
The general chair of this year’s meeting of the European Chapter of the Association for Computational Linguistics (EACL) is Alessandro Moschitti, a principal scientist in the Alexa AI organization, and the conference comes at a peculiar time in the history of the field. With the remarkable recent achievements of large language models (LLMs), Moschitti says, “most of the core problems that we had in NLP [natural-language processing] that were considered part of AI — for example, syntactic parsing, semantic parsing, coreference resolution, or sentiment analysis — are basically solved. You can send some queries to chatGPT, and it can check super well the syntax of a piece of text.”

At the same time, however, the way in which most researchers interact with LLMs is through an application programming interface; they can’t access the inner workings of the models. The result is a recent concentration on prompt engineering, or devising inputs to LLMs that elicit the desired outputs.
“If you want to do some more basic study — produce different architectures — and you are not associated with the owners of the LLMs, there is no way that you can do this kind of research,” Moschitti says. “Alternatively, you still need to have, as a proxy, a smaller model — which, by the way, is more or less the same architecture, just smaller.”
Consequently, Moschitti explains, a number of papers at EACL still concern the previous generation of language models, such as BERT, RoBERTa, Electra, and T5. LLMs are based on the same architecture, but with orders of magnitude more parameters, and trained on similar text completion tasks, but over much larger datasets. So the results of experiments involving the smaller models will often have implications for LLMs.
Of course, the much reported drawback of LLMs is their tendency to “hallucinate”, or make plausible-sounding but spurious factual assertions. Remediating hallucinations is already an active area of research, Moschitti explains, and it’s likely to only grow in popularity.
“You will see even at EACL several papers that try to address this limitation of Transformer-based models,” Moschitti says. “There are mostly two methods. One method is to train the model and then analyze the output, building some classifiers that can detect if the output is a hallucination or not.
“The other approach, which is technically cleaner, is to train the model in such a way that it will hallucinate less. Previously, we used constrained decoding, meaning that we apply some constraint when we are decoding the input such that we don't diverge too much from the input. Now, a topic that is pervasive is so-called grounding. Grounding means that when we ask a question to a large language model, instead of providing zero input — and the model at this point is creating from its parametric memory — if we provide some ground, some facts, to the model, the model can generate with respect to the ground.”
Responsibilities
As at most AI-related conferences in the last few years, responsible AI is also a big topic at EACL, Moschitti says. Some forms of bias in NLP models are straightforward to measure: for instance, cases in which a model associates particular genders (e.g., female) with particular occupations (e.g., nurse). These types of bias can be addressed using general machine learning techniques applicable across disciplines.
But other types of bias are more subtle, such as slight differences of tone in the way members of different demographic groups are described. Rooting out these types of bias requires the special skills of NLP researchers.
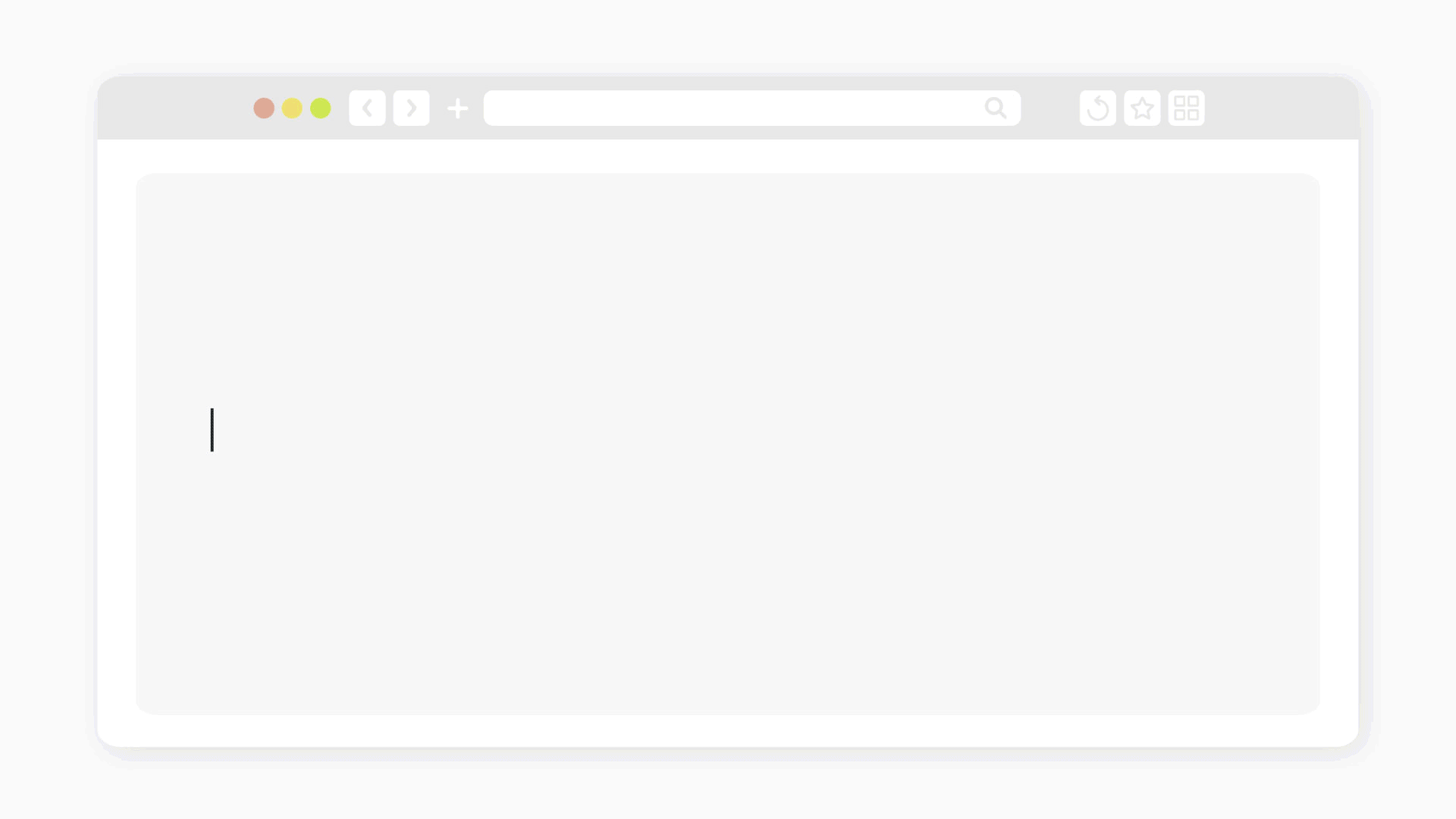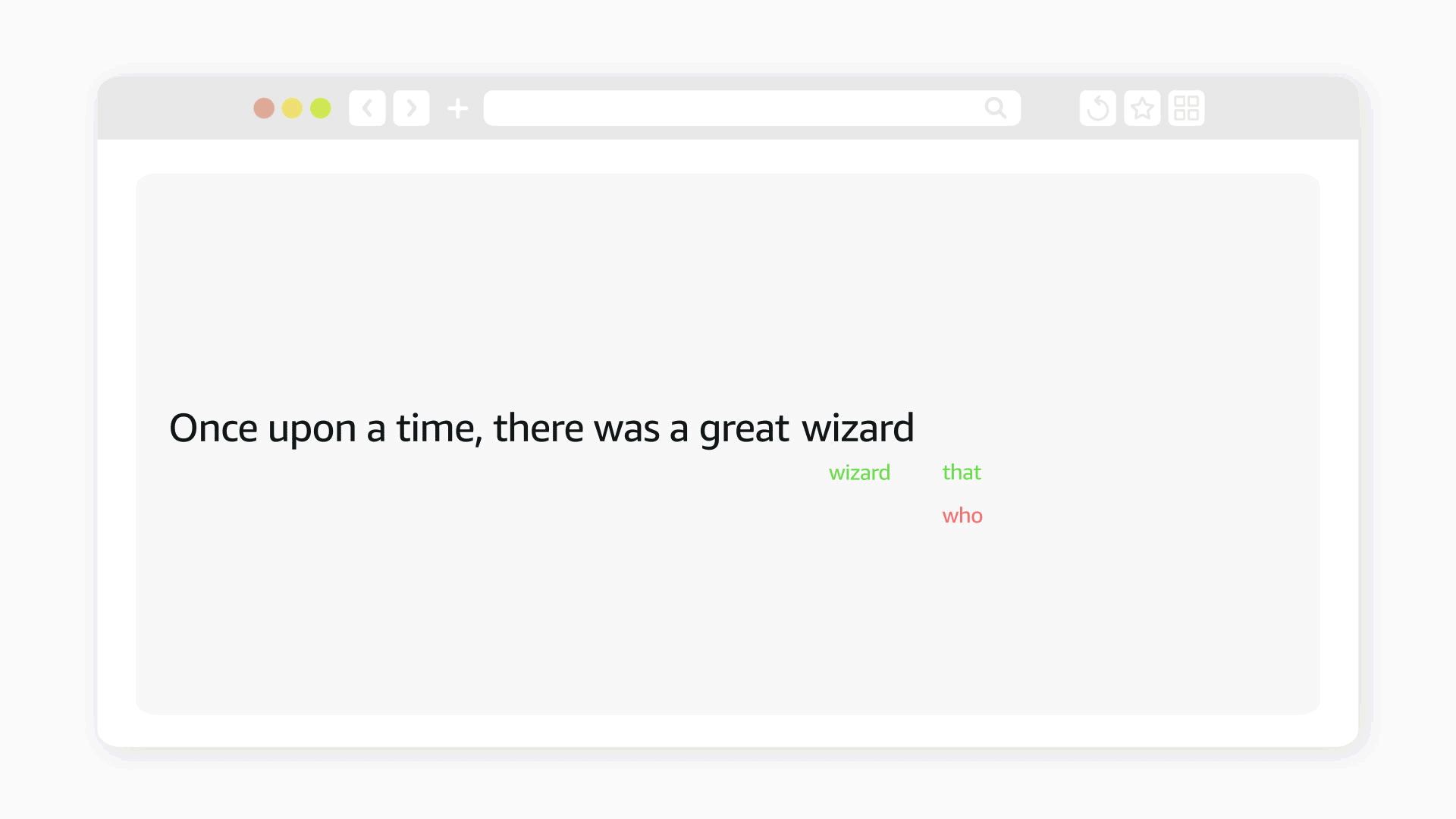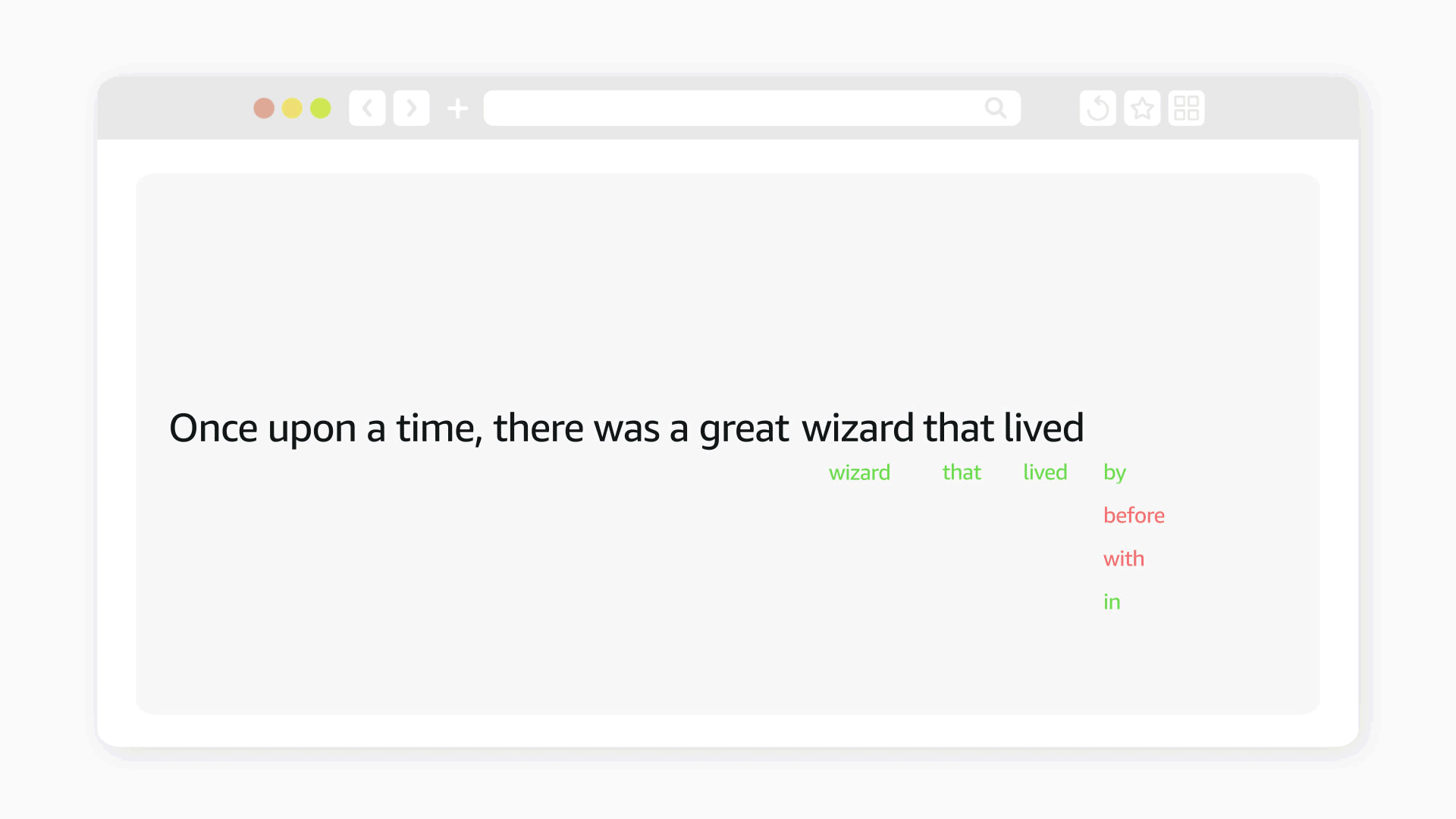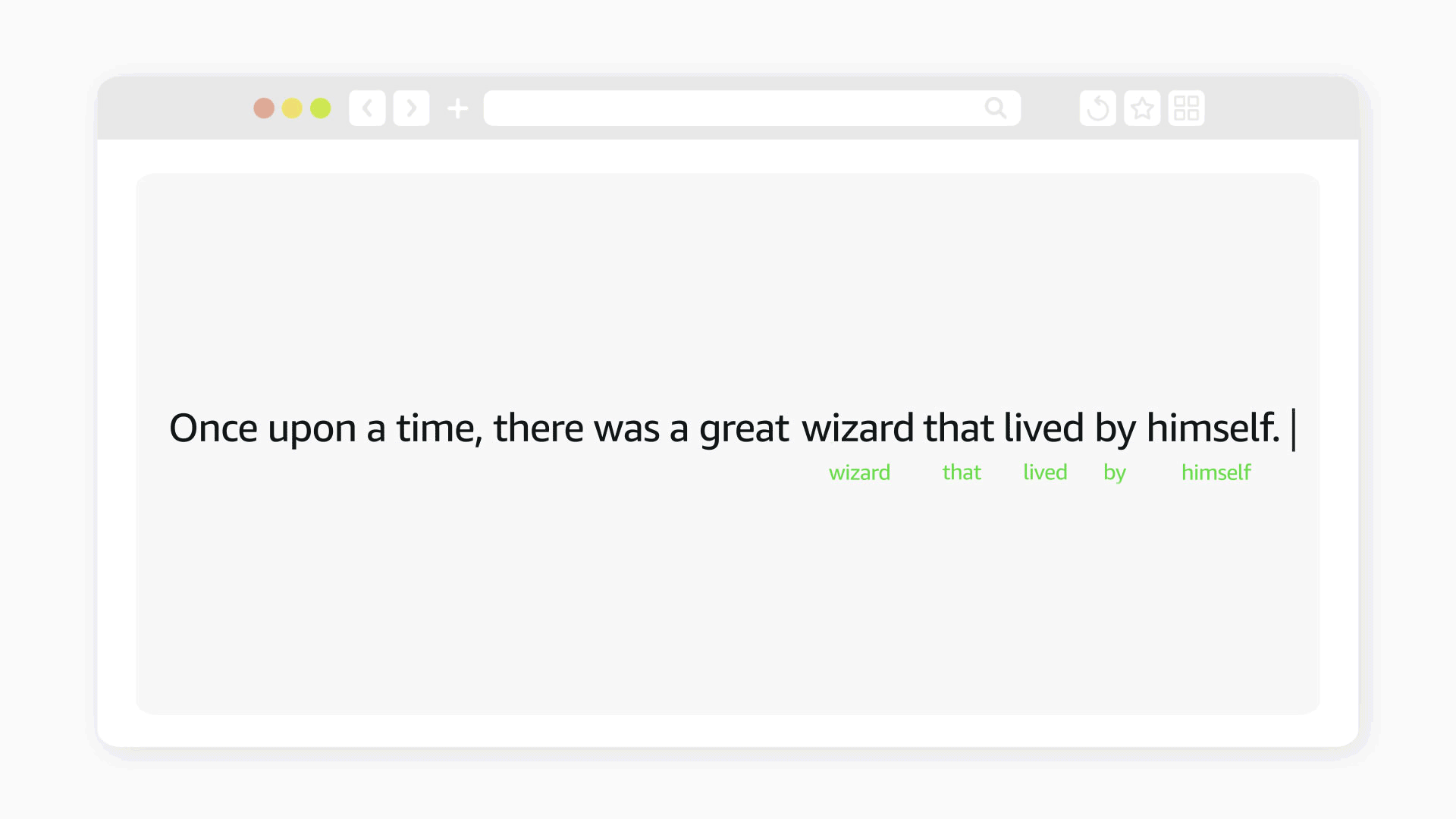
“That is surely one important topic that is suitable for the NLP community, because it's a matter of style, of how you say things,” Moschitti says. “So the meaning and also the pragmatics.”
Ethical concerns underlie another recent shift at EACL, Moschitti says — but this is a procedural shift, not a shift in paper topics.
“We have three or four main NLP conferences each year,” Moschitti says. “Before EACL, we had EMNLP [the Conference on Empirical Methods in Natural-Language Processing], and they started a new trend to require each paper submission to have a section about limitations. It should describe the context of the applicability of the proposed solution. Because typically, people tend to write as if their approaches offer improvement everywhere. But usually, an approach has limitations. It can be efficiency; it can be language-specific applicability; it can be setting; or it might require particular resources. So EMNLP started this idea of adding this limitation section, and in our papers in EACL, we also have this requirement.”



