
Today in Arlington, Virginia, at Amazon’s new HQ2, Amazon senior vice president Dave Limp hosted an event at which the Devices and Services organization rolled out its new lineup of products and services. For part of the presentation, Limp was joined by Rohit Prasad, an Amazon senior vice president and head scientist for artificial general intelligence, who previewed a host of innovations from the Alexa team.
Prasad’s main announcement was the release of the new Alexa large language model (LLM), a larger and more generalized model that has been optimized for voice applications. This model can converse with customers on any topic; it’s been fine-tuned to reliably make the right API calls, so it will turn on the right lights and adjust the temperature in the right rooms; it’s capable of proactive, inference-based personalization, so it can highlight calendar events, recently played music, or even recipe recommendations based on a customer’s grocery purchases; it has several knowledge-grounding mechanisms, to make its factual assertions more reliable; and it has guardrails in place to protect customer privacy.

During the presentation, Prasad discussed several other upgrades to Alexa’s conversational-AI models, designed to make interactions with Alexa more natural. One is a new way of invoking Alexa by simply looking at the screen of a camera-enabled Alexa device, eliminating the need to say the wake word on every turn: on-device visual processing is combined with acoustic models to determine whether a customer is speaking to Alexa or someone else.

Alexa has also had its automatic-speech-recognition (ASR) system overhauled — including machine learning models, algorithms, and hardware — and it’s moving to a new large text-to-speech (LTTS) model that’s based on the LLM architecture and is trained on thousands of hours of multispeaker, multilingual, multiaccent, and multi-speaking-style audio data.
Finally, Prasad unveiled Alexa’s new speech-to-speech model, an LLM-based model that produces output speech directly from input speech. With the speech-to-speech model, Alexa will exhibit humanlike conversational attributes, such as laughter, and it will be able to adapt its prosody not only to the content of its own utterances but to the speaker’s prosody as well — for instance, responding with excitement to the speaker’s excitement.
The ASR update will go live later this year; both LTTS and the speech-to-speech model will be deployed next year.
Speech recognition
The new Alexa ASR model is a multibillion-parameter model trained on a mix of short, goal-oriented utterances and longer-form conversations. Training required a careful alternation of data types and training targets to ensure best-in-class performance on both types of interactions.
To accommodate the larger ASR model, Alexa is moving from CPU-based speech processing to hardware-accelerated processing. The inputs to an ASR model are frames of data, or 30-millisecond snapshots of the speech signal’s frequency spectrum. On CPUs, frames are typically processed one at a time. But that’s inefficient on GPUs, which have many processing cores that run in parallel and need enough data to keep them all busy.

Alexa’s new ASR engine accumulates frames of input speech until it has enough data to ensure adequate work for all the cores in the GPUs. To minimize latency, it also tracks the pauses in the speech signal, and if the pause duration is long enough to indicate the possible end of speech, it immediately sends all accumulated frames.
The batching of speech data required for GPU processing also enables a new speech recognition algorithm that uses dynamic lookahead to improve ASR accuracy. Typically, when a streaming ASR application is interpreting an input frame, it uses the preceding frames as context: information about past frames can constrain its hypotheses about the current frame in a useful way. With batched data, however, the ASR model can use not only the preceding frames but also the following frames as context, yielding more accurate hypotheses.
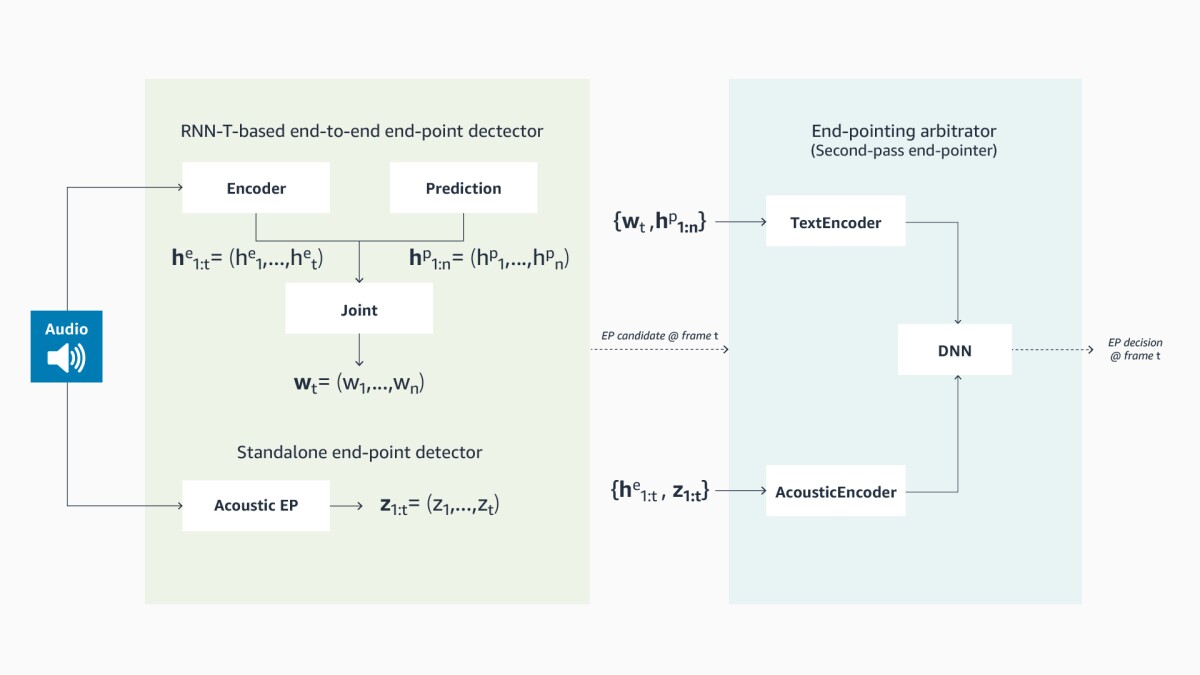
The final determination of end-of-speech is made by an ASR engine’s end-pointer. The earliest end-pointers all relied on pause length. Since the advent of end-to-end speech recognition, ASR models have been trained on audio-text pairs whose texts include a special end-of-speech token at the end of each utterance. The model then learns to output the token as part of its ASR hypotheses, indicating end of speech.
Alexa’s ASR engine has been updated with a new two-pass end-pointer that can better handle the type of mid-sentence pauses common in more extended conversational exchanges The second pass is performed by an end-pointing arbitrator, which takes as input the ASR model’s transcription of the current speech signal and its encoding of the signal. While the encoding captures features necessary for speech recognition, it also contains information useful for identifying acoustic and prosodic cues that indicate whether a user has finished speaking.
The end-pointing arbitrator is a separately trained deep-learning model that outputs a decision about whether the last frame of its input truly represents end of speech. Because it factors in both semantic and acoustic data, its judgments are more accurate than those of a model that prioritizes one or the other. And because it takes ASR encodings as input, it can leverage the ever-increasing scale of ASR models to continue to improve accuracy.
Once the new ASR model has generated a set of hypotheses about the text corresponding to the input speech, the hypotheses pass to an LLM that has been fine-tuned to rerank them, to yield more accurate results.
In the event that the new, improved end-pointer cuts off speech too soon, Alexa can still recover, thanks to a model that helps repair truncated speech. Applied scientist Marco Damonte and Angus Addlesee, a former intern studying artificial intelligence at Heriot-Watt University, described this model on the Amazon Science blog after presenting a paper about it at Interspeech.
The model produces a graph representation of the semantic relationships between words in an input text. From the map, downstream models can often infer the missing information; when they can’t, they can still often infer the semantic role of the missing words, which can help Alexa ask clarifying questions. This, too, makes conversation with Alexa more natural.
Large text-to-speech
Unlike earlier TTS models, LTTS is an end-to-end model. It consists of a traditional text-to-text LLM and a speech synthesis model that are fine-tuned in tandem, so the output of the LLM is tailored to the needs of the speech synthesizer. The fine-tuning dataset consists of thousands of hours of speech, versus the 100 or so hours used to train earlier models.

The fine-tuned LTTS model learns to implicitly model the prosody, tonality, intonation, paralinguistics, and other aspects of speech, and its output is used to generate speech.
The result is speech that combines the complete range of emotional elements present in human communication — such as curiosity when asking questions and comic joke deliveries — with natural disfluencies and paralinguistic sounds (such as ums, ahs, or muttering) to create natural, expressive, and human-like speech output.
A comparison of Alexa's existing text-to-speech model and the new LTTS model.
To further enhance the model’s expressivity, the LTTS model can be used in conjunction with another LLM fine-tuned to tag input text with “stage directions” indicating how the text should be delivered. The tagged text then passes to the TTS model for conversion to speech.
The speech-to-speech model
The Alexa speech-to-speech model will leverage a proprietary pretrained LLM to enable end-to-end speech processing: the input is an encoding of the customer’s speech signal, and the output is an encoding of Alexa’s speech signal in response.
That encoding is one of the keys to the approach. It’s a learned encoding, and it represents both semantic and acoustic features. The speech-to-speech model uses the same encoding for both input and output; the output is then decoded to produce an acoustic signal in one of Alexa’s voices. The shared “vocabulary” of input and output is what makes it possible to build the model atop a pretrained LLM.
The LLM is fine-tuned on an array of different tasks, such as speech recognition and speech-to-speech translation, to ensure its generality.

Alexa’s new capabilities will begin rolling out over the next few months.



