
Voice-enabled devices with screens — like the Echo Show — are growing in popularity, and they offer new opportunities for multimodal interactions, in which customers use spoken language to refer to items on-screen, helping them communicate their intentions more efficiently. The task of using natural-language understanding to select the correct object on the screen is known as multimodal coreference resolution.

Multimodal models have delivered impressive results on tasks like visual search, in which they find images that match a textual description. But they struggle with coreference resolution, in part because there are so many possible ways to refer to an object on-screen. Some refer to visual characteristics of the scene, such as objects’ colors or position on screen, and some refer to metadata.
In the tenth Dialog State Tracking Challenge (DSTC10), a model that we developed with colleagues at the University of California, Los Angeles, finished first in the multimodal coreference resolution task. We described the model in a paper we presented last month at the International Conference on Computational Linguistics (COLING).
The model
We base our model on visual-linguistic BERT (VL-BERT), a model trained on pairs of text and images. It adapts the masked-language-model training typical of BERT models, in which certain aspects of the input — either words of the sentence or regions of the images — are masked out, and the model must learn to predict them. It thus learns to predict images based (in part) on textual input and vice versa.
We make three main modifications to this approach:
- We represent relationships between objects in an image using graphs and capture that graphical information using graph neural networks;
- We add additional knowledge sources in the form of object metadata, to allow coreferencing based on nonvisual features such as brand or price; and
- We supplement information about an object’s surrounding by explicitly sampling from its neighborhood and generating captions describing the object. This enables coreferencing involving surrounding context (e.g., accessory objects like shelves and tables).
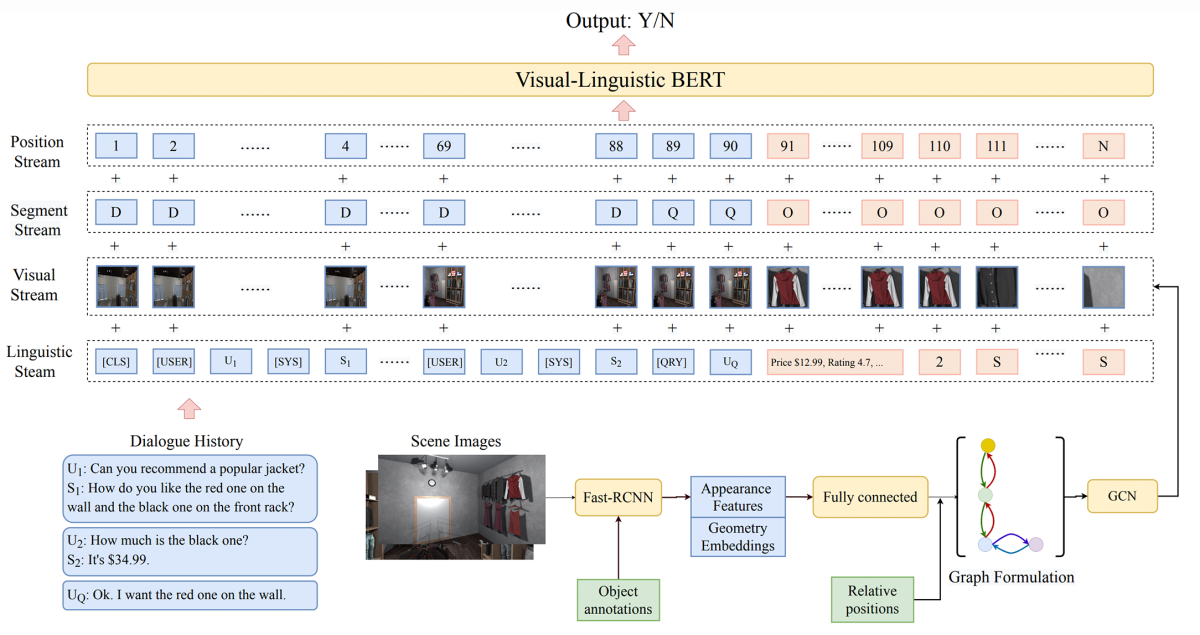
For each object in the current scene, the model outputs a binary decision whether that is the object referred to in the current round of dialogue.
Graphical representation
Using the relative locations of the objects in the scene, our model produces a graph, with nodes representing objects and edges describing the relationships between objects in the scene. Edges encode five types of relationships. The first four — top, bottom, left, and right — form two matched pairs: two nodes connected by a top edge, for instance, will also be connected by a bottom edge running in the opposite direction. The fifth relationship, inside, relates all the objects to a special “scene” node.
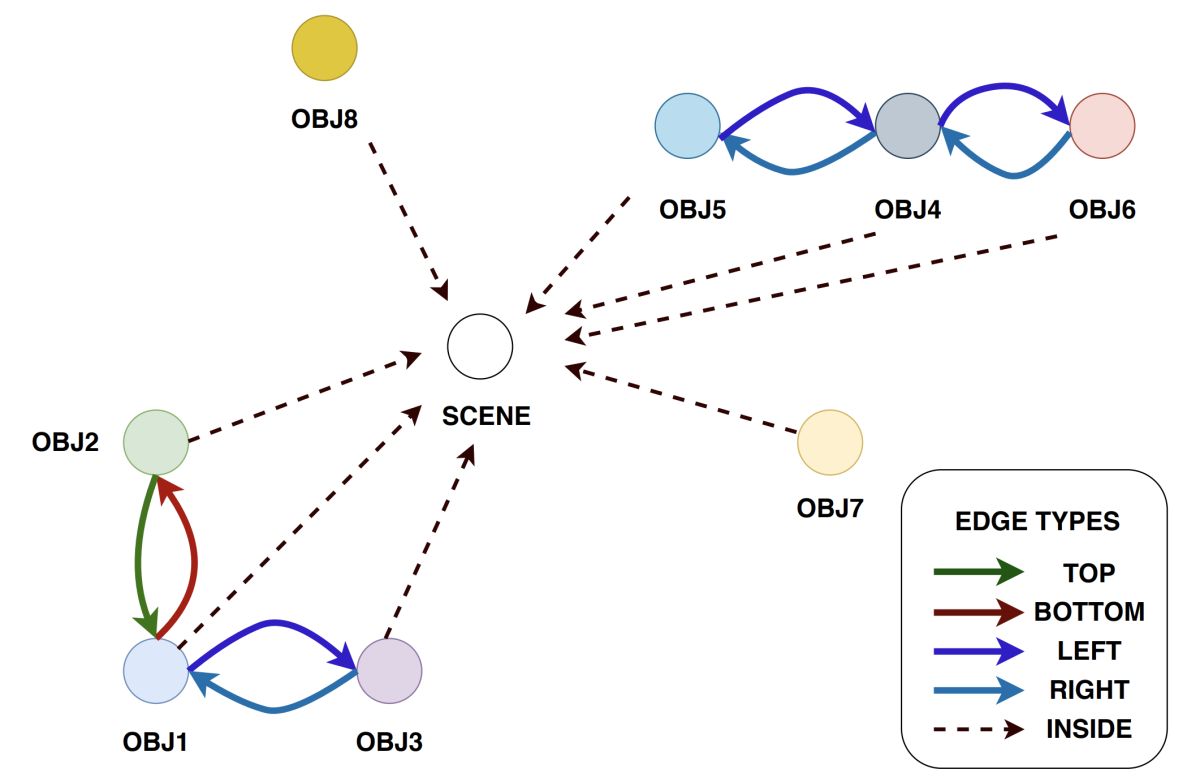
The graph then passes to a graph neural network — specifically, a graph convolutional network — that produces an embedding for each node, which captures information about the node’s immediate neighborhood in the graph. These embeddings are inputs to the coreference resolution model.
Local information
Some elements of the visual scene may not be identified by the object recognizer, but customers may still use them to specify objects — e.g., “The one on the counter”. To resolve such specifications, we use information about an object’s local environment, which we capture in two ways.
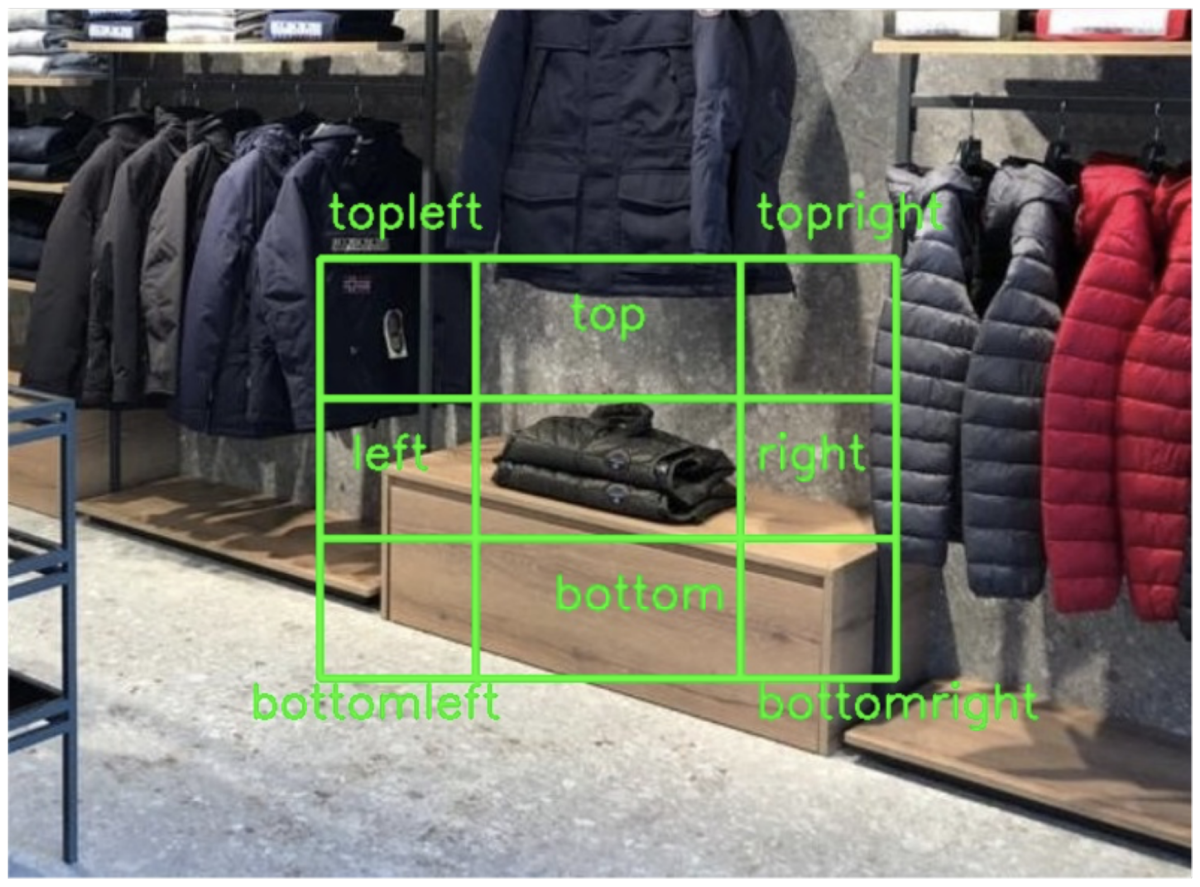
First, we produce eight new boxes arrayed around the object in eight directions: top left, top, top right, etc. Then we encode visual features of the image regions within those boxes and append them to coreference resolution model’s visual input stream.
Note that this differs from the information captured by the graph in two ways: it’s local information, while the graph can represent the relative locations of more-distant objects; and there are no labeled objects in the additional boxes. The encoding captures general visual features.
Second, during model training, we use an image-captioning model to describe additional objects in the vicinity of the object of interest — for example, shelves, tables, racks etc. This enables the model to identify objects based on descriptions of the surrounding context — for instance, “the jacket on the bench”.

Combining these modifications with the addition of the dialogue-turn distance metric enabled out model to place first in the DSTC10 multimodal coreference resolution challenge, where performance is measured by F1 score, which factors in both false positives and false negatives. We expect this work to pay dividends for Alexa customers, by making it easier to express their intentions when using Alexa-enabled devices with screens.



