
We are excited to announce that we are open-sourcing causal machine learning (ML) algorithms that are the result of years of Amazon research on graphical causal models. The algorithms enable a variety of complex causal queries in addition to the usual effect estimation, including but not limited to root-cause analysis of outliers and distribution changes, causal-structure learning, and diagnosis of causal structures. Internally, they have been used by Amazon teams ranging from Supply Chain to Amazon Web Services (AWS).

We are also excited that, in a joint effort with Microsoft, we have created a new GitHub organization called PyWhy. PyWhy serves as the new home of DoWhy, a causal ML library from Microsoft, which we are merging our algorithms into. DoWhy is one of the most popular causality libraries on GitHub. Amazon and Microsoft are delighted to be working together with the community of DoWhy users and contributors. As our colleague Amazon principal scientist Dominik Janzing said, "It's exciting to see our team’s work of the last three years shared with the whole scientific community."
Graphical causal models
Most real-world systems, be they distributed-computing systems, supply chain systems, or manufacturing processes, can be described using variables that may or may not exert causal influence on each other.
Think, for instance, of a microservice architecture consisting of many different web services. What is the cause of increased website loading times? Is it a slow database in the back end? A malfunctioning load balancer? A slow network?
Existing libraries for causality, including DoWhy, focus on various types of effect estimation, where the general goal is to identify the effect of interventions on some target variable. In the case of a microservice architecture, they would help answer questions like “If I make this change in my caching service configuration, will it improve the website loading times, or will it make them worse?”
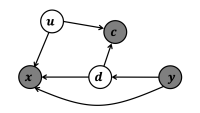
Our contribution complements DoWhy’s existing feature set by leveraging the power of graphical causal models (GCMs). GCMs are a formal framework developed by Turing Award winner Judea Pearl to model cause-effect relationships between variables in a system. A key ingredient of GCMs is the causal diagrams, which visually represent the cause-effect relationships among the observed variables, with an arrow from a cause to its effect.

Each variable in a causal diagram has its own causal mechanism, which describes how its values are generated from the values of its parents. We can train probabilistic models to learn these causal mechanisms and use them to attribute anomalous events or changes in mechanisms to specific nodes. This decomposition into contributions of mechanisms is the core idea behind our novel algorithms for root-cause analysis.
As an example, in the microservice architecture mentioned above, we might accidentally be deploying a defective service, which uses a suboptimal SQL query to get data from the database, increasing website latencies. Using a feature we call “distribution change attribution”, we can identify the defective service.

But GCMs can do more: they can be used to compute the effects of interventions, estimate counterfactuals, compute the direct and intrinsic influences of nodes on their descendants, or attribute anomalies to potential upstream root causes. By releasing our algorithms, we hope to make these tools available to a broader audience of researchers and practitioners and help advance the scientific methods around GCMs.
PyWhy
For effect estimation, DoWhy already uses two of the most popular scientific frameworks for causal inference — graphical causal models and potential outcomes — and combines them in one library. With our contribution, we hope we can drive the synergy between the frameworks and their dedicated research communities further.
But our long-term vision goes beyond DoWhy, potential outcomes, and GCMs. This is reflected in our effort to create PyWhy and our commitment to help steer the direction of this new GitHub organization. We welcome others to join our efforts and become part of the community.
Our hope and ambition for PyWhy — as its mission states — is to “build an open-source ecosystem for causal machine learning that moves forward the state of the art and makes it available to practitioners and researchers. We build and host interoperable libraries, tools, and other resources spanning a variety of causal tasks and applications, connected through a common API on foundational causal operations and a focus on the end-to-end-analysis process.”

So if you are a scientist working on causal ML problems or are curious about them, visit py-why.github.io/dowhy/gcm to learn more about the new GCM features in DoWhy or browse the source code on github.com/py-why/dowhy.
If you’re the owner of a causal ML library and think your library would be a good fit for PyWhy, visit github.com/py-why to learn more about this new organization, or come talk to us on Discord.
Acknowledgments: Patrick Bloebaum, Dominik Janzing



