
Recent foundation models — such as large language models — have achieved state-of-the-art performance by learning to reconstruct randomly masked-out text or images. Without any human supervision, these models can learn powerful representations from large corpora of unlabeled data by simply “filling in the gaps”.

Generalizing this approach to video data is not straightforward, however. If the masking is random, the model may be able to look at frames adjacent to the current one to fill in gaps. If, on the other hand, a fixed region is masked in successive frames, the model might learn to reconstruct background rather than people and objects, due to camera motion. These shortcuts may reduce the quality of the learned representation and thus of the performance on downstream tasks, such as video action recognition.
At this year’s International Conference on Computer Vision (ICCV), Prime Video presented a new masking algorithm for masked video modeling called motion-guided masking (MGM). MGM produces masks that track motion across successive frames of video to ensure the semantic consistency of the masked regions and increase the difficulty of the reconstruction task.
Crucially, our approach leverages motion vectors that are already part of modern video compression algorithms rather than optical flow, which is expensive to compute on the fly. This enables highly scalable self-supervised training of large video models.
In experiments, we found that MGM could achieve state-of-the-art video representations using only a third as much training data as the best-performing prior model. We also tested the representations produced by our model on several downstream tasks and found that they improved performance by as much as 5% over the previous methods.
Semantic representation
Foundation models learn to map input data to vectors in a representational space, where geometric relationships between vectors correspond to semantic relationships between data. Masked training enables the models to learn those semantic relationships directly from the data, without the need for human involvement. The goal is to produce generic representations useful for an infinite variety of downstream tasks.

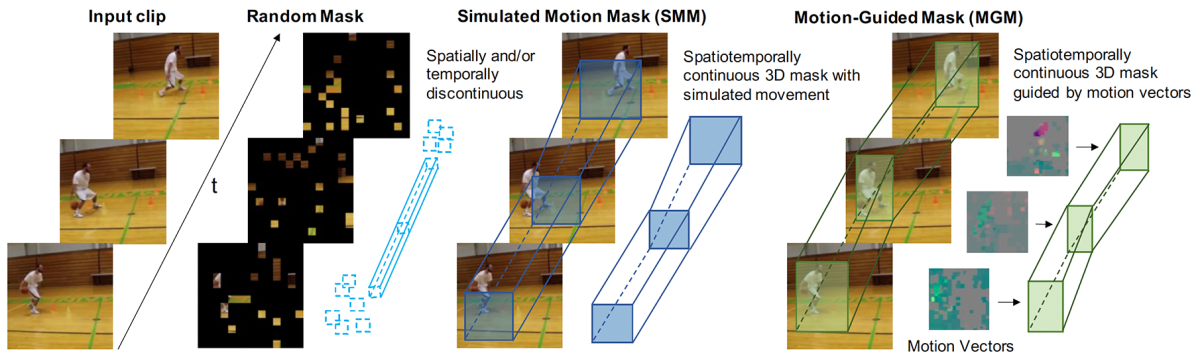
The most meaningful elements of a video sequence are usually people and objects. A mask that doesn’t track those semantic units over time may ignore useful information and lead to noisier learned representations. The goal of our work is thus to produce a “motion-guided” mask that tracks these semantic units over time.
One naïve way to achieve this would be to run an object detector per-frame, select an object at random, and mask out the bounding box that surrounds that object in each frame. But computationally, this would be extremely expensive.
Fortunately, modern video compression schemes already contain information that can be used to estimate motion from frame to frame, and our method uses that information directly, dramatically reducing the computational burden.
Motion vectors
Digital video generally plays at rates between 24 and 30 frames per second. Rather than storing the color value of every pixel per frame, modern video codecs compress the video by exploiting the fact that, generally, most of the video changes gradually from frame to frame.
The encoded version of a video consists of intracoded frames (I-frames), which are conventional digital images; motion vectors, which define how 8-by-8 (or 16-by-16) blocks of pixel values in the I-frames move from frame to frame; and residuals, which update individual pixel values that can’t be recovered from the comparatively coarse motion vectors. If the motion vectors are sparsely assigned to 8-by-8-pixel blocks, they require only 1/64th as much memory as conventional images. This sparsity means that encoded video files can be stored more efficiently than fully decoded RGB frames can.

We leverage the design of modern video codecs to obtain efficient motion information. Motion vectors encode the offsets for pixel blocks in two dimensions. In our paper, we analyzed the average motion of the foreground and background in popular Internet video datasets and found that on average, motion was higher in the foreground.
We thus use motion vectors as a proxy for determining the regions of interest to mask. Our MGM algorithm masks a rectangular region around the highest motion per frame, and the model is asked to reconstruct this 3-D volume of masked video.
In our experiments, we compared MGM to six previous masked-video approaches. All of those approaches used random masking, which is not spatiotemporally continuous. In our ablation studies, we also tested other masking schemes that have varying degrees of spatiotemporal continuity and motion guidance, to capture the extent to which motion guidance helps improve video representation learning.
We evaluated MGM on two different datasets, using the trained model to predict masked-out image features in an evaluation dataset, and found that it outperformed the prior masked-video schemes across the board. It could also match the performance of the previous best-performing method after training on only one-third as much data.
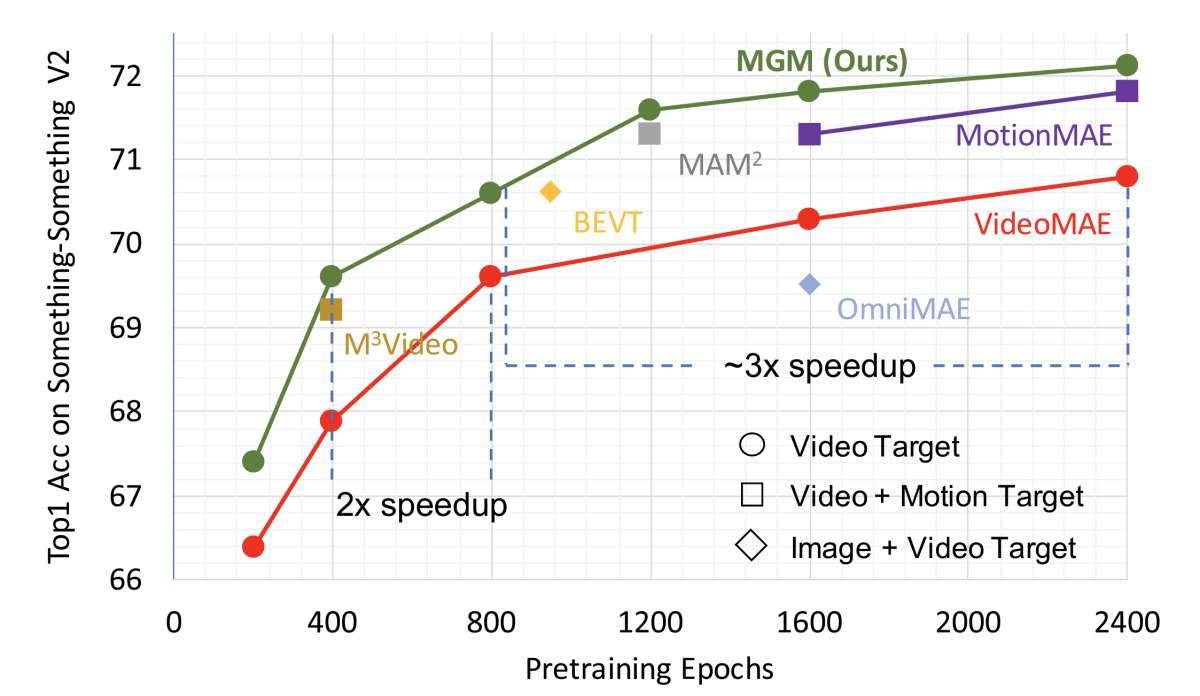
We then compared representations generated using our approach to the random-masking baseline on three other tasks, obtaining relative improvements of up to 5%. This suggests that motion-guided masking is better at capturing semantic information about video content than other video-masking techniques.
In summary, we propose MGM, a motion-aware masking algorithm for video that leverages efficient motion guidance already present in popular video formats, to improve video representation learning. For more details, please see our ICCV 2023 paper.



