
Deep-learning models rely centrally on algebraic operations involving tensors — higher-dimensional analogues of matrices — that might be repeated tens of thousands of times. Efficient learning requires optimizing frequently repeated tensor operations.
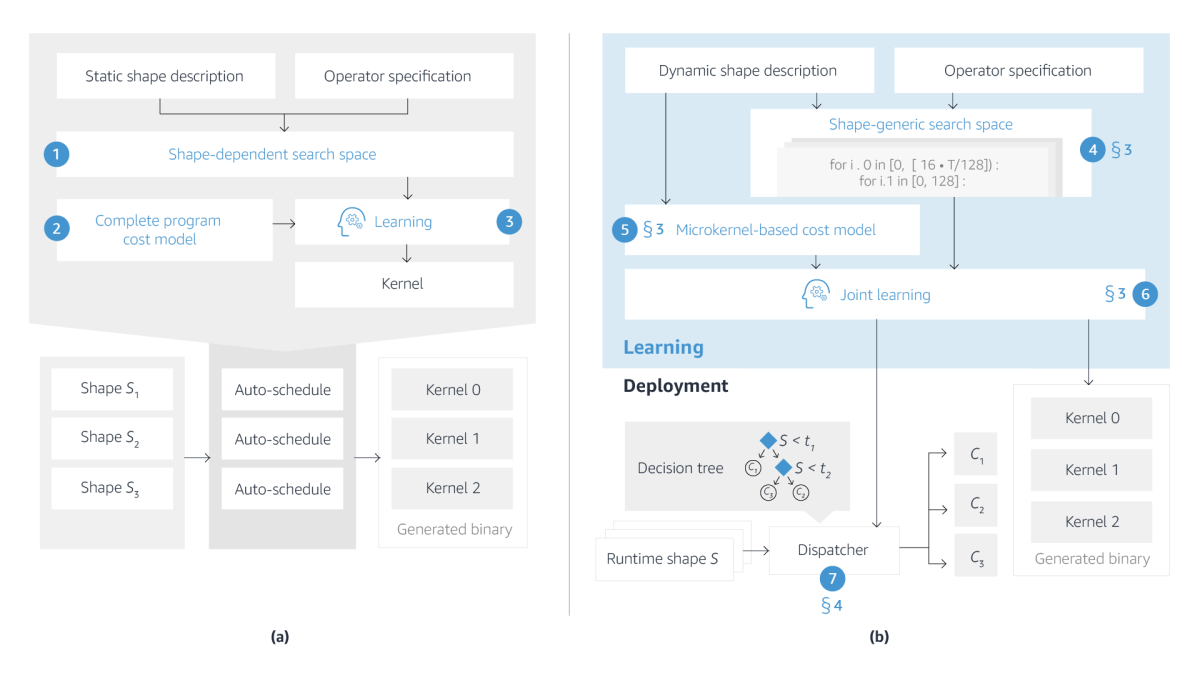
But operations involving tensors of different shapes — 32x32, 64x64, 128x128, etc. — have to be optimized individually. Auto-schedulers are programs that learn optimizations for shapes whose implementations may be suboptimal in current tensor operation libraries.
Existing auto-schedulers struggle, however, with workloads whose shapes vary. Many natural-language-processing applications, for instance, take inputs of arbitrary length, which means tensors of arbitrary shape.
At this year’s Conference on Machine Learning and Systems (MLSys), we and our colleagues presented a new auto-scheduler called DietCode, which handles dynamic-shape workloads much more efficiently than its predecessors. Where existing auto-encoders have to optimize each possible shape individually, DietCode constructs a shape-generic search space that enables it to optimize all possible shapes simultaneously.
We tested our approach on a natural-language-processing (NLP) task that could take inputs ranging in size from 1 to 128 tokens. When we use a random sampling of input sizes that reflects a plausible real-world distribution, we speed up the optimization process almost sixfold relative to the best prior auto-scheduler. That speedup increases to more than 94-fold when we consider all possible shapes.
Despite being much faster, DietCode also improves the performance of the resulting code, by up to 70% relative to prior auto-schedulers and up to 19% relative to hand-optimized code in existing tensor operation libraries. It thus promises to speed up our customers’ dynamic-shaped machine learning workloads.
Dynamic workloads
NLP models that handle text strings of arbitrary length are examples of dynamic-by-design models, which allow variably sized inputs. But other applications also call for dynamic workloads.
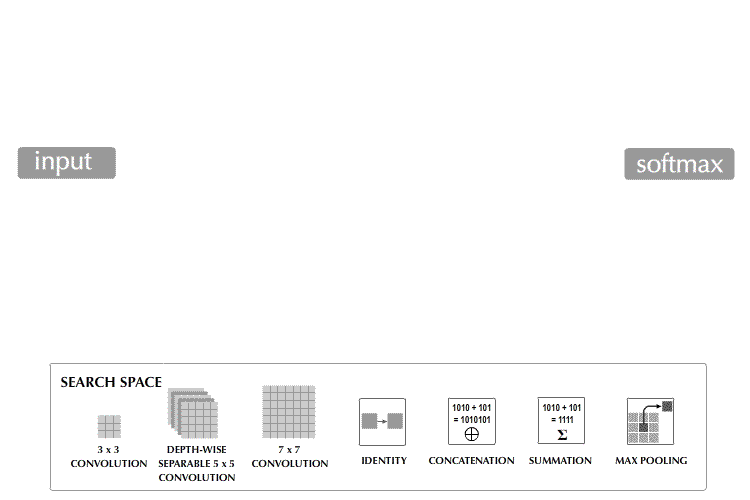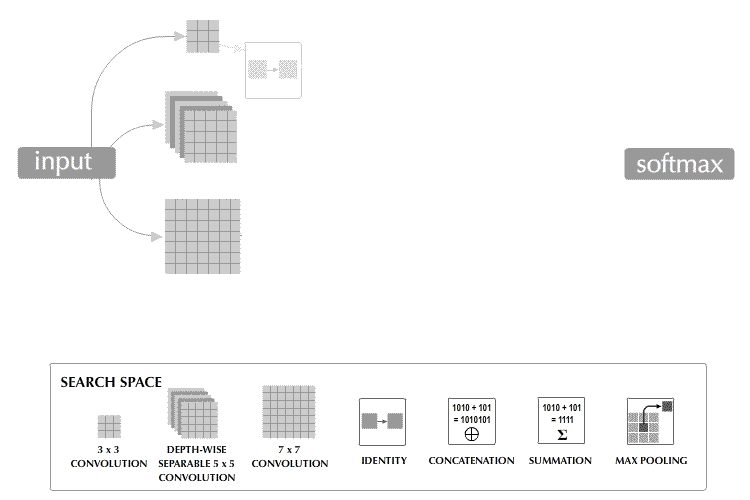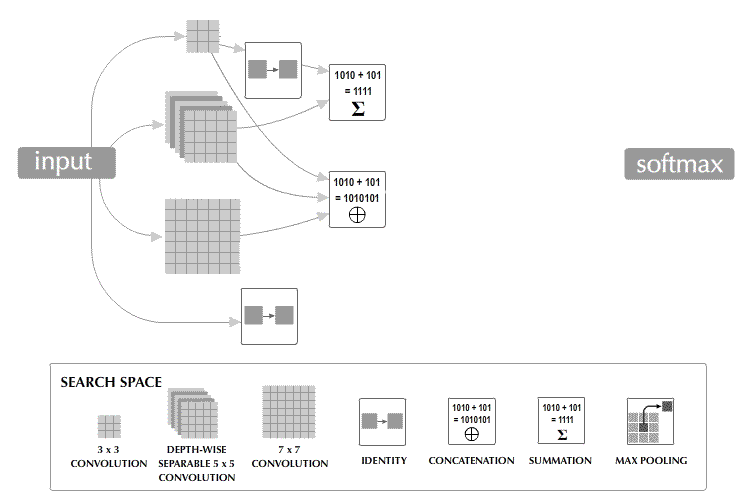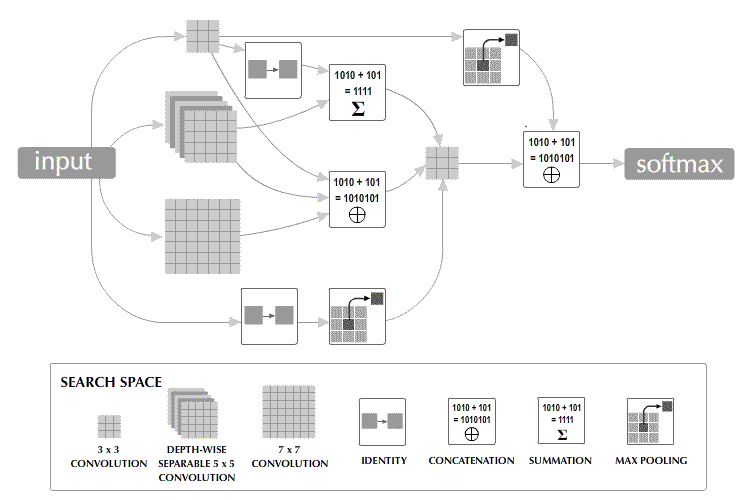
Neural-architecture search, for instance, tries out different deep-learning architectures by building them up from different-shaped components, which requires operations on different-shaped tensors. And some models — the BERT language model, for instance — applies the same operation at different layers of a network, which have different numbers of nodes.
Microkernels
Auto-schedulers typically rely on computational kernels — program templates whose use greatly accelerates the speed with which different candidate optimizations can be evaluated. Odd-shaped workloads, however, may not fit the kernels precisely. For instance, if a tensor has 513 elements along one of its dimensions, but the kernel capacity is only 512, then two kernels must be tiled together in order to accommodate the tensor.
The tiled kernels, however, have a combined capacity of 1,024 along the relevant dimension, compared to only 513 for the input tensor. The input tensor thus has to be padded out in order to fill the kernel. This padding can slow down the optimization process dramatically, as it leads to unnecessary calculations that then have to be pruned out of the result.
DietCode uses microkernels that are sized according to the available hardware, not the input shape, which aids in optimization for that hardware. For a given hardware configuration, DietCode can also generate a range of different microkernel shapes and sizes, which can be used in combination.
The microkernels are small enough that they can usually be tiled across an input, to fit its shape more precisely. This may still require some padding at the edges, but much less than larger kernels require.
The real advantage of microkernels, however, is that they enable DietCode to optimize operators for multiple shapes at once. A standard auto-scheduler will take a workload shape, pad it as necessary to fit its tiled kernels, and then estimate the efficiency of different implementations using a cost model that extracts program features such as loop structures and memory access patterns. Then it will repeat that process for the next shape.
DietCode, by contrast, breaks operators up across microkernels. The cost model has two components: one that evaluates features of the partial operation assigned to each microkernel and one that evaluates the cost of stitching those partial operations together to form a complete operator.
Here is where we realize our greatest gains in efficiency, because each partial operation is a component of operators for multiple workload shapes. Compared to the computational cost of evaluating operations — which is a machine learning process that involves real hardware measurements — the cost of stitching partial operations together is low.
With our optimized microkernels in hand, we train an efficient decision tree model to map workload shapes to microkernels. That decision tree is incorporated into the binary file for the execution of the tensor operations, to route inputs of arbitrary shape to the proper microkernels for processing.
For experimental results and more details, please refer to our paper.
Acknowledgements: Cody Yu, Yizhi Liu, Gennady Pekhimenko



