
The International Conference on Acoustics, Speech, and Signal Processing (ICASSP) starts next week, and as Alexa principal research scientist Ariya Rastrow explained last year, it casts a wide net. The topics of the 36 Amazon research papers at this year’s ICASSP range from the classic signal-processing problems of noise and echo cancellation to such far-flung problems as separating song vocals from instrumental tracks and regulating translation length.
A plurality of the papers, however, concentrate on the core technology of automatic speech recognition (ASR), or converting an acoustic speech signal into text:
- ASR n-best fusion nets
Xinyue Liu, Mingda Li, Luoxin Chen, Prashan Wanigasekara, Weitong Ruan, Haidar Khan, Wael Hamza, Chengwei Su - Bifocal neural ASR: Exploiting keyword spotting for inference optimization
Jon Macoskey, Grant P. Strimel, Ariya Rastrow - Domain-aware neural language models for speech recognition
Linda Liu, Yile Gu, Aditya Gourav, Ankur Gandhe, Shashank Kalmane, Denis Filimonov, Ariya Rastrow, Ivan Bulyko - End-to-end multi-channel transformer for speech recognition
Feng-Ju Chang, Martin Radfar, Athanasios Mouchtaris, Brian King, Siegfried Kunzmann - Improved robustness to disfluencies in RNN-transducer-based speech recognition
Valentin Mendelev, Tina Raissi, Guglielmo Camporese, Manuel Giollo - Personalization strategies for end-to-end speech recognition systems
Aditya Gourav, Linda Liu, Ankur Gandhe, Yile Gu, Guitang Lan, Xiangyang Huang, Shashank Kalmane, Gautam Tiwari, Denis Filimonov, Ariya Rastrow, Andreas Stolcke, Ivan Bulyko - reDAT: Accent-invariant representation for end-to-end ASR by domain adversarial training with relabeling
Hu Hu, Xuesong Yang, Zeynab Raeesy, Jinxi Guo, Gokce Keskin, Harish Arsikere, Ariya Rastrow, Andreas Stolcke, Roland Maas - Sparsification via compressed sensing for automatic speech recognition
Kai Zhen, Hieu Duy Nguyen, Feng-Ju Chang, Athanasios Mouchtaris, Ariya Rastrow - Streaming multi-speaker ASR with RNN-T
Ilya Sklyar, Anna Piunova, Yulan Liu - Using synthetic audio to improve the recognition of out-of-vocabulary words in end-to-end ASR systems
Xianrui Zheng, Yulan Liu, Deniz Gunceler, Daniel Willett
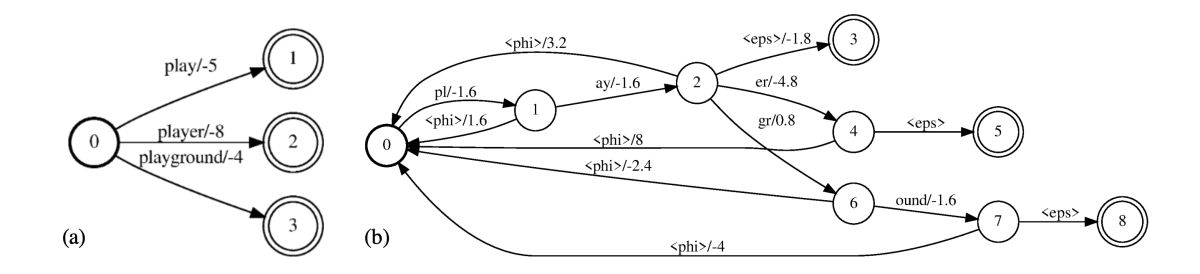
Two of the papers address language (or code) switching, a more complicated version of ASR in which the speech recognizer must also determine which of several possible languages is being spoken:
- Joint ASR and language identification using RNN-T: An efficent approach to dynamic language switching
Surabhi Punjabi, Harish Arsikere, Zeynab Raeesy, Chander Chandak, Nikhil Bhave, Markus Mueller, Sergio Murillo, Ariya Rastrow, Andreas Stolcke, Jasha Droppo, Sri Garimella, Roland Maas, Mat Hans, Athanasios Mouchtaris, Siegfried Kunzmann - Transformer-transducers for code-switched speech recognition
Siddharth Dalmia, Yuzong Liu, Srikanth Ronanki, Katrin Kirchhoff
The acoustic speech signal contains more information than just the speaker’s words; how the words are said can change their meaning. Such paralinguistic signals can be useful for a voice agent trying to determine how to interpret the raw text. Two of Amazon’s ICASSP papers focus on such signals:
- Contrastive unsupervised learning for speech emotion recognition
Mao Li, Bo Yang, Joshua Levy, Andreas Stolcke, Viktor Rozgic, Spyros Matsoukas, Constantinos Papayiannis, Daniel Bone, Chao Wang - Disentanglement for audiovisual emotion recognition using multitask setup
Raghuveer Peri, Srinivas Parthasarathy, Charles Bradshaw, Shiva Sundaram
Several papers address other extensions of ASR, such as speaker diarization, or tracking which of several speakers issues each utterance; inverse text normalization, or converting the raw ASR output into a format useful to downstream applications; and acoustic event classification, or recognizing sounds other than human voices:
- BW-EDA-EEND: Streaming end-to-end neural speaker diarization for a variable number of speakers
Eunjung Han, Chul Lee, Andreas Stolcke - Neural inverse text normalization
Monica Sunkara, Chaitanya Shivade, Sravan Bodapati, Katrin Kirchhoff - Unsupervised and semi-supervised few-shot acoustic event classification
Hsin-Ping Huang, Krishna C. Puvvada, Ming Sun, Chao Wang
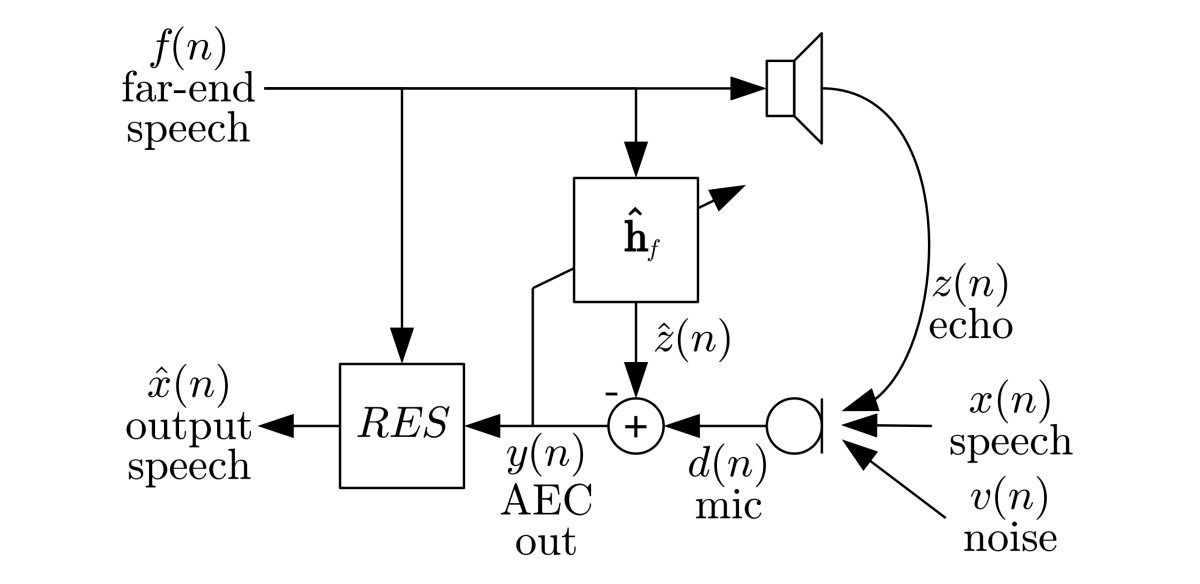
Speech enhancement, or removing noise and echo from the speech signal, has been a prominent topic at ICASSP since the conference began in 1976. But more recent work on the topic — including Amazon’s two papers this year — uses deep-learning methods:
- Enhancing into the codec: Noise robust speech coding with vector-quantized autoencoders
Jonah Casebeer, Vinjai Vale, Umut Isik, Jean-Marc Valin, Ritwik Giri, Arvindh Krishnaswamy - Low-complexity, real-time joint neural echo control and speech enhancement based on Percepnet
- Jean-Marc Valin, Srikanth V. Tenneti, Karim Helwani, Umut Isik, Arvindh Krishnaswamy
Every interaction with Alexa begins with a wake word — usually “Alexa”, but sometimes “computer” or “Echo”. So at ICASSP, Amazon usually presents work on wake word detection — or keyword spotting, as it’s more generally known:
- Exploring the application of synthetic audio in training keyword spotters
Andrew Werchniak, Roberto Barra-Chicote, Yuriy Mishchenko, Jasha Droppo, Jeff Condal, Peng Liu, Anish Shah
In many spoken-language systems, the next step after ASR is natural-language understanding (NLU), or making sense of the text output from the ASR system:
- Introducing deep reinforcement learning to NLU ranking tasks
Ge Yu, Chengwei Su, Emre Barut - Language model is all you need: Natural language understanding as question answering
Mahdi Namazifar, Alexandros Papangelis, Gokhan Tur, Dilek Hakkani-Tür
In some contexts, however, it’s possible to perform both ASR and NLU with a single model, in a task known as spoken-language understanding:
- Do as I mean, not as I say: Sequence loss training for spoken language understanding
Milind Rao, Pranav Dheram, Gautam Tiwari, Anirudh Raju, Jasha Droppo, Ariya Rastrow, Andreas Stolcke - Graph enhanced query rewriting for spoken language understanding system
Siyang Yuan, Saurabh Gupta, Xing Fan, Derek Liu, Yang Liu, Chenlei (Edward) Guo - Top-down attention in end-to-end spoken language understanding
Yixin Chen, Weiyi Lu, Alejandro Mottini, Erran Li, Jasha Droppo, Zheng Du, Belinda Zeng
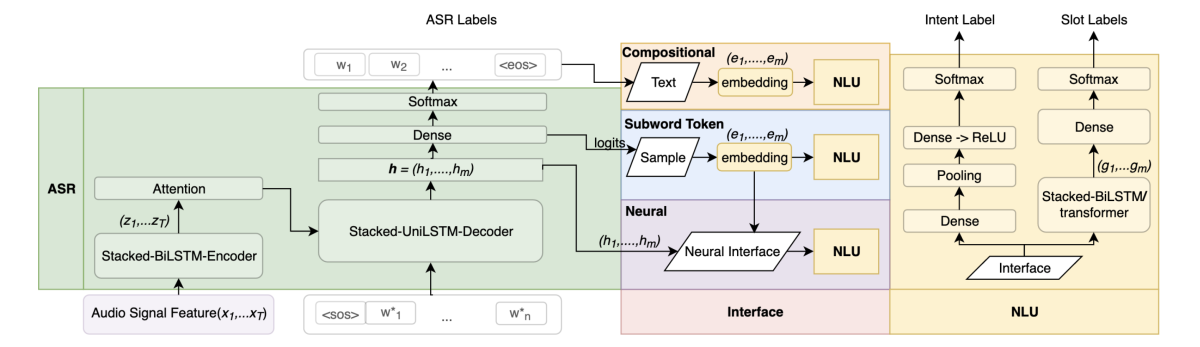
An interaction with a voice service, which begins with keyword spotting, ASR, and NLU, often culminates with the agent’s use of synthesized speech to relay a response. The agent’s text-to-speech model converts the textual outputs of various NLU and dialogue systems into speech:
- CAMP: A two-stage approach to modelling prosody in context
Zack Hodari, Alexis Moinet, Sri Karlapati, Jaime Lorenzo-Trueba, Thomas Merritt, Arnaud Joly, Ammar Abbas, Penny Karanasou, Thomas Drugman - Low-resource expressive text-to-speech using data augmentation
Goeric Huybrechts, Thomas Merritt, Giulia Comini, Bartek Perz, Raahil Shah, Jaime Lorenzo-Trueba - Prosodic representation learning and contextual sampling for neural text-to-speech
Sri Karlapati, Ammar Abbas, Zack Hodari, Alexis Moinet, Arnaud Joly, Penny Karanasou, Thomas Drugman - Universal neural vocoding with Parallel WaveNet
Yunlong Jiao, Adam Gabrys, Georgi Tinchev, Bartosz Putrycz, Daniel Korzekwa, Viacheslav Klimkov
All of the preceding research topics have implications for voice services like Alexa, but Amazon has a range of other products and services that rely on audio-signal processing. Three of Amazon’s papers at this year’s ICASSP relate to audio-video synchronization: two deal with dubbing audio in one language onto video shot in another, and one describes how to detect synchronization errors in video — as when, for example, the sound of a tennis ball being struck and the shot of the racquet hitting the ball are misaligned:
- Detection of audio-video synchronization errors via event detection
Joshua P. Ebenezer, Yongjun Wu, Hai Wei, Sriram Sethuraman, Zongyi Liu - Improvements to prosodic alignment for automatic dubbing
Yogesh Virkar, Marcello Federico, Robert Enyedi, Roberto Barra-Chicote - Machine translation verbosity control for automatic dubbing
Surafel Melaku Lakew, Marcello Federico, Yue Wang, Cuong Hoang, Yogesh Virkar, Roberto Barra-Chicote, Robert Enyedi
Amazon’s Text-to-Speech team has an ICASSP paper on the unusual topic of computer-assisted pronunciation training, a feature of some language learning applications. The researchers’ method would enable language learning apps to accept a wider range of word pronunciations, to score pronunciations more accurately, and to provide more reliable feedback:
- Mispronunciation detection in non-native (L2) English with uncertainty modeling
Daniel Korzekwa, Jaime Lorenzo-Trueba, Szymon Zaporowski, Shira Calamaro, Thomas Drugman, Bozena Kostek
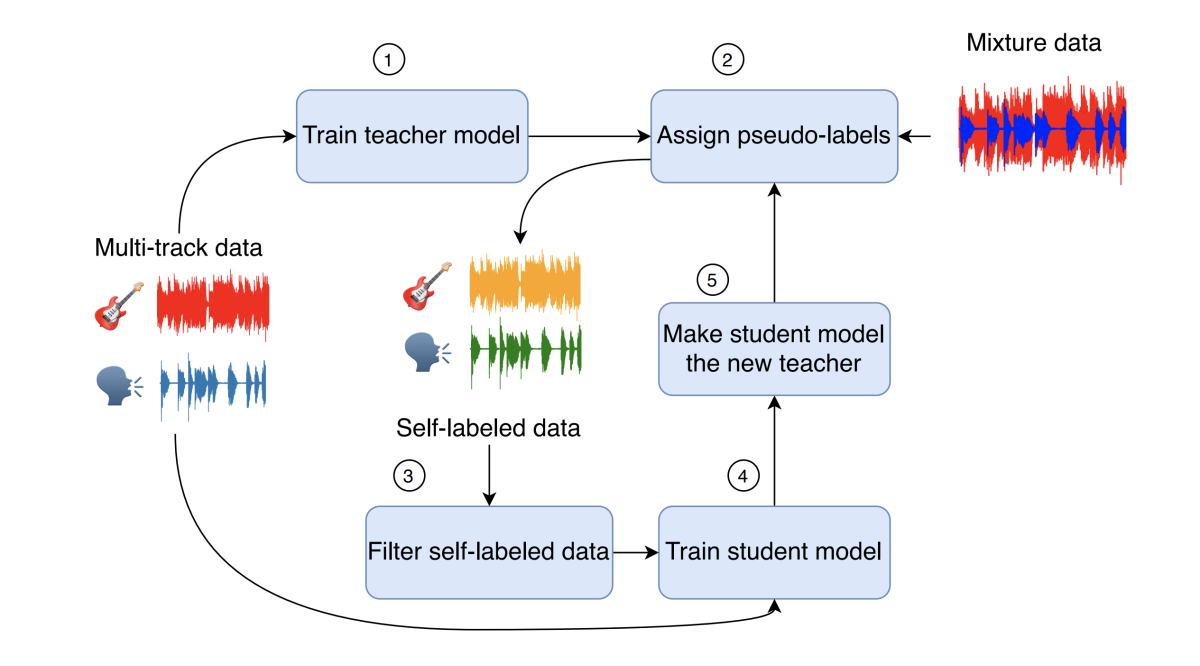
Another paper investigates the topic of singing voice separation, or separating vocal tracks from instrumental tracks in song recordings:
- Semi-supervised singing voice separation with noise self-training
Zhepei Wang, Ritwik Giri, Umut Isik, Jean-Marc Valin, Arvindh Krishnaswamy
Finally, two of Amazon’s ICASSP papers, although they do evaluate applications in speech recognition and audio classification, present general machine learning methodologies that could apply to a range of problems. One paper investigates federated learning, a distributed-learning technique in which multiple servers, each with a different, local store of training data, collectively build a machine learning model without exchanging data. The other presents a new loss function for training classification models on synthetic data created by transforming real data — for instance, training a sound classification model with samples that have noise added to them artificially.
- Cross-silo federated training in the cloud with diversity scaling and semi-supervised learning
Kishore Nandury, Anand Mohan, Frederick Weber - Enhancing audio augmentation methods with consistency learning
Turab Iqbal, Karim Helwani, Arvindh Krishnaswamy, Wenwu Wang
Also at ICASSP, on June 8, seven Amazon scientists will be participating in a half-hour live Q&A. Conference registrants may submit questions to the panelists online.



