
Modern AI models, such as those that recognize images and speech, are highly data dependent. While some public-domain data sets are available to train such models, user data collected from live operational systems is crucial to achieving the volume and close match between training and test conditions necessary for state-of-the-art performance.
This raises the issue of how to protect the privacy of user data used for training. Differential privacy (DP) aims to prevent inferences about the makeup of a model’s training data by adding random variations (noise) into the training process to mask the specifics of the training inputs.
At the IEEE Spoken Language Technology Workshop (SLT) this week, we, together with our Amazon colleague I-Fan Chen, as well as Chin-Hui Lee and Sabato Siniscalchi of Georgia Tech, presented the paper “An experimental study on private aggregation of teacher ensemble learning for end-to-end speech recognition”. It is one of the first comparative studies of DP algorithms as applied to modern all-neural automatic-speech-recognition (ASR) models.
We also show that a DP algorithm not previously used for ASR can achieve much better results than a common baseline method. In our experiments, given a particular DP constraint, our method reduced word error rate by more than 26% relative to the baseline.
Differential privacy
How do we prevent a malevolent actor from inferring details about the training data that contributed to the creation of an AI model, either by observing or probing that model or, worst case, by disassembling it to extract the system’s internal parameters? In the case of speech recognition systems, that type of privacy attack might try to infer either the identity of the speakers whose inputs were used in training or the inputs themselves.
DP’s answer is to inject noise into the training process, to obscure the inferential path between input-output relationships and particular training examples. There is an inherent correlation between the amount of noise injected and the achieved privacy guarantees, and the addition of noise usually degrades model accuracy.

Different DP methods have different trade-offs, and the challenge is to inject noise in a way that conceals information about individual data items while minimizing accuracy degradation. Privacy guarantees are quantified by a parameter, ε, which describes our certainty that two models that differ in a single item of their training data cannot be told apart. A value of ε = 0 means maximum differential-privacy protection, with increasingly positive values of ε denoting less and less differential privacy. Achieving smaller values of ε requires more noise injection.
Stochastic gradient descent (SGD) is the method commonly used for training neural models; gradients are adjustments to model parameters designed to improve accuracy on a specific batch of training examples.
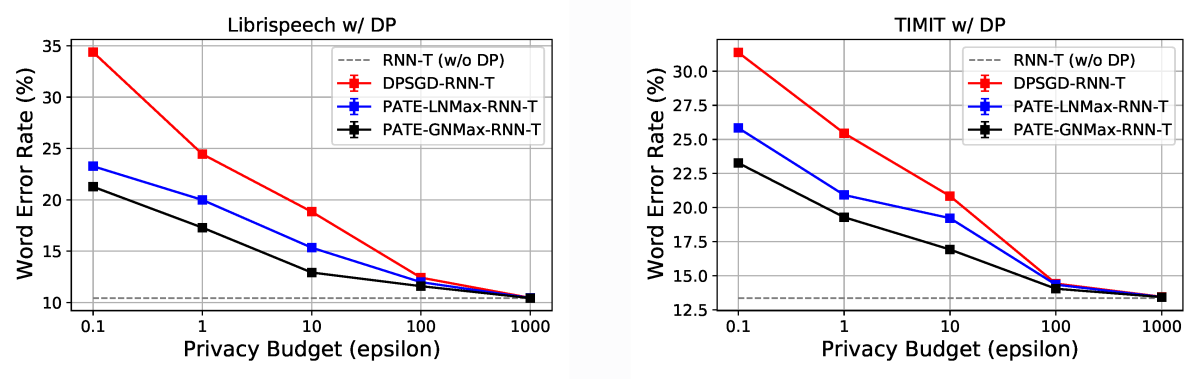
A standard and intuitive way to implement DP for neural models is to add noise to the gradients. However, when applied to ASR, this modified version of SGD (known as DP-SGD) can lead to dramatic performance penalties. Our comparative study found a more than threefold increase in word error rate for a strict privacy budget (ε = 0.1).
PATE for ASR
To mitigate this performance degradation, we adopt a framework called private aggregation of teacher ensembles (PATE), which was originally shown to be effective on image classification tasks. The idea is to use student-teacher training, also known as knowledge distillation, to decouple the training data from the operational model.
The sensitive data is partitioned, and a separate teacher model is trained from each partition. The teacher models are aggregated by weighted averaging to then label a nonsensitive (e.g., public) training set, on which the operational (student) model is trained.

We achieve DP by adding Laplacian or Gaussian noise to the predictions of the teacher models prior to averaging. Averaging ameliorates the performance degradation resulting from noisy relabeling: after averaging, the student model can still apply the right label, but an attacker cannot use it to identify features of the training data.
We examine several popular neural end-to-end ASR architectures and consider training scenarios where sensitive and nonsensitive data have similar characteristics or are drawn from different types of speech sources.
According to our study, the RNN transducer (RNN-T) architecture is the one that offers the best privacy trade-offs on ASR tasks, so that’s the architecture we used in our experiments. On the standard LibriSpeech task, our PATE-based model’s word error rate is 26.2% to 27.5% lower than that of the DP-SGD model, relative to a baseline RNN-T model that was not affected by DP noise.
We also demonstrate that PATE-ASR prevents the reconstruction of training data using model inversion attacks (MIA). Given access to a trained model and an output of interest, this form of privacy attack finds the input to the model that maximizes the posterior probability of the given output. In the case of speech recognition, MIA could potentially reconstruct the acoustic inputs corresponding to a string of putatively spoken words, possibly revealing features of the speakers used in training. The spectrograms below depict an original utterance and its reconstruction using MIAs against RNN-T models that have different levels of privacy protection.
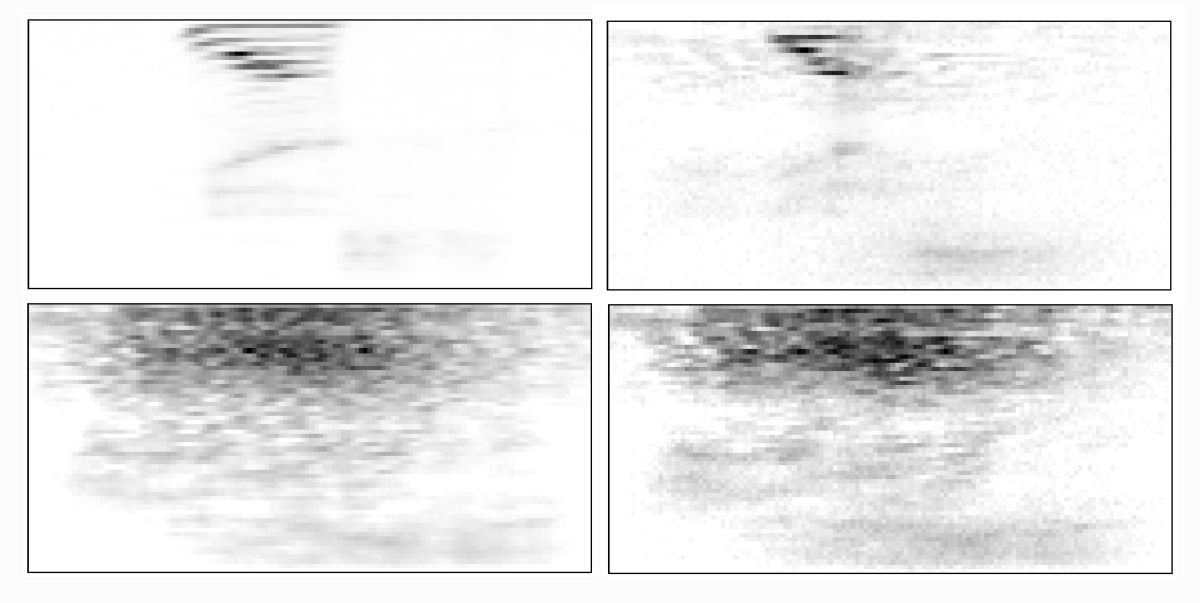
We see clearly that ASR models trained using PATE-DP effectively hide such acoustic information from MIAs, unlike models trained without DP. The results demonstrate the promise of privacy-preserving ASR models as a pathway toward designing more reliable voice services.
Acknowledgments: This is joint work between Alexa scientists and the former Amazon Research Awards recipient Chin-Hui Lee from the Georgia Institute of Technology, with valuable leadership and suggestions from Ivan Bulyko, Mat Hans, and Björn Hoffmeister.



