
In the Internet age, many computational tasks involve finding a handful of solutions in an enormous space of candidates. Question-answering systems, for instance, can pull answers from anywhere on the web, while the Wikipedia taxonomy for classifying article topic classification has 500,000 terms. And of course, a product query at the Amazon Store has millions of potential matches.
Such extreme multilabel ranking (XMR) problems pose two major challenges. The first is one of scale, but the second is one of scarcity. The items in these large search spaces tend to have long-tailed distributions: most sentences rarely serve as answers to questions; most topics in the Wikipedia taxonomy rarely apply to texts; most products are rarely purchased; and so on. That means that attempts to use machine learning to solve XMR problems rarely have enough data to go on.
At Amazon, we have developed a general framework for meeting both these challenges, which we call PECOS, for prediction for enormous and correlated output spaces. After successfully using PECOS internally for key projects in product search and recommendation, we have publicly released the code to help stimulate further research on this important topic.
In the XMR context, the items retrieved from the search space are known as labels. If the task is document retrieval, the documents themselves are interpreted as candidate labels for a search string; the search string is the input. The “multilabel” in XMR indicates that a given input may have multiple labels; several different topics from the Wikipedia taxonomy, for instance, might apply to the same document.
PECOS decomposes the XMR problem into three stages:
- semantic label indexing, or grouping labels together according to semantic content;
- matching, or associating the input instance with a label group;
- ranking, or finding the labels in each group that best fit the input.
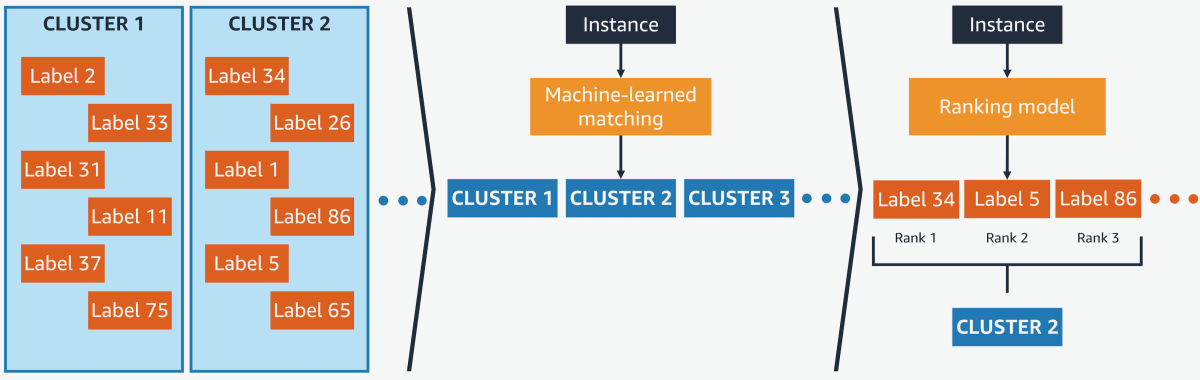
PECOS lets users create their own algorithms to implement any of these stages, but the code release comes with a library of standard algorithms for each stage, including both a recursive linear model and a trained deep-learning model for matching.
The three-stage framework helps with both the scaling and long-tail problems. By enabling matching with groups of labels rather than individual labels, label indexing drastically reduces the search space for the matching step. It also helps with the long-tail problem, since it enables the ranking model to exploit semantic similarities between common labels and less common labels.
For machine-learning-based implementations of the ranking stage, label indexing aids in the selection of hard negatives. Machine learning models must be trained on both positive examples and negative examples; in the XMR context, most negative examples are so irrelevant as to impart little information to the model. Selecting negative examples from the same groups as the positive examples ensures that they’ll be challenging enough to improve the quality of the model.
The initial release of PECOS includes two models that implement the entire PECOS framework. One is a recursive linear model, the other a deep-learning model. In tests involving a dataset with 2.8 million labels, the deep-learning model improved the precision of the top-ranked result (precision@1) by 10% relative to the recursive linear model, but it took 265 times as long to train. It’s up to the individual users to evaluate that trade-off for their own use cases.
Semantic label indexing
Semantic label indexing has two components: a representation scheme and a grouping algorithm. For text-based inputs, the representation scheme might take advantage of pre-trained text embeddings such as Word2Vec or ELMo; for graph-based inputs, it might use information about the input’s relationships with its neighbors in the graph. PECOS includes efficient implementations of representation schemes such as positive instance indices (PII), positive instance feature aggregation (PIFA), and the graph spectrum representation.
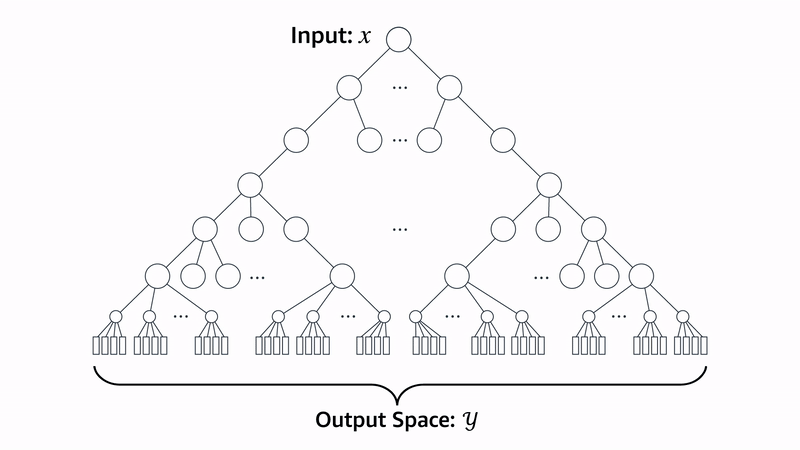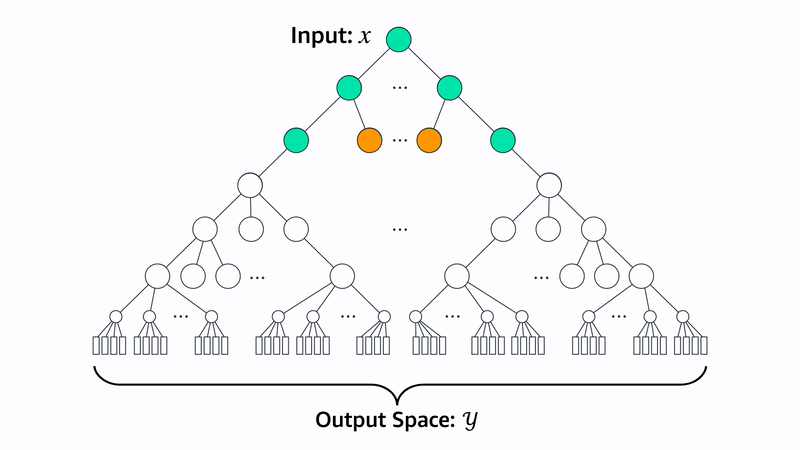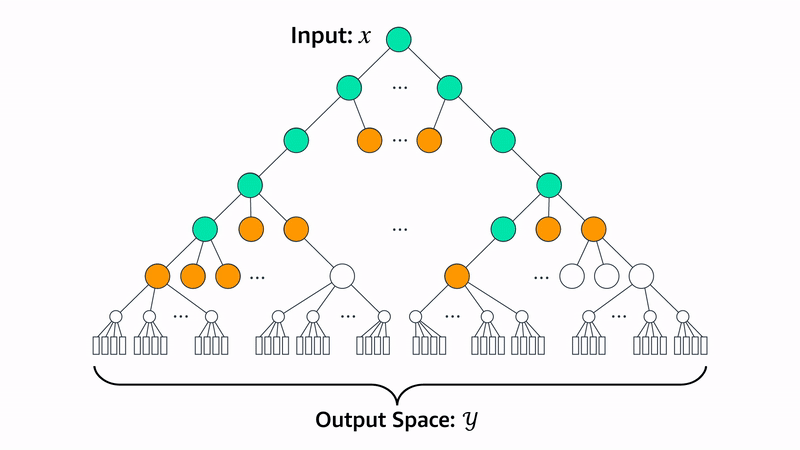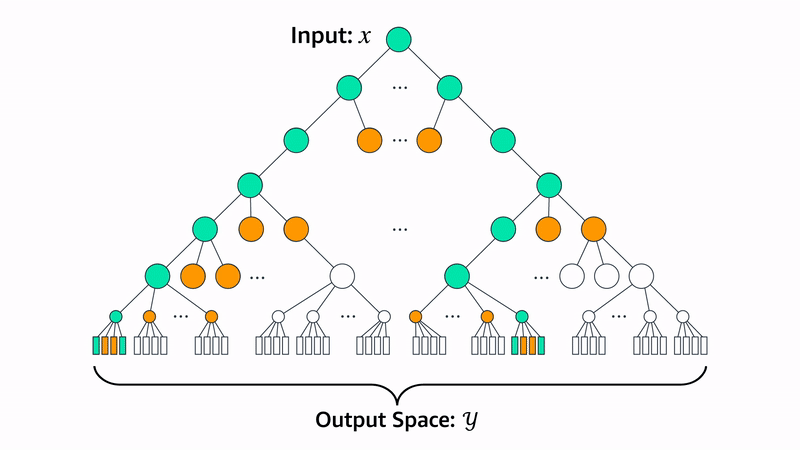
For grouping, we’ve concentrated on clustering algorithms, but users could implement other approaches, such as approximate nearest-neighbor search. PECOS includes our implementations of the k-means and spherical k-means clustering algorithms, which feature recursive B-ary partitioning. For some value of B (usually between 2 and 16), the algorithm first partitions the label set into B clusters, then partitions each of those into B clusters, and so on.
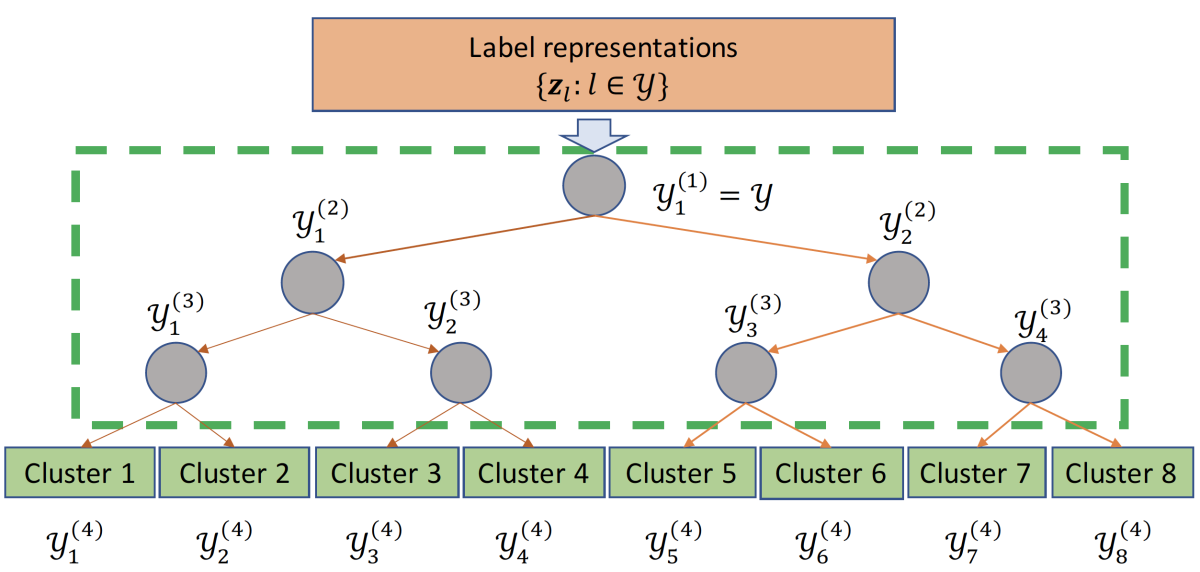
In a paper about PECOS that we’ve published to the arXiv, we show that B-ary partitioning can significantly reduce the time required for semantic-label indexing, an important consideration given that we’re dealing with enormous label spaces. We also use the B-ary partitioning to implement the recursive linear model.
Built-in models
For text inputs, PECOS includes X-Transformer, which leverages pretrained transformer models from Huggingface to improve performance on extreme multilabel text classification applications. At the 2020 Conference on Knowledge Discovery and Data Mining (KDD), we presented a paper about the PECOS deep-learning model, which we also described in a related blog post on Amazon Science.
PECOS also includes a linear model, XR-Linear, which learns its matching algorithm recursively. First, it learns a B-ary partition of the label space. Then, to implement a matcher for that partition, it learns a new B-ary partition for each of the existing groups. To implement matchers for those, it learns a new B-ary partition for each, and so on, until it reaches the desired recursive depth. At that point, it learns a simple linear one-versus-all ranker for the labels in each partition.
Then, for each level of recursion, it learns a ranker for the outputs of the layer below.
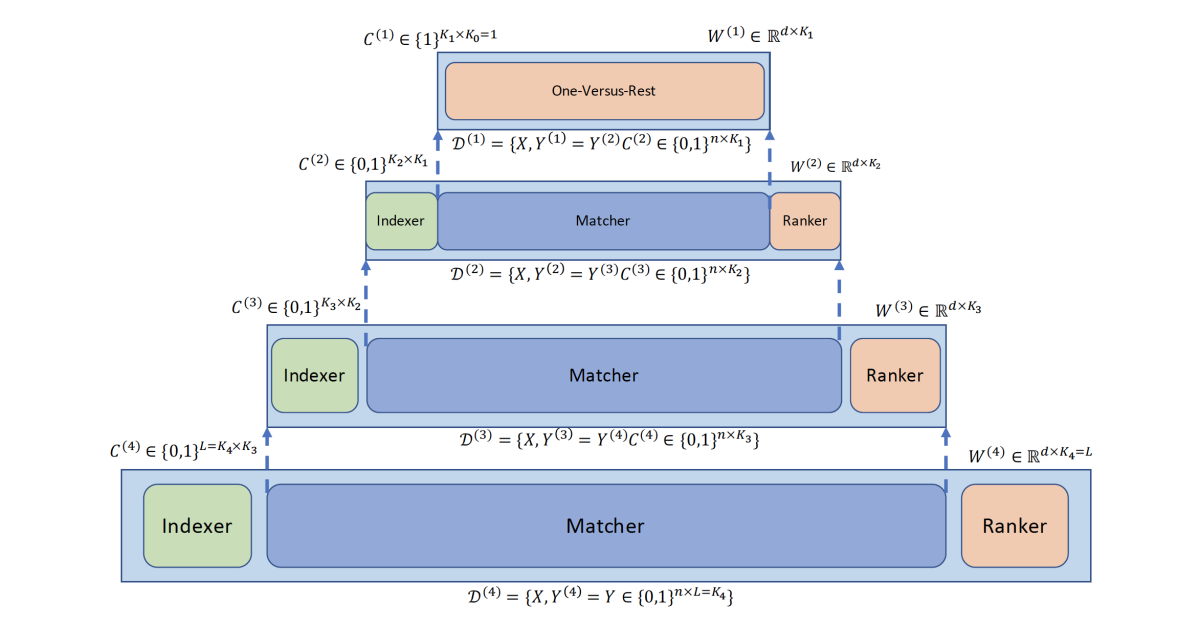
This makes training very efficient, as the full set of weights for each recursive layer can fit in memory at once, saving time on inefficient retrieval from storage.
At inference time, XR-Linear works through the same recursion tree to identify relevant labels. For efficiency, we use beam search to restrict the search space. For instance, if the beam width is two, then at each layer of the recursion tree, the model will pursue only the two highest-weight connections to the next layer.
Our PECOS software has benefited from open research that has been conducted at Amazon and at other universities and companies. By open-sourcing the PECOS software, we are thrilled to contribute back to the open-research community. Our hope is to spur further research on problems where the output spaces are very large. These include zero-shot learning for extreme multilabel problems, extreme contextual bandits, and deep reinforcement learning.
For more information about the optimizations we’ve incorporated into the PECOS code release, please see our arXiv paper. The code itself can be downloaded at GitHub.



