
In electronic voice communication, noise and reverberation not only hurt intelligibility but also cause listener fatigue through the effort required to understand poor-quality speech for long periods of time. As we spend more time in remote meetings during the COVID-19 pandemic, this problem is more relevant than ever.
The Deep Noise Suppression Challenge at this year’s Interspeech conference is an attempt to help solve that problem, with separate competitions for real-time speech enhancement and non-real-time speech enhancement. Out of 19 teams, Amazon had the best results, taking first place (phase1 | phase2-final) in the non-real-time track and second in the real-time track.
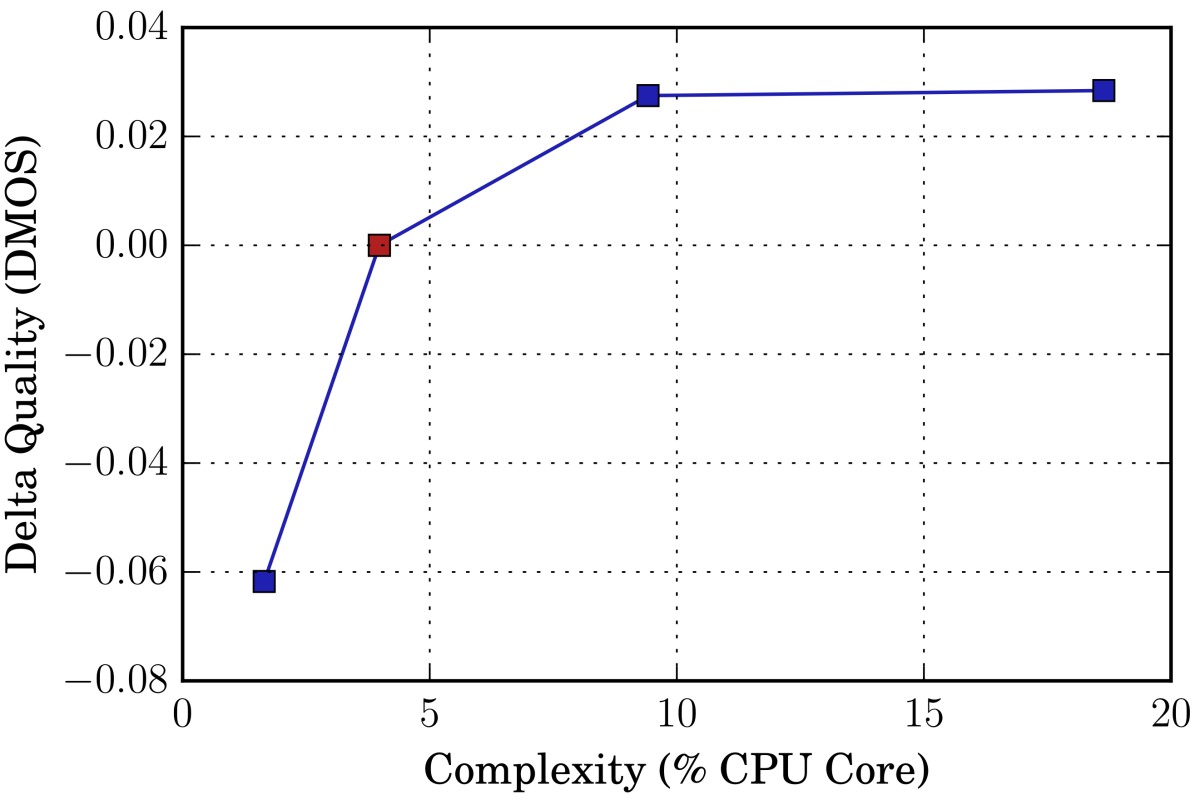
To meet real-world requirements, we restricted our real-time entry to just 4% of CPU use (measured on an i7-8565U core) — far less than the maximum allowed by the competition. Yet our real-time entry finished very close (0.03 mean opinion score) to first place, beating the rest of the non-real-time entries as well.
Audio examples of the Amazon team’s real-time and non-real-time noise suppression results can be found here. We are also publishing two papers (paper1-offline | paper2-real-time) that describe our technical approach in greater detail.
The technology that won at Interspeech has been launched in the Alexa Communication Announcements and Drop In Everywhere features, and as of today, it is also available directly to our customers using the Amazon Chime Apple macOS and Microsoft Windows clients for videoconferencing and online meetings. You can give the new feature a try by downloading and signing up for the free Amazon Chime 30-day Pro trial.
Optimizing for perception
Classical speech enhancement algorithms use hand-tuned models of speech and noise, generally assuming that noise is constant. These work reasonably well for some types of noise (car noise, for example) in environments that aren't too noisy or reverberant. Unfortunately, they often fail on non-stationary noises, such as keyboard noise and babble noise. As a result, researchers have turned to deep-learning methods.
Speech enhancement requires not only extracting the original speech from the noise and reverberation but doing so in a way that the human ear perceives as natural and pleasant. This makes automated regression testing difficult and complicates the design of deep-learning speech enhancement systems.
Our real-time system actually took advantage of human-perception considerations by directly optimizing the perceptual characteristics (spectral envelope and voicing) of the speech, while ignoring the perceptually irrelevant aspects. The resulting algorithm produced state-of-the art speech quality while remaining very computationally efficient.
For the non-real-time system, we took a no-compromise approach, using an improved U-Net deep convolutional network to squeeze every possible bit of quality out of the enhanced speech, resulting in the winning challenge entry.
In the Deep Noise Suppression Challenge, processed audio examples were sent, blind, to human listeners, who rated them to produce mean opinion scores (MOS).
In real-time applications, there is always a trade-off between complexity and quality. The figure at right shows how we can further improve the quality of our real-time submission by increasing the CPU requirement or, alternatively, further save on CPU use by sacrificing some quality. The red dot represents the real-time system submitted to the challenge, and the graph shows MOS score changes relative to different CPU loads.
The general consensus is that deep learning is finally having a profound impact on audio processing. There are still many challenges — including data augmentation, perceptually relevant loss functions, and dealing with unseen conditions — but the future looks very exciting.



