Miguel Ballesteros, a principal applied scientist with Amazon Web Services' AI Labs, is a senior area chair for semantics at this year’s Conference on Empirical Methods in Natural Language Processing (EMNLP). Given the growing importance of large language models within the field, he says, “prompt engineering” has become a major topic of research.
A quick guide to Amazon's 40+ papers at EMNLP 2022
Explore Amazon researchers’ accepted papers which address topics like information extraction, question answering, query rewriting, geolocation, and pun generation.
“In the past, we used to have feature engineering, where you have a statistical model, and you are adding different types of representations or features, and then you needed to tune the model along with your features,” Ballesteros says. “These days, with large language models, the new thing that is coming is the idea of prompts, in all of its variations, as a way of priming the models.”

Large language models such as GPT-3 are trained to predict words in sequence, based on context. Large enough models, trained on enough data, end up encoding word sequence probabilities across whole languages. A prompt is an input that the model uses as the basis for generating a text.
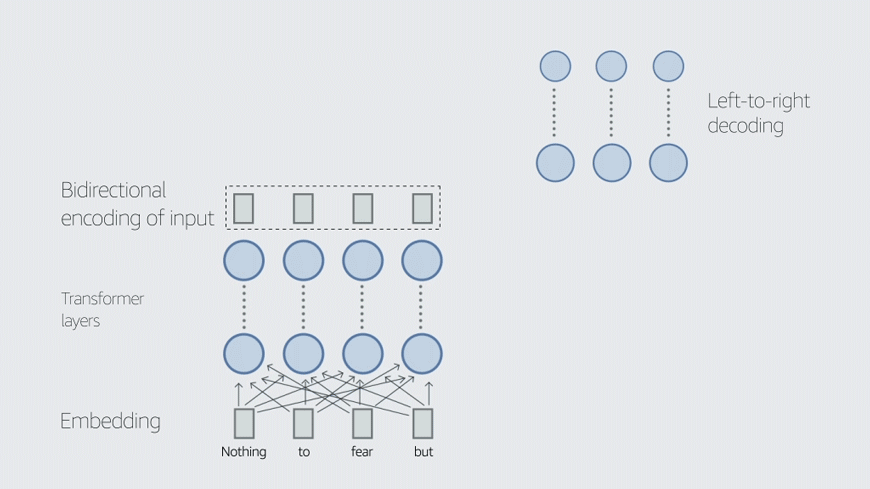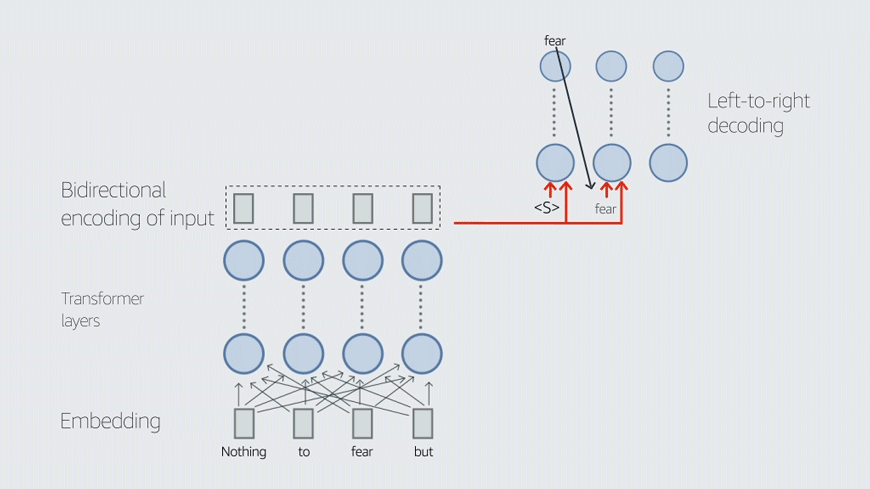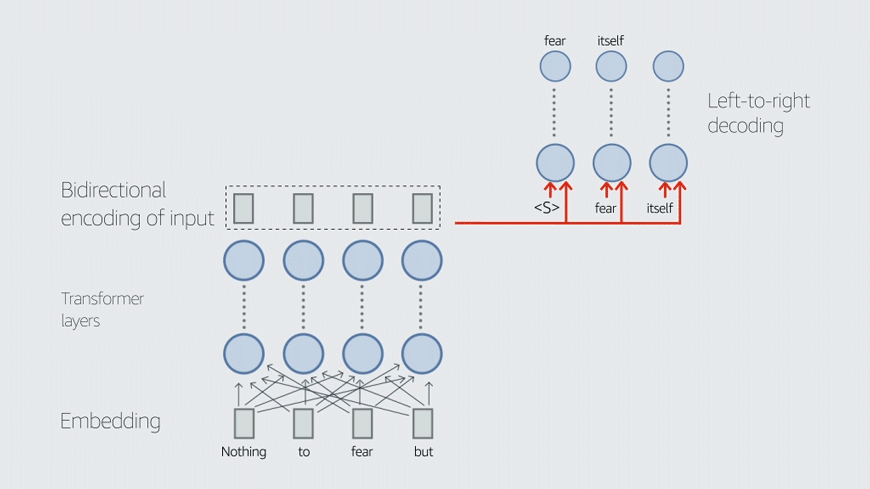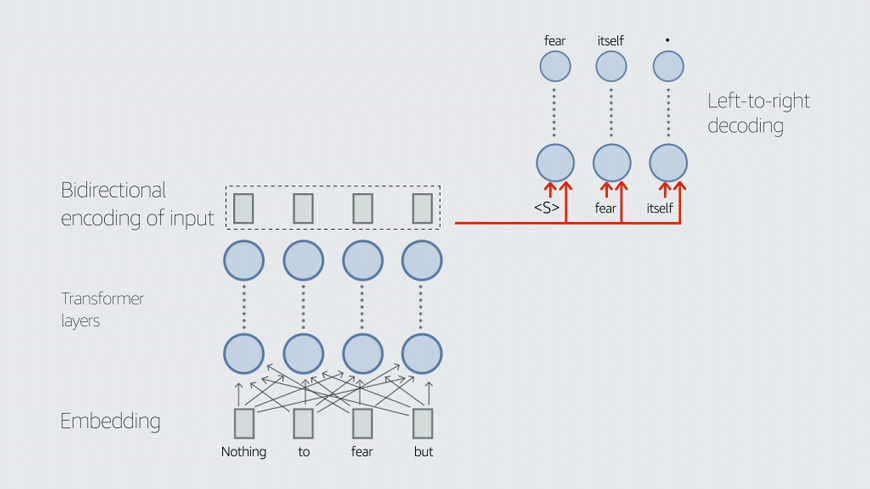
“Sometimes a prompt is essentially a sequence of words, like prompting your computer terminal — a command,” Ballesteros explains. “But ‘prompt’ is also used to refer to soft prompts, a vector; these are also called task-specific embeddings or task embeddings. Task embeddings help models to perform mode switching. For example, a vector that indicates that the text to be generated should be in one language or another is known as a language vector.”
Large language models have long been used as the basis for natural-language-processing (NLP) models; in the typical scenario, the pretrained language model is fine-tuned on data annotated for a specific task.
But prompts are a way to directly access the knowledge encoded in large language models. Statistical relationships between words, after all, carry semantic information: a model that can find the highest-probability conclusion to the prompt, “In the 1940 election, FDR defeated …” could actually provide the user with information about the world.
Consistency
The problem is that, while the information may be in there, extracting it can be a hit-or-miss affair: prompted to assert a fact, a large language model might surface reliable information, or it might spout gibberish. Ballesteros believes, however, that these are just the inevitable growing pains of a young technology.
“Prompt engineering is the process of looking for the prompts that work best with a particular model for natural-language generation,” Ballesteros says. “However, models that are trained to predict the next word in a sequence can be improved. There are alternatives that allow for better outcomes, maybe even having a human-in-the-loop component, someone who ranks outputs. What's the right response and what's the wrong one? This can help models align the prompts with the right responses, incorporating all those new inductive biases.”
Models that are trained to predict the next word in a sequence can be improved. There are alternatives that allow for better outcomes.
Steering models toward factually accurate outputs that avoid offensive language, however, doesn’t address the problem that two different prompts, which to a human reader clearly express the same semantic content, may still elicit different responses from a large language model.

“There is a need for more work on how to build and evaluate models that are robust to prompts,” Ballesteros says. “The fact that the term ‘prompt engineering’ exists means that current available models work only when you give them the best commands. There are papers investigating the idea of universal prompting — papers on prompt robustness, and how to measure prompt paraphrase robustness.”
Prompt engineering also provides a way for large language models to do few-shot generalization, in which a machine learning model trained on a set of generic tasks learns a new or related task from just a handful of examples.
“You can provide a prompt supported by examples,” Ballesteros explains. “If I want to extract a summary of this conversation, and I have the texts of three more conversations, I provide those conversations and a human summary, and the model will condition on that context and generate a better summary.
“These models can also do compositionality of tasks. Before this era of deep learning with large language models, you were constrained by your data. But now with the idea of prompting, large language models can actually combine multiple tasks. I can say, ‘Summarize this document from the perspective of a two-year-old’ or ‘Summarize this document from the perspective of a scientist”, and the models should produce very different outputs. Models learn to compose based on the words provided in the input. For example, they can do style transfer and summarization and even do it in multiple languages.”
Trending topics
A few other research trends caught Ballesteros’s eye at EMNLP. One of them is reasoning.

“It has become very active recently,” he says. “There are interesting papers that show how to train models so they can generate a chain of thought before they provide a response to the prompts. The chain-of-thought generation helps these models provide better answers, so in a way, it is as if the model would be thinking out loud. The challenge I see here is how to automatically evaluate models that provide reasoning in their outputs.”
Finally, as successful as word sequence prediction has been in natural-language processing, the addition of other types of structural information could lead to still better models. Ballesteros says. “Models rely on positional information about words, and this positional information can be enriched in many ways — where they belong in a syntactic tree, or whether they are in a table within a document,” Ballesteros says. “There is a lot of good work investigating how to make our models aware of linguistic structure or even the document structure, not just rely on plain sequences of words.”