
At this year’s International Conference on Learning Representations (ICLR), Amazon CodeWhisperer — the automatic-code-generation service from Amazon Web Services — is sponsoring the second Workshop on Deep Learning for Code (DL4C), the leading venue for research on deep learning for code. The areas of emphasis at this year’s workshop are human-computer interaction, evaluation, inference, responsible AI, and open-source AI for code.
The daylong DL4C workshop will take place on May 5, 2023, and consists of invited talks, panels, and oral presentations of accepted papers. The full schedule can be found on the workshop website, but the invited speakers are
- Harm de Vries, a research scientist in the Human-Machine Interaction through Language program at ServiceNow Research;
- Alex Polozov, a staff research scientist at Google;
- Nadia Polikarpova, an assistant professor in the Computer Science and Engineering Department at the University of California, San Diego;
- Armando Solar-Lezama, a professor in MIT’s Department of Electrical Engineering and Computer Science;
- Danny Tarlow, a research scientist at Google Brain; and
- Leandro von Werra, a machine learning engineer in the open-source team at Hugging Face.
In addition to Amazon CodeWhisperer’s sponsorship of the workshop, Zijian Wang — who, as an applied scientist in the AWS AI Labs, is part of the CodeWhisperer team — is one of the workshop’s five organizers. He’s also a coauthor on Amazon’s two papers at the workshop.
Multilevel contrastive learning
The first of these is “ContraCLM: Contrastive learning for causal language model”. Causal language models (CLMs), such as the GPT family of models, are language models trained to predict the next token — a phrase, word, or subword unit — in a sequence, given the previous tokens. While CLMs are exceptional at language-generation tasks, including code generation, they exhibit poor discrimination: for example, they cannot determine whether two word sequences have the same meaning or whether two code blocks perform the same function.
In part, this is because CLMs tend to be anisotropic: that is, their representations of inputs are confined to a subregion of the representational space. To expand CLM’s use of the representational space — to increase their isotropy — the AWS researchers use contrastive learning, in which a model is trained on pairs of inputs, some of which are similar and some of which are dissimilar. During training, the model learns to push apart the representations of the dissimilar inputs and pull together the representations of the similar ones.
Particularly, the AWS researchers propose a multilevel contrastive-learning objective. At the sequence level, the model learns to group together text sequences with the same meaning while pushing apart text sequences with different meanings. At the token level, however, the model learns to push apart different tokens from the same input sequence. The combination of these two objectives enables the model to use much more of the representational space.
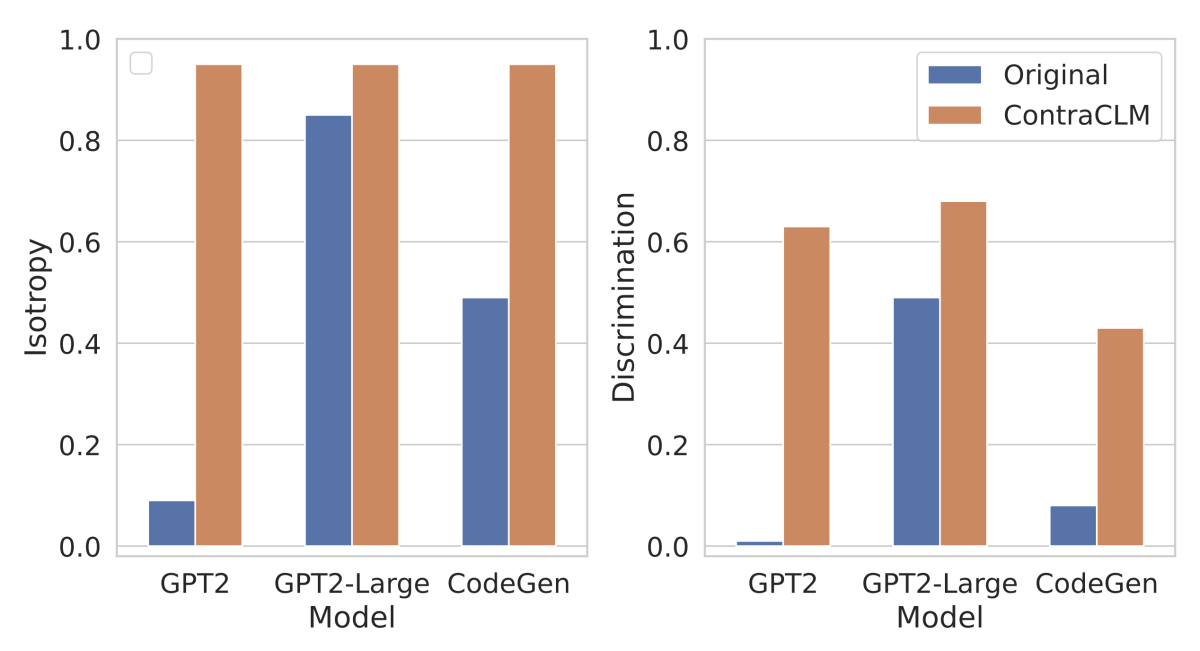
The researchers measure the model’s accuracy on both natural-language and programming-language tasks. On the former, the researchers’ model — ContraCLM — achieves better MAUVE scores on the WikiText-103 test set, indicating that the texts it generates are more semantically coherent. On the latter, it performs up to 34% better on code search tasks on CodeNet and 9-11% better on code completion tasks on the HumanEval benchmark.
Evaluating robustness
The second AWS paper is titled “ReCode: Robustness evaluation of code generation models”. LLM-based code generation, like most LLM applications, involves completion based on a given prompt. For instance, the user might enter the prompt “Write a function to find all words which are at least 4 characters long in a string by using regex”.
However, LLMs are very sensitive to small perturbations of the prompt: a single typo or word change can alter the output. For instance, the researchers report that changing the function name “remove_lowercase” from “snake case” (words demarcated by underscores) to “camel case” (words demarcated by capital letters, as in “removeLowercase”) will completely change the generated code, resulting in faulty logic in some models. This fragility raises severe robustness concerns.
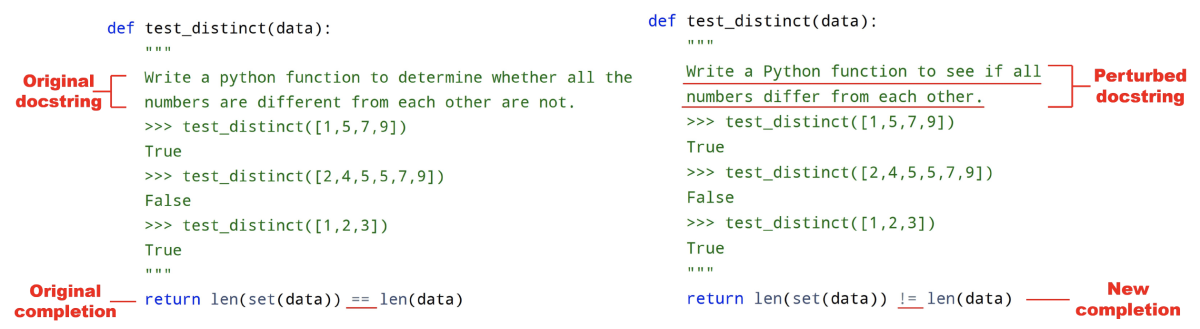
In their paper, the AWS researchers present ReCode, the first comprehensive robustness evaluation benchmark for code generation models. ReCode perturbs LLM prompts by applying 30 automatic transformations, based on error types common in real-world docstrings, functions, code syntax, and more. Those transformations include things like reversed order of character pairs, substitution of synonyms, the insertion of dummy code (zero-iteration loops or always-false conditionals), variable renaming, and CamelCasing.
The ReCode paper also proposes metrics for evaluating models’ robustness given different prompt perturbations. Finally, the researchers benchmarked various popular LLMs on ReCode and reported the results.
The AWS papers at the workshop, however, are only two of 23 on the program. Wang says that he is looking forward to the workshop and to learning more about the other participants’ work. “The workshop is bringing together some of the top names in the field,” he says. “It’s an exciting time to be working on this intriguing and increasingly important topic.”



