
Scene boundary detection is the problem of localizing where scenes in a video begin and end. It’s an important step towards semantic understanding of video, with applications in scene classification, video retrieval and search, and video summarization, among other things.
In a paper we presented at this year’s Conference on Computer Vision and Pattern Recognition (CVPR), we described ShotCoL, a new self-supervised algorithm for scene boundary detection.
In terms of average precision, ShotCoL improves upon the previous state of the art in scene boundary detection on the MovieNet dataset by 13% while remaining data efficient and lightweight. It is 90% smaller and 84% faster than previous models and requires 75% less labeled data to match the previous state-of-the-art performance.
These improvements come largely from self-supervised learning, a learning method that can make use of large amounts of unlabeled data. In particular, we used contrastive learning, in which a model learns to distinguish similar and dissimilar examples via a pretext (or surrogate) task, which is related to the task at hand but not identical to it.
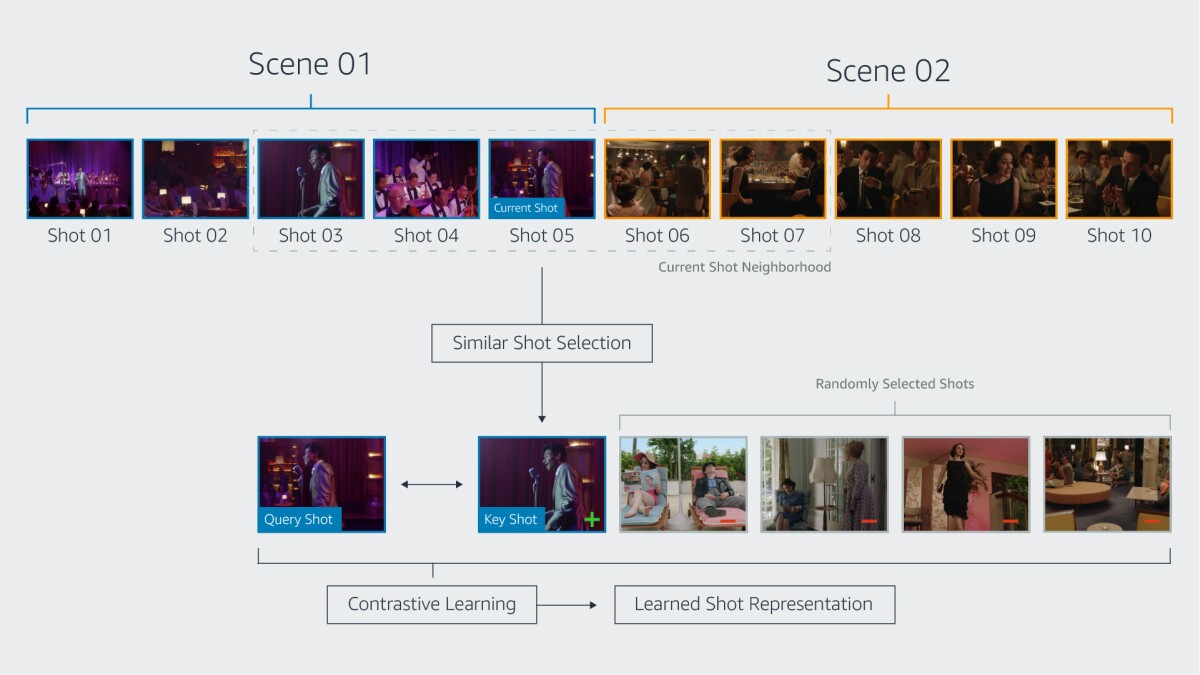
A scene in a film or TV show is a series of shots depicting a semantically cohesive part of a story, while a shot is a series of frames captured by the same camera over an uninterrupted period of time. Accurate scene boundary detection is challenging for existing models, while accurate shot detection is not. Thus, in our work, we formulate the problem of scene boundary detection as a binary classification task: every shot boundary is either a scene boundary as well, or it isn’t.
In the past, researchers using contrastive learning for image classification have generated examples of similar images through image augmentation: the query image might be flipped, for instance, and its color scheme altered to produce a positive key. ShotCoL, by contrast, leverages temporal relationships as well as visual similarity when finding positive examples.
In particular, for a given query shot, our pretext task defines the corresponding positive key as the most similar shot — measured by cosine similarity in the feature space — within a local neighborhood of shots. Over the course of training, our model learns an embedding that tends to group query shots and their corresponding positive key shots together, while separating dissimilar shots.
In our experiments, using nearest neighbors as positive keys proved more successful than other ways of choosing key shots, such as selecting the shot that immediately precedes or follows the query. Successive shots in a single scene can vary so greatly that the model can’t learn relationships that will allow it to generalize well to new inputs.

The goal of self-supervised learning is to learn an embedding that can be useful for downstream tasks — in our case, scene boundary detection. Once we’ve used self-supervised learning to train the embedding network, we freeze its weights and use the encoder to produce embeddings for a sequence of shots. In a supervised fashion, the embeddings are then used to train a classification model that outputs a binary decision about whether the middle shot in a sequence of shots is the end of a scene.
As mentioned above, ShotCoL improves the state-of-the-art average precision on the MovieNet dataset by more than 13% while remaining lightweight and data efficient. For more results, please see our full paper.
We believe that the insights provided by our work will lead to further advances in long-form-video-representation learning and benefit other tasks that require higher-level understanding of content, such as action localization, movie question answering, and search and retrieval. Moving forward, we will continue to strive to create the best viewing experience possible for Prime Video customers and push the envelope of research in multimodal video understanding.



