
At the Alexa Live event today, Nedim Fresko, vice president of Alexa Devices and Developers, said Amazon is now using deep neural networks to improve customers’ experience with Alexa skills.
Deep neural networks (DNNs) consist of thousands or even millions of densely connected processing nodes, loosely modeled on the neurons of the brain. DNNs learn to perform tasks by looking for patterns in huge sets of training data.

“We are adopting deep neural networks to improve Alexa’s natural-language understanding of individual words and sentences,” Fresko told the Alexa Live audience. “We’ve begun applying the technology to custom skills and are excited by the early results.”
Fresko said he expects that Alexa skills that use the new DNN-based technology will see an average increase in accuracy of 15%, and the company will continue to expand use of DNNs to 400 eligible skills in the U.S., Great Britain, India, and Germany by later this year.
Previously, Alexa skills have been powered solely by maximum-entropy and conditional-random-field (MaxEnt-CRF) models that perform natural-language understanding by determining the intent of an utterance and tagging its slots.
Also at today's Alexa Live event, Amazon scientists announced the public beta launch of Alexa Conversations dialogue management, which lets developers leverage a state-of-the-art dialogue manager powered by deep learning to create complex, nonlinear conversational experiences.
The input features to these models are utterance n-grams (sequences of n contiguous words taken from the utterance) and a few other features, such as the length of the utterance and the relative position of each token (words or combinations of words that constitute individual semantic units). These models base their predictions on a linear combination of the input signals, which makes them lightweight, easy to train, and fast during inference.
DNN models are better equipped to recognize natural language. DNNs, combined with unsupervised pretraining, have led to state-of-the-art performance in a variety of natural-language-processing domains.
Word embeddings are a core component of DNN models that represent each word token as a single point in a 300-dimensional vector space, such that words with similar meanings (similar co-occurrence profiles) are grouped together.
To develop effective word embeddings, Amazon scientists leverage a pretraining technique using unsupervised masked language modeling (MLM), made popular by BERT, along with several training corpora.
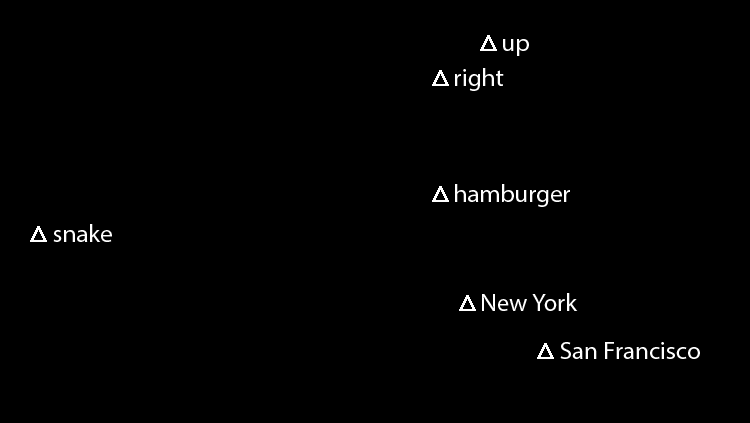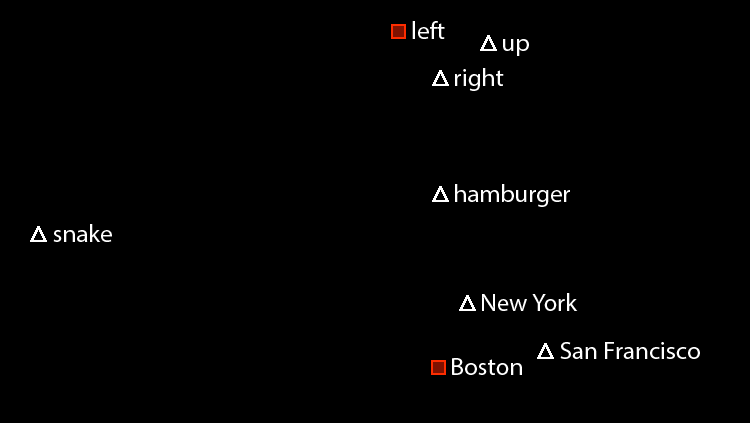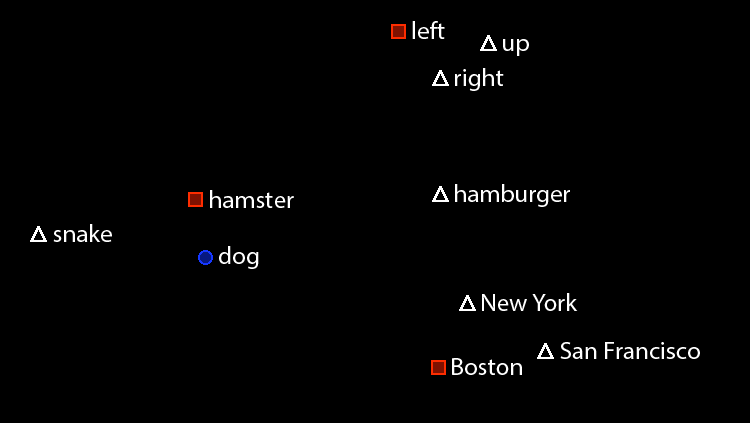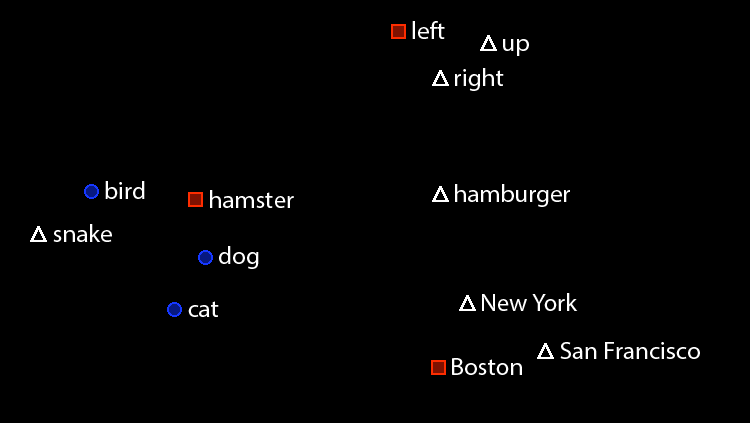
"With the pretrained word embeddings, DNNs can generalize from 'buy me an apple' to 'order an orange for me', as apple/orange and buy/order have similar representations in the underlying embedding space," explains Konstantine Arkoudas, who led the science effort on this project. "This mechanism is a form of transfer learning that gives DNNs a crucial advantage, as the models no longer learn solely from developer-provided dialogue examples."
Storing word embeddings, however, is extremely memory intensive. To make DNNs practical for more than 100,000 skills, the Amazon scientists combine a large store of shared, generic embeddings with small, local stores of skill-specific embeddings.
Finally, a number of nonlinear hidden layers enable DNNs to learn more-complex correlations between the input signals and the target outputs. DNNs outperform MaxEnt-CRF models because of these combined advantages.
Acknowledgments: The entire Alexa Science and NLU team for making the innovations highlighted here possible.



