
Machines hoping to converse convincingly with humans have several natural-language-processing (NLP) skills to master, including text summarization, information extraction, and question answering. It’s these skills that enable virtual personal assistants to search for dinner recipes online or answer random questions.
Recent advances in sequence-to-sequence pretrained language models such as BART (bidirectional autoregressive Transformers) have led to great performance on many NLP tasks. These models’ successes, however, come at the cost of significant computation and memory resources; a typical BART model might have hundreds of millions of parameters.
For resource-constrained devices — such as cell phones or smart home appliances — this can make BART totally unusable. At ACL 2022, scientists from Amazon Web Services’ AI Labs presented a paper that addresses this problem by using a combination of distillation and quantization to compress a BART model to less than 1/16th its size, with little drop in performance.
A two-pronged approach
Quantization, which maps high-precision values to a limited menu of lower-precision values, and distillation, in which a smaller, more efficient student model is trained to emulate a larger, more powerful teacher, are common techniques for reducing neural networks’ memory footprints.
In the new paper, the Amazon researchers combine distillation and distillation-aware quantization to reduce the model’s footprint.
The researchers begin by fine-tuning a BART model — the teacher model — on a particular NLP task, such as question answering or text summarization. They then copy the weights from select layers of the trained teacher model over to a student model. This is the distillation process, which reduces the model footprint.
The next step is distillation-aware quantization. The student model is quantized, producing a low-precision model — although the full-precision student model is also kept on hand, as it’s necessary for the next step in the process.
The quantized student model then processes the dataset that was used to train the teacher model, and its outputs are assessed according to two metrics: the standard task-based loss, which measures how far the outputs diverge from ground truth, and a distillation loss, which measures the difference between the quantized-and-distilled student model and the teacher model.
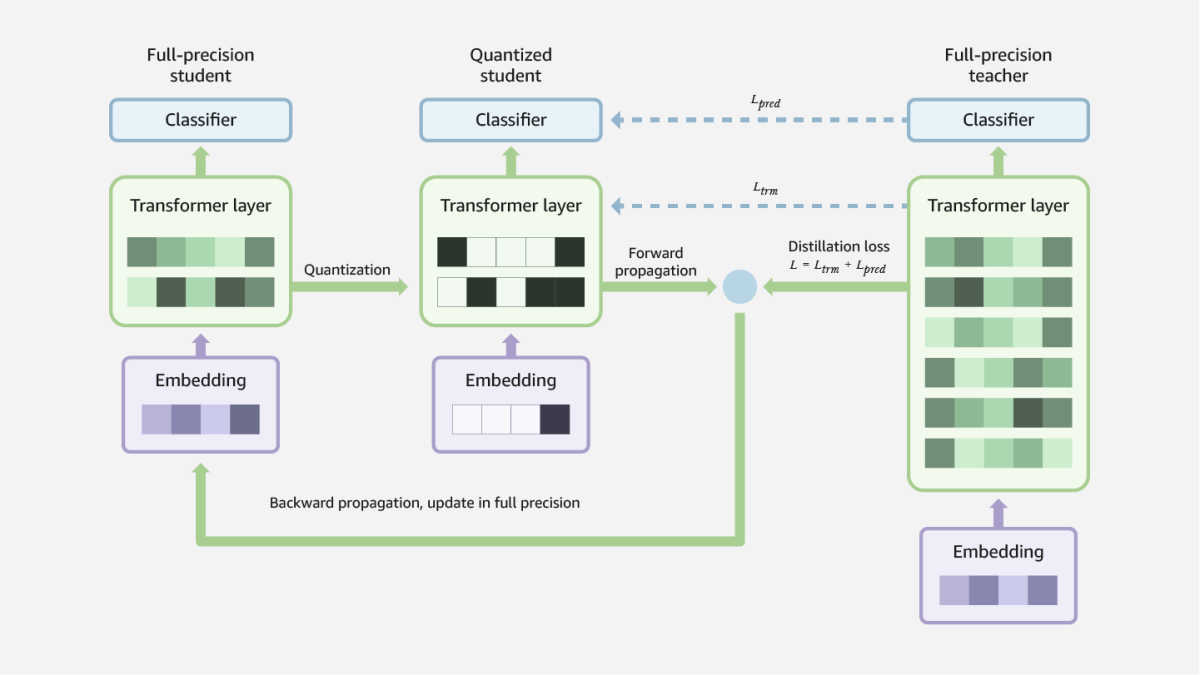
Both of these losses are then used to update the parameters of, not the quantized student model, but the full-precision student model. This is because the standard algorithm for updating a neural network depends on gradient descent, which requires differentiable — that is, continuously variable — model parameters. The parameters of a quantized model have discrete values, so they’re not differentiable.
Once the full-precision student model has been updated — to minimize not only its error on the training set but also its difference from the teacher model — it is quantized once again, to reduce its memory footprint.
Experiments
The researchers compared the efficiency of their distilled and quantized BART model against three different benchmarks, on the tasks of both text summarization and long-form question answering. They also investigated how distillation-aware quantization would work on a more complex model like mBART, a multilingual model designed to translate phrases between languages — in this case, between English and Romanian.
In their initial analysis, they found that combining distillation and quantization provided better compression than quantization alone and resulted in no performance drop for the long-form-question task and minimal dropoff for the summarization task. They also found that it is possible to compress the model to nearly 1/28th its original size. However, at this compression rate, the model has variable performance; the desired degree of compression should be assessed on a task-to-task basis.
For the mBART task, the team found that the distillation-aware approach was effective at compressing the model’s footprint when using eight-bit quantization, but its performance began to drop more significantly when the number of quantization bits was lowered to two. The researchers believe that this performance drop was caused by accumulated distillation and quantization errors, which may be more acute for the complex problem of machine translation.
In future work, the researchers hope to further explore the multilingual mBART model and to evaluate additional compression techniques, including head pruning and sequence-level distillation. As the current study focused on memory footprints, they also plan to expand their study to investigate latency effects.



