
To help promote research on generalizing task-oriented dialogue agents to new contexts, Amazon Alexa has launched a dialogue-based AI challenge on the site EvalAI. As benchmarks for the challenge, we have also released a set of models that achieve state-of-the-art performance on five of the seven challenge tasks.
The challenge — which we call DialoGLUE, for Dialogue Language Understanding Evaluation — is intended to encourage research on representation-based transfer, domain adaptation, and sample-efficient task learning. Advances in these techniques should enable conversational generalizability, or the ability of dialogue agents trained on one task to adapt easily to new tasks.
For instance, if we had an agent that was trained to handle restaurant bookings, we would like to be able adapt it to handling hotel reservations with minimal retraining. Today, however, the work required to extend the functionality of a dialogue agent often scales linearly with the number of added domains.
We believe that, at least in part, this is because of a lack of standardization in the datasets and evaluation methodologies used by the dialogue research community. To support DialoGLUE, we have released a data set that aggregates seven publicly accessible dialogue data sets but standardizes their data representations, so they can be used in combination to train and evaluate a single dialogue model.
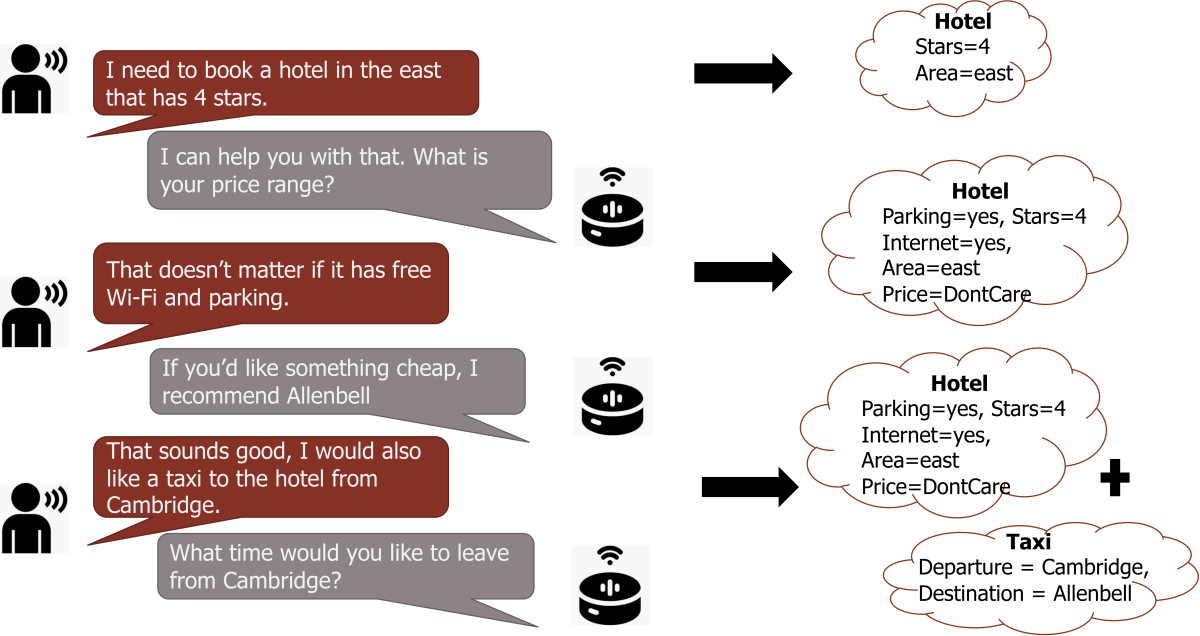
The annotations in the data set span four natural-language-understanding tasks. The first is intent prediction, or determining what service the user wants a voice agent to provide. The second is slot filling, or determining what entities the user has mentioned and their types. For instance, when given the instruction, “Play ‘Popstar’ by DJ Khaled”, a voice agent should recognize “Popstar” as the value of the slot Song_Name and “DJ Khaled” as the value of the slot Artist_Name.
The third task is semantic parsing, or determining the hierarchy of intents and slot values encoded in a single utterance. For instance, in the instruction “Get me tickets to Hamilton”, the intent to find the theater at which Hamilton is playing would be hierarchically nested inside the intent to buy tickets.
Finally, the fourth task is dialogue state tracking, or determining how the user’s intents, and the slots and slot-values required to fulfill those intents, change over the course of a conversation.
The DialoGLUE challenge on EvalAI proposes two evaluation settings, and participants may submit entries for either or both. In the first setting — the full-data setting — the challenge is to use the complete data set to train a dialogue model that can complete the seven tasks associated with the seven source data sets. In the second setting — the few-shot setting — the challenge is to train the dialogue model on only a fraction of the available data, approximately 10%.
DialoGLUE is a rolling challenge, so participants may submit their models at any time, and the leaderboard will be continuously updated.
On five of the seven tasks, our baseline models deliver state-of-the-art results, which both demonstrates the value of our aggregate data set and provides a bar for participants in the challenge to clear. Like the models, the baseline system is publicly available.



