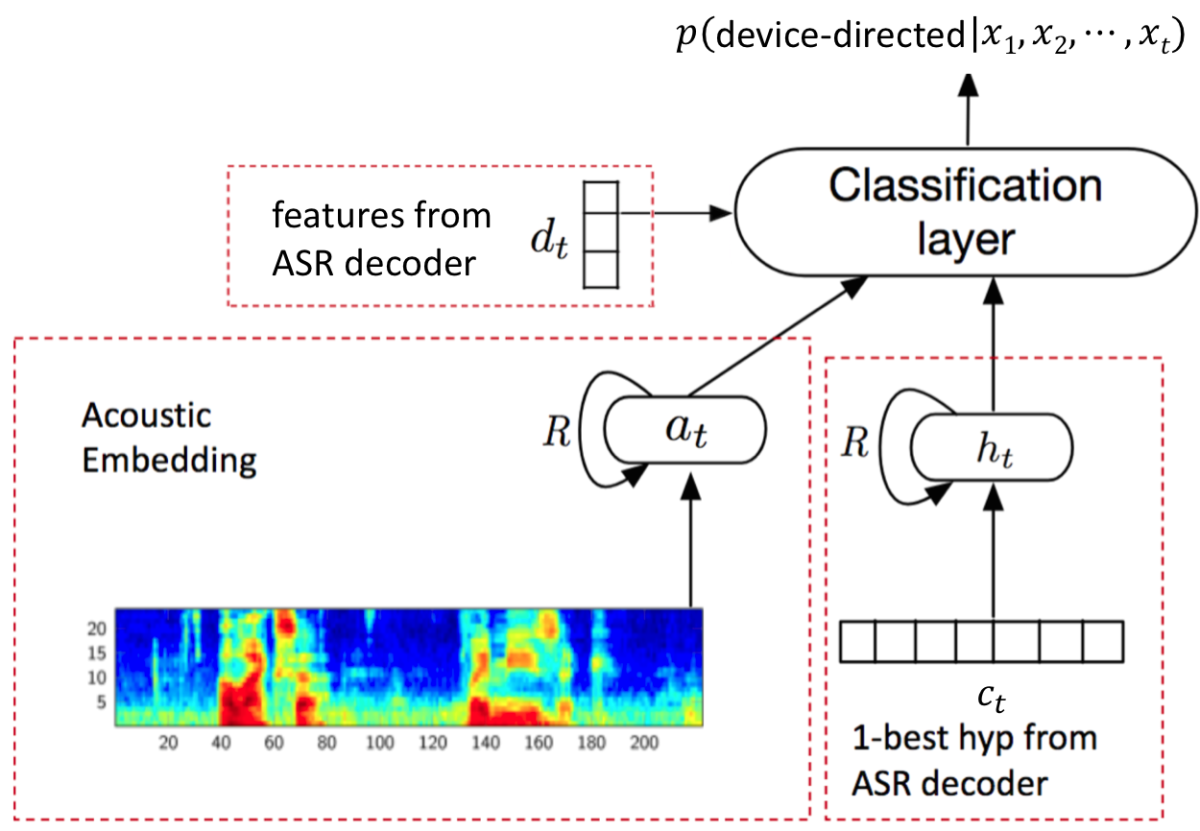
One of the inputs to our network is the log filter-bank energies of the source utterance, which describe the energies in different frequency bands of the acoustic signal. Those inputs pass to a long short-term memory (LSTM) network, a type of neural network common in speech recognition because it processes inputs in order, so it can learn systematic relationships between successive sounds. The output of the LSTM is an acoustic “embedding” — a vector that represents features of the acoustic signal particularly useful for the discrimination of device-directed and background speech.
Another input is the ASR system’s best guess at the transcription of the source utterance. We embed that transcription as well, numerically representing every letter using so-called character embeddings. Those embeddings also pass to an LSTM, whose output is a vector representing semantic features of the utterance useful for the classification task.
While processing an incoming microphone signal, the ASR system builds a graph of hypotheses — i.e., potential transcriptions. (This is a graph in the sense of a data structure consisting of “nodes”, typically depicted as circles, and “edges”, typically depicted as line segments connecting nodes.) The structure of this decoding graph (e.g., the number of edges and their probabilistic weights) describes how confident the ASR system is in the accuracy of its transcription of the acoustic signal.
The intuition is that low confidence suggests a possible mismatch between the input utterance and typical interactions the ASR model is trained on, which can be an indicator of non-device-directed speech. We feed these decoding-graph features, along with the above acoustic and character embeddings, to a final classification layer that, in turn, outputs a probability of the acoustic input signal's being device-directed.
We evaluated the performance of the model using real recordings of natural human interactions with voice-controlled devices and analyzed the different input features’ contributions to the accuracy of the model’s classifications.
On their own, the decoding-graph features result in an error rate of about 9%. The acoustic and character embeddings result in error rates of 11% and 20%, respectively. Our proposed model, which combines the three features using a deep neural network, resulted in an error rate of about 5%. This is a significant, 44% reduction in error rate compared to a system that uses the best individual features (i.e., the decoding-graph features). We also evaluated the tradeoff between false-positive and false-negative rates for systems that used our three feature sets independently and in combination and found that the combination universally outperforms the individual models. These results indicate that the individual feature sources are complementary to each other.
Acknowledgements: Roland Maas, Kyle Goehner, Ariya Rastrow, Spyros Matsoukas, Björn Hoffmeister



