
In 2019, Alexa launched multilingual mode for US English and US Spanish, which lets customers address Alexa in either language and receive responses in that language. To ensure that both the English and Spanish voices had natural-sounding accents, they were based on different voice performers’ recorded speech. Consequently, multilingual mode felt like speaking to two different people.
Now, the Amazon Text-to-Speech (TTS) team has used deep-learning methods to transfer the ability to speak US Spanish — with native-speaker accent and fluency — to a voice based only on English recordings. Although we are using the technology initially in a bilingual mode, our experiments indicate that it should generalize to multiple languages.
Neural text-to-speech (NTTS) uses neural networks to generate speech directly from phonetic renderings of input texts. In the past few years, the Amazon TTS team has used NTTS to transfer vocal inflections (prosody) from a recorded voice to a synthesized voice or change the speaking style of a synthesized voice, to make it sound more like a newscaster or DJ. In the same way, neural TTS lets us teach an existing voice to speak a new language.
With traditional TTS systems, the way to do this was to map the phonemes of the target language into equivalent phonemes — the shortest units of speech — in the speaker’s native language. But this resulted in synthesized speech with a heavy foreign accent. Another approach was to find bilingual voice performers and record them speaking both languages, which is not always feasible and limits the number of languages we can combine. Our new multilingual model solves both problems.
Shared spaces
With our new technology, we begin by training a machine learning model on data from multiple speakers in multiple languages. We start with our standard neural TTS platform, which takes a sequence of phonemes as input. We add two additional inputs (shown in blue in the figure below), a language ID code and a speaker embedding, a vector representation that encodes distinctive characteristics of a given speaker’s speech.
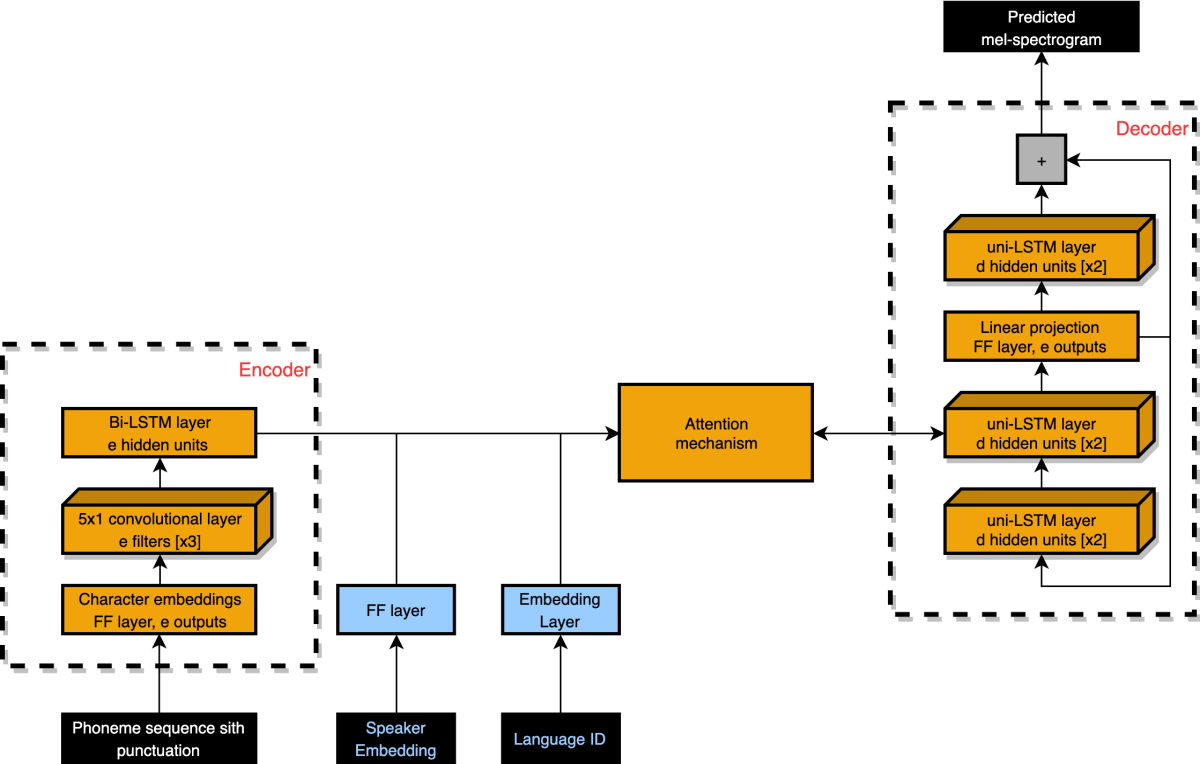
The phoneme sequence passes to an encoder, whose output is a vector representation that encodes acoustic information about the phonemes. We want this encoder to project acoustically similar phonemes from different languages into the same region of the representation space, regardless of speaker identity or language.
The phonetic encoding, the language ID, and the speaker embeddings pass through an attention mechanism, which determines which of the input phonemes require particular attention, given the current state of the decoder. The decoder uses the speaker and language embeddings to produce the correct acoustic content for a particular speaker and language. Reconfirming the language ID at the input of the decoder allows the encoder to extract common representations across languages.
The speaker embeddings we use are pretrained in a speaker classification task on a large external corpus. The embeddings for similar speakers cluster together, independent of the language they speak. The system can thus use speaker embeddings to extrapolate how speakers would sound in different languages.
Evaluation
We evaluated the performance of our model on four axes. First, we measured the naturalness of the output in English to make sure that we do not degrade the existing experience. Then we measured the system’s naturalness, speaker similarity, and accent quality in Spanish. These three measures ensure that we provide our customers with a high-quality synthetic voice that resembles the original speaker and speaks Spanish with a native accent.
The figure below shows the boxplots of our measurements along the four axes, according to the MUSHRA (multiple stimuli with hidden reference and anchor) methodology. We evaluated the current English production model (EN Alexa) against the bilingual (Polyglot) model. The plots present (from left to right) the results for naturalness in English, naturalness in Spanish, speaker similarity in Spanish, and accent in Spanish.
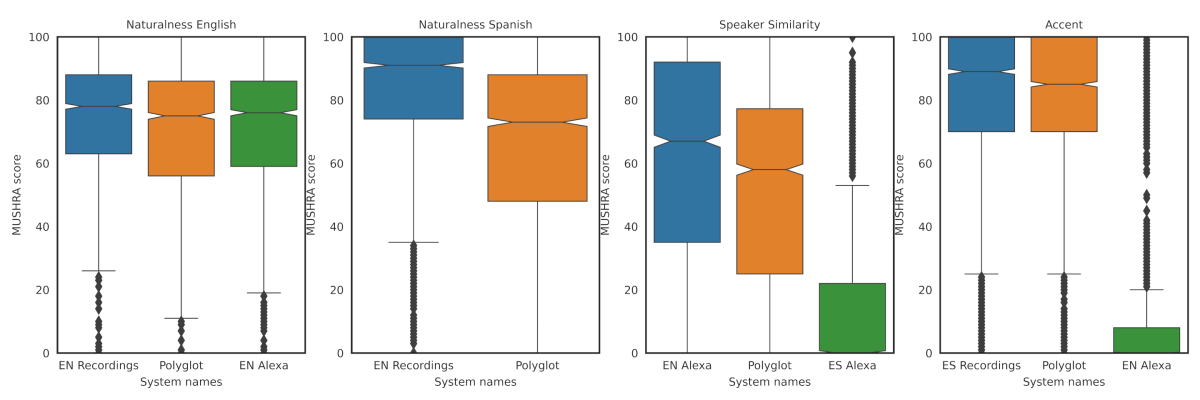
In both naturalness evaluations we used English recordings of the original speaker as a reference. We can see in the English evaluations that the Polyglot system is performing slightly worse than the EN Alexa model. We decided that this was a small acceptable regression, given the benefits of having a voice that can speak both languages. The Polyglot system achieves similar naturalness scores in both English and Spanish.
In the speaker similarity evaluations, we asked listeners to rate how similar the Spanish samples were to a random recording of the original speaker in English and to rate the similarity of the English and Spanish voices in the original Alexa multilingual mode. We also compared the Polyglot system with a version of the EN Alexa model that mapped the Spanish phonemes to English phonemes.
Unsurprisingly, the Polyglot Spanish voice sounds much more similar to the English target speaker than the native Spanish speaker from the original multilingual mode does to the native English speaker. The Polyglot voices don’t reach the same similarity that the voices produced by phoneme mapping do, but this might be because of listener bias toward the English accent.
In the accent evaluations, there is no statistically significant difference between the scores given to the Polyglot system and to the Spanish recordings. In other words, Polyglot sounds as native as Spanish Alexa recordings. Overall, we were able to produce a high-quality synthetic voice with a native Spanish accent that was perceived to be the same person as the English-speaking voice, without needing an English voice actor to read in Spanish.
This technology may enable Alexa to speak even more languages in the future, as we can make an existing speaker speak a new language without making additional recordings.



