
Knowledge distillation is a popular technique for compressing large machine learning models into manageable sizes, to make them suitable for low-latency applications such as voice assistants. During distillation, a lightweight model (referred to as a student) is trained to mimic a source model (referred to as the teacher) over a specific data set (the transfer set).
The choice of the transfer set is crucial to producing high-quality students, but how to make that choice is far from obvious. In natural-language-understanding (NLU) applications, teacher models are usually pretrained on generic corpora, which can differ from the task-specific corpora used for fine-tuning. This raises a natural question: Should the student be distilled over the generic corpora, so as to learn from high-quality teacher predictions, or over the task-specific corpora that aligns better with fine-tuning?

In a paper we presented at the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), we explored this question and showed that models distilled using only task-specific data perform better on their target tasks than those distilled on a mix of task-specific and generic data. In other words, distilling over target domain data provides better performance than banking solely on teacher knowledge.
We confirmed, however, that even distillation on mixed data is beneficial, with students outperforming similar-sized models trained from scratch. We also investigated distillation after the teacher model had been pretrained but before fine-tuning, so that only the student model is fine-tuned. We found that the more costly strategy of adapting the teacher to the transfer set before distillation produces the best students.
Distillation diversity
In our experiments, we distilled a set of multilingual students from a large multilingual teacher model, using generic and task-specific data mixed in three different ratios:
- Ratio 1: generic-only (baseline)
- Ratio 2: 7:3 generic to task-specific (mimicking a low-resource setting)
- Ratio 3: task-specific-only
So what are generic and task-specific data? Generic data is usually publicly available, non-annotated data unrelated to any specific task. Model training on unannotated data typically involves self-supervised learning; in our case, that means masking out words of a text and training the model to supply them (masked language modeling).
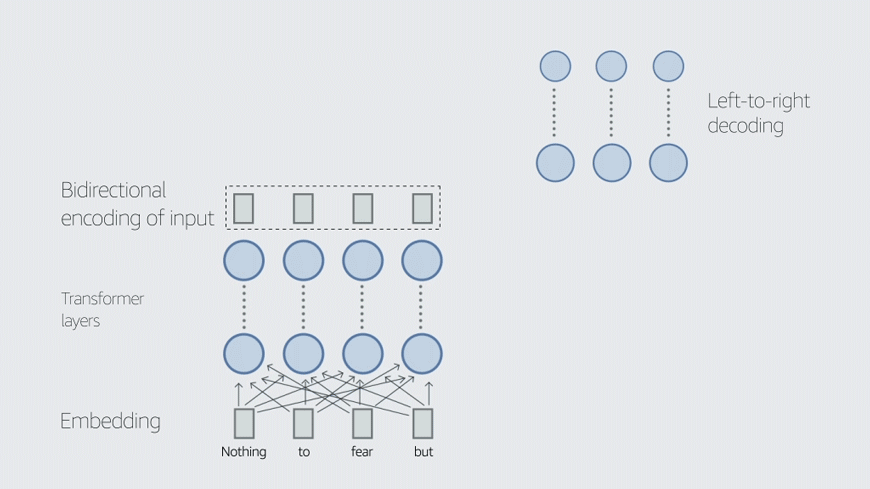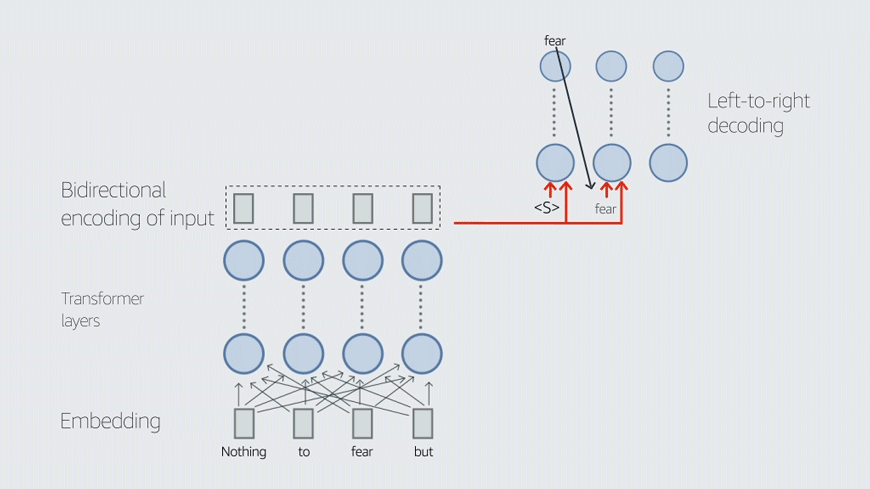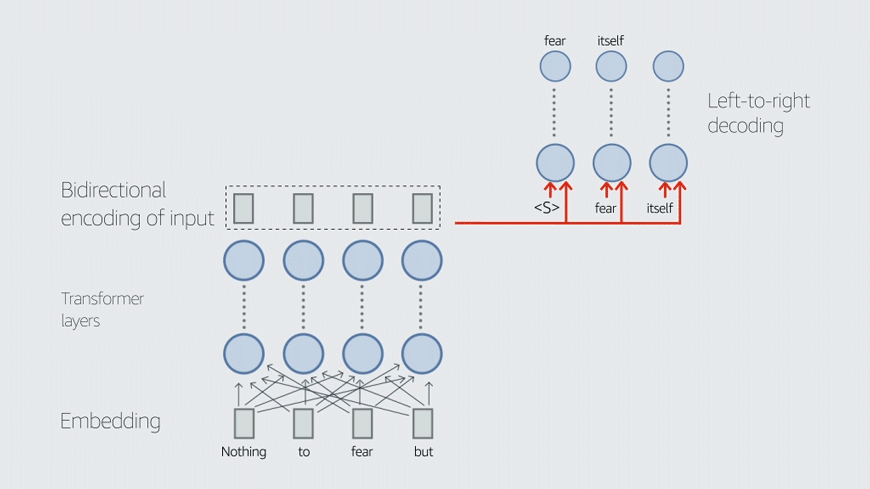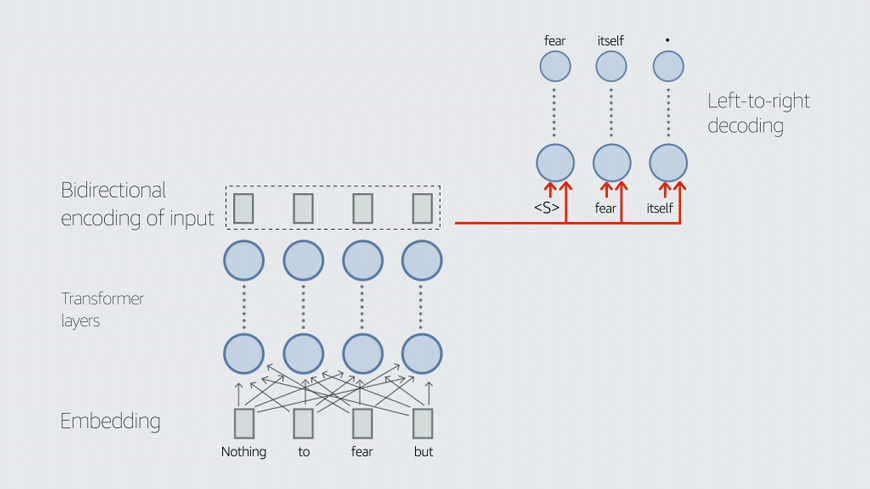
Task-specific data is data that has been annotated to indicate the proper performance of a task. In our case, we explored two downstream tasks, domain classification (DC) and joint intent classification and named-entity recognition (ICNER), and our task-specific data is annotated accordingly.
We evaluated our models on two types of test sets — test and tail_test — and four languages of interest, namely German, French, Italian, and Spanish. The set test comprises the full test split, while tail_test is the subset of data points within test that have a frequency of occurrence of three or less. The tail_test set allows us to measure the generalizability of our models to data that they have rarely seen during training.
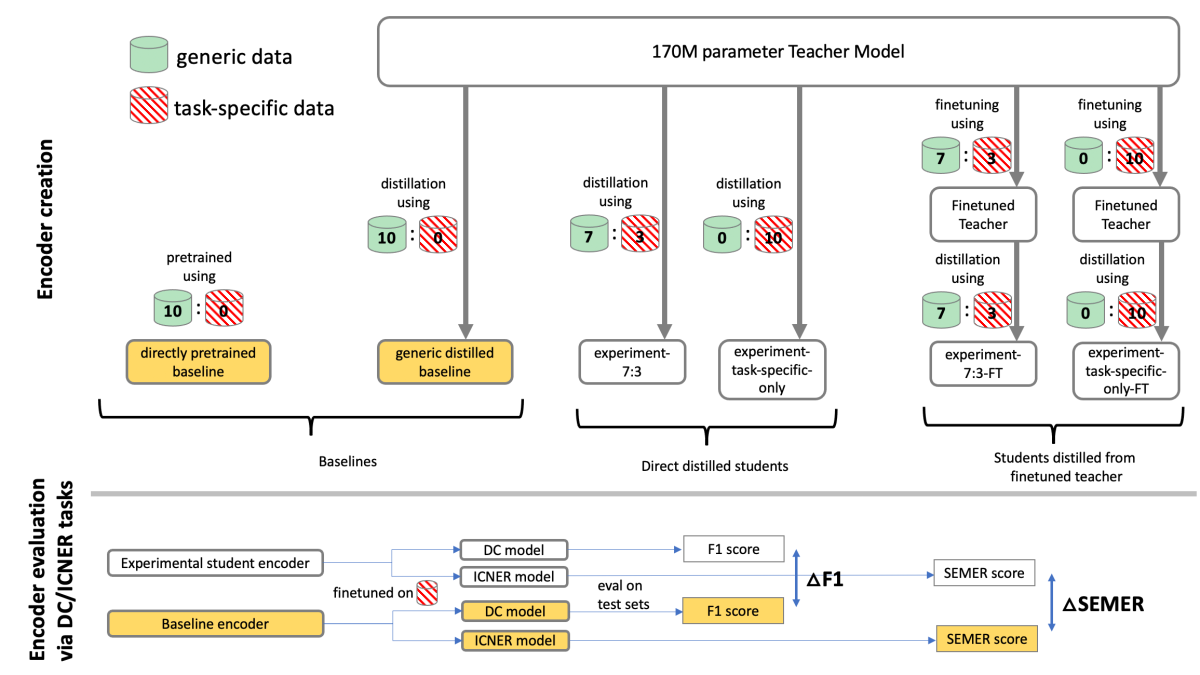
All our experimental and baseline models had the same number of parameters. The generic-distilled baseline was created by distilling a student using only generic data (Ratio 1). The directly pretrained baseline was pretrained from scratch using the generic data and fine-tuned on the task-specific data.

We created four distilled student encoders, two of which were directly distilled using Ratio 2 and Ratio 3 datasets. The remaining two were created in the same way, but the teacher was fine-tuned with the task-specific datasets for a million steps each before distillation. This enabled benchmarking teacher adaptation to the target task.
When evaluating performance for the DC and ICNER tasks, we added either a DC or ICNER decoder to each encoder. Change in F1 score (which factors in both false-negative and false-positive rate) relative to baseline was taken as the improvement for DC, and the change in semantic error rate (SemER) relative to baseline was taken as the improvement for ICNER.
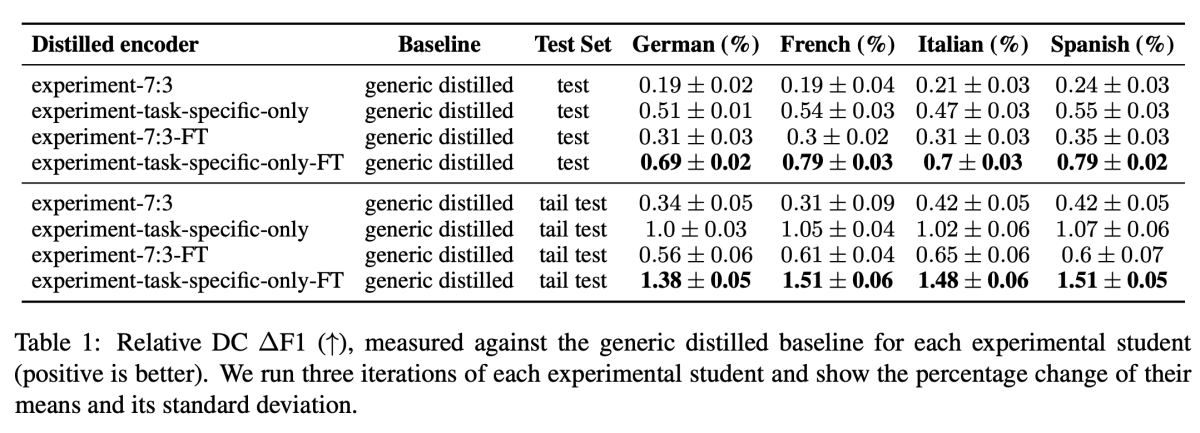
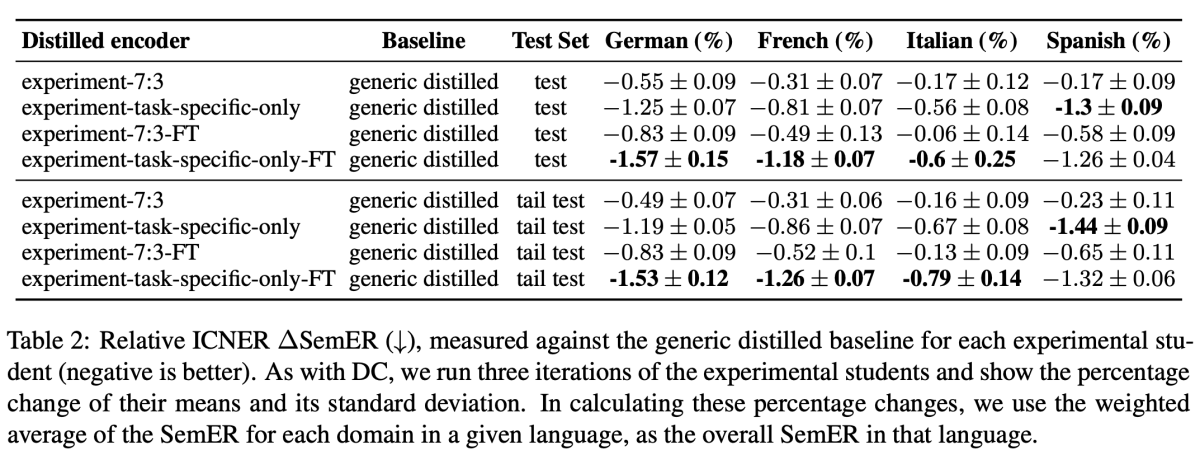
On the DC task, our results show improvements across the board when task-specific data is included in the transfer sets, with the greatest improvement coming from using only task-specific data. We see similar results in the case of ICNER, where improvements are greater for encoders distilled using only task-specific data.
Acknowledgements: We would like to acknowledge our coauthors in the paper for their contributions to this work: Lizhen Tan, Turan Gojayev, Pan Wei, and Gokmen Oz.



