
Until the recent, astonishing success of large language models (LLMs), research on dialogue-based AI systems pursued two main paths: chatbots, or agents capable of open-ended conversation, and task-oriented dialogue models, whose goal was to extract arguments for APIs and execute tasks on the user’s behalf. LLMs have enabled enormous progress on the first challenge but less on the second.
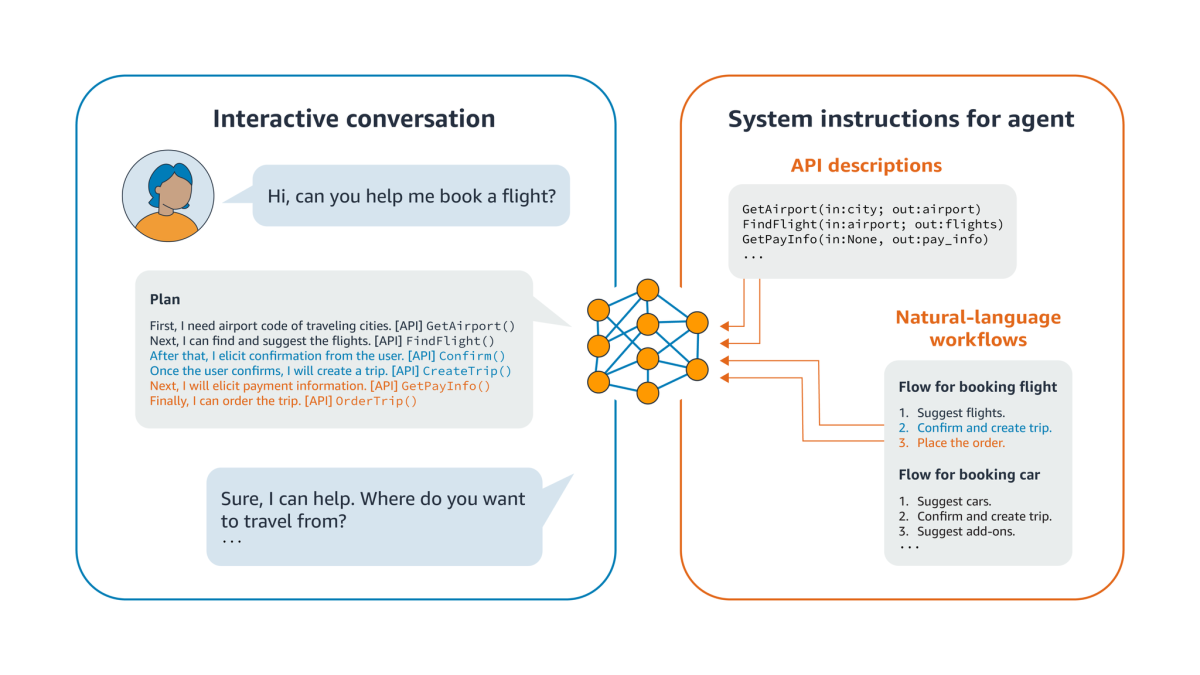
In part, that’s because LLMs have difficulty following prescribed sequences of operations, whether operational workflows or API dependencies. For instance, a travel agent application might want to recommend car rentals, but only after a customer has booked a flight; similarly, the API call to search for flight options can occur only after API calls to convert city names to airport codes.

At this year’s meeting of the North American Chapter of the Association for Computational Linguistics (NAACL), we presented a new method for constraining the outputs of LLMs so that they adhere to prescribed sequences of operations. Fortunately, the method doesn’t require any fine-tuning of the LLMs’ parameters, and can work with any LLM (with logit access) out of the box.
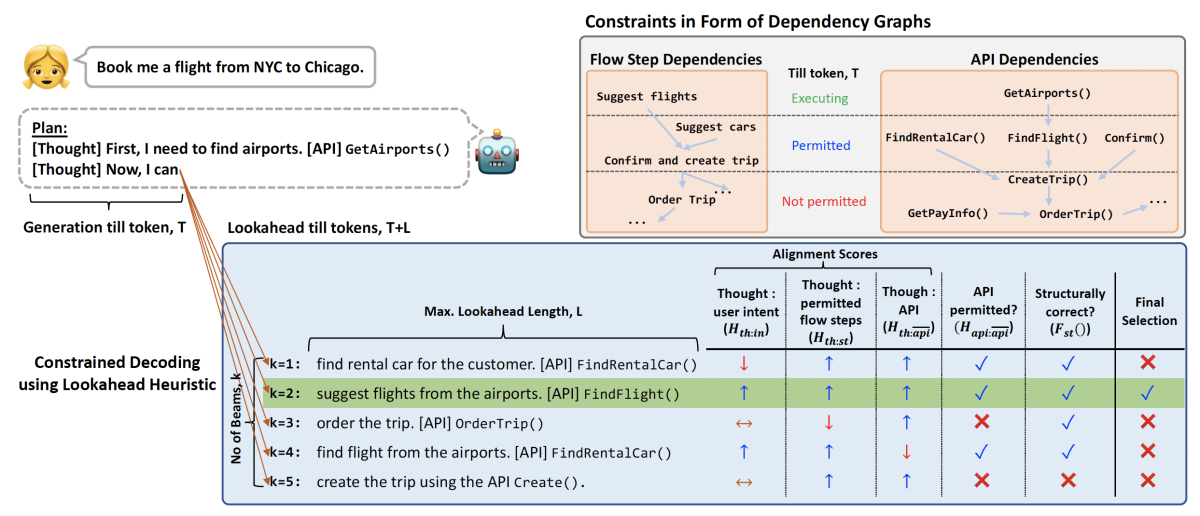
We use graphs to represent API and workflow dependencies, and we construct a prompt that induces the LLM to respond to a user request by producing a plan — a sequence of API calls, together with a natural-language rationale for each. Given a prompt, we consider the k likeliest successor tokens, as predicted by the LLM. For each of those tokens, we look ahead, continuing the output generation up to a fixed length. We score the k token continuation sequences according to their semantic content and according to how well they adhere to the dependency constraints represented in the graph, eventually selecting only the top-scoring sequence.
Existing datasets for task-oriented dialogue tend not to feature many sequence-of-operation dependencies, so to test our approach, we created our own dataset. It includes 13 distinct workflows and 64 API calls, and each workflow has 20 associated queries — such as, say, differently phrased requests to book flights between different cities. Associated with each workflow is a gold-standard plan consisting of API calls in order.

In experiments, we compared our approach to the use of the same prompts with the same LLMs but with different decoding methods, or methods for selecting sequences of output tokens. Given a query, the models were supposed to generate plans that would successfully resolve it. We assessed solutions according to their deviation from the gold solution, such as the number of out-of-sequence operations in the plan, and other factors, such as API hallucination and API redundancy.
Our method frequently reduced the number of hallucinated API calls and out-of-sequence generations by an order of magnitude — or even two. It reduced the number of edits required to resolve generated plans with the gold plan by 8% to 64%, depending on the model and the hyperparameters of the decoding methods.
We also showed that our approach enabled smaller LLMs — on the order of seven billion parameters — to achieve the same performance as LLMs with 30-40 billion parameters. This is an encouraging result, as with increased commercial use of LLMs, operational efficiency and cost are becoming increasingly important considerations.
FLAP
With our approach — which we call FLAP, for flow-adhering planning — each query to an agent is preceded by a set of instructions that establish the available API calls and the relevant workflow sequences. The prompt also includes examples of thoughts that explain each API call in natural language.

We experimented with instruction sets that did and did not include thoughts and found that their inclusion consistently improved the quality of the generations.
For each input token, an LLM generates a list of possible succeeding tokens, scored according to probability. All LLMs use some kind of decoding strategy to convert those lists into strings: for example, a greedy decoder simply grabs the highest-probability successor token; nucleus sampling selects only a core group of high-probability successors and samples from among them; and beam decoding tracks multiple high-probability token sequences in parallel and selects the one that has the highest overall probability.
FLAP proposes an alternative decoding strategy, which uses a scoring system that encourages selection of tokens that adhere to the API and workflow dependency graphs. First, for each output thought, we use a semantic-similarity scoring model to identify the most similar step in the instructions’ workflow specifications.
Then, based on the workflow dependency graph, we determine whether the current thought is permitted — that is, whether the steps corresponding to its ancestor nodes in the graph have already been executed (preconditions met). If they have been, the thought receives a high score; if not, it receives a low score.
We score the API calls in the same way — that is, based on whether their execution order conforms to the dependency graph. We also use the similarity-scoring model to measure the similarity between the generated thought and the user query, and between the thought and the generated API call.
Finally, we score the plan on whether it adheres the <thought, API call> syntax for each step in the plan, with the thought and the API call preceded by the tags “[thought]” and “[API]”, respectively. On the basis of all these measures, our model selects one of the k token sequences sampled from the LLM’s output.
In our experiments, we considered two variations on the instructions sets, one in which all the workflow constraints for an entire domain are included in the prompt and one in which only the relevant workflow is included. The baselines and the FLAP implementation used the same LLMs, differing only in decoding strategies: the baselines used greedy, beam search, and nucleus-sampling decoders.
![At left is a neural network, labeled "pre-edit model", each of whose input nodes receives a single token from the string "<CLS> The high minded dismissal [SEP] A dismissal of a higher mind". The output of the model is the prediction "Contradict". Encodings from the network pass to a block labeled "SaLEM", in which gradients for each input token are calculated and the most-salient layer identified. The outputs of the block are edits to the layer weights. At right is another version of the neural network at left, labeled "post-edit model". Here, the output is "Entailed" rather than "Contradict".](https://assets.amazon.science/dims4/default/bcef437/2147483647/strip/true/crop/3982x2250+18+0/resize/200x113!/quality/90/?url=http%3A%2F%2Famazon-topics-brightspot.s3.amazonaws.com%2Fscience%2Ffc%2F84%2F2aa85e0645d9b139cedded97c66b%2Fsalem-architecture.png)
Across the board, on all the LLMs tested, FLAP outperformed the baselines. Further, we did not observe a clear runner-up among the baselines on different metrics. Hence, even in cases where FLAP offered comparatively mild improvement over a particular baseline on a particular metric, it frequently showcased much greater improvement on one of the other metrics.
The current FLAP implementation generates an initial plan for an input user query. But in the real world, customers frequently revise or extend their intentions over the course of a dialogue. In ongoing work, we plan to investigate models that can dynamically adapt the initial plans based on a ongoing dialogue with the customer.



