
As natural-language processing (NLP) has become more integral to our daily lives, the ability to accurately evaluate NLP models has grown in importance. Deployed commercial NLP models must be regularly tested to ensure that they continue to perform well, and updates to NLP models should be monitored to verify that they improve upon their previous settings.
Ideally, model evaluation would be automatic, to save time and labor. But in the field of question answering, automatic model evaluation is difficult, since both questions and answers might be phrased in any number of different ways, and answers must be judged on their ability to satisfy customers’ information needs, which is a difficult concept to quantify.
At this year’s meeting of the North American chapter of the Association for Computational Linguistics (NAACL), we presented the first machine learning models that can check the correctness of long answers to any type of questions. We call our approach AVA, for Automatic eValuation Approach.
In one set of experiments, we used AVA to evaluate the correctness of answers provided by several different question-answering models and compared the results to human evaluations. Relative to human judgment, the best-performing version of AVA — which uses a novel peer attention scheme that we present in the paper — had an error rate of only 7%, with 95% statistical confidence.
To train our models, we also developed a new dataset, each of whose training examples consists of a question and two different answers in natural language. One of the answers — the reference answer — is always correct, while the other answer is labeled as either true or false. The dataset includes more than two million triplets of question, reference answer, and candidate answer.
Polymorphic problem
Other NLP applications have benefited from automatic evaluation methods. Machine translation research, for instance, commonly measures translation accuracy using BLEU scores, which measure the similarity between the output of a machine translation model and a reference translation.
But this type of approach doesn’t work for question answering. With translation, the input text corresponds to the output text; with question answering, it doesn’t. And in question answering, the output text — the answer — can vary widely, while still conveying the same information.
Furthermore, in question answering, the essential concern is whether the answer is correct. Structurally, an answer candidate could look exactly like a reference answer, differing only in the vital piece of information that determines its correctness. These two considerations make evaluation of question-answering models more difficult than evaluating some other NLP models.
Models
In our NAACL paper, we consider four different machine learning models for evaluating question-answering accuracy. The first is a simple linear model, and the other three are neural-network models based on the Transformer language model.
We consider question-answering approaches with answer selection components, in which a Web search based on the text of a question returns a large number of documents, and the answer selection model ranks sentences extracted from those documents according to the likelihood that they answer the question.
As inputs, all four models take a question, a reference (correct) answer, and a candidate answer.
One of the four is a linear model, which we use because it is more easily interpretable than neural models. It takes an additional input that the other models don’t: a short version of the reference answer (say, “39 million” instead of “the resident population of California had increased to 39 million people by 2018”).
Using a variation of Jaccard similarity, the linear model computes pairwise similarities between the short answer and the candidate answer, the reference answer and the candidate answer, the reference answer and the question, and the candidate answer and the question. It also scores the candidate answer according to how many words of the short answer it contains. Each of these measures is assigned a weight, learned from the training data, and if the weighted sum of the measures crosses some threshold — also learned from data — the model judges the candidate answer to be correct.
The other three models use pretrained Transformer-based networks, which represent texts — and relations between their constituent parts — as embeddings in a multidimensional space. As input, these networks can take pairs of sentences, transforming them into embeddings that reflect linguistic and semantic relations learned from training data.
In the first of our Transformer-based models, we consider three different types of input pairs: question-reference, question-candidate, and reference-candidate. We also consider a model that concatenates the representations of those three pairs to produce a representation of all three inputs. In four different experiments, we train classifiers to predict answer sentence accuracy based on each of these four representations.
In our second Transformer-based models, we pair each text with a concatenation of the other two. Again, we concatenate the other three embeddings to produce an overall representation of the input data.
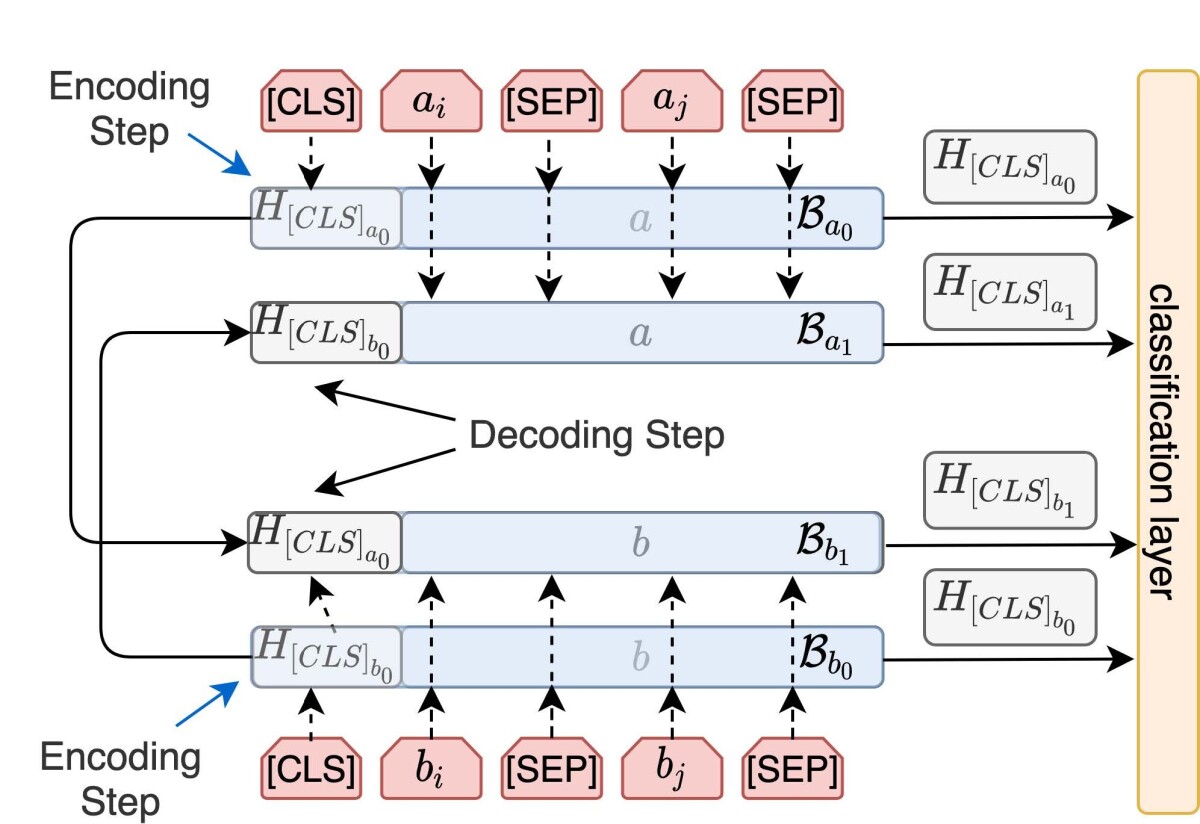
Finally, our third model uses our novel peer attention mechanism. This model takes two pairs of input sentences, rather than one. As with the second model, each pair includes one sentence and a concatenation of the other two.
As indicated in the figure above, the embedding of each pair is conditioned on the embeddings of the other pair before passing to the classifier. This enables the model to better exploit commonalities in the relations between different kinds of sentence pairs — using similarities between question and reference answer, for instance, to identify similarities between reference and answer candidate.
Evaluation
We tested our approach on several different pretrained answer selection models. The inputs to each of our evaluation models included the source question, the reference answer, and the answer predicted by one of the answer selection models.
The evaluation model that used our peer attention mechanism offered the best performance, achieving an F1 score of almost 75% in predicting human annotators’ judgements about whether an answer was correct or incorrect. (The F1 score is a measure that factors in both false-positive and false-negative rate.)
Additionally, we aggregated AVA’s judgments over the output of different question-answering models run on our entire test set (thousands of questions). This provided estimates of the different models’ accuracy (percentage of correct answers). Then we compared those estimates to a measure of accuracy based on human judgements, again on the entire test set. This allowed us to compute the overall AVA error rate with respect to human evaluation, which was less than 7% with 95% statistical confidence.



