
The models behind machine learning (ML) services are continuously being updated, and the new models are usually more accurate than the old ones. But an overall improvement in accuracy can still be accompanied by regression — a loss of accuracy — in particular cases.
This can be frustrating for users, especially if a given regression has downstream consequences. A virtual conversational agent, for example, might regress on a user request early in a dialogue, which disrupts the ensuing conversation.
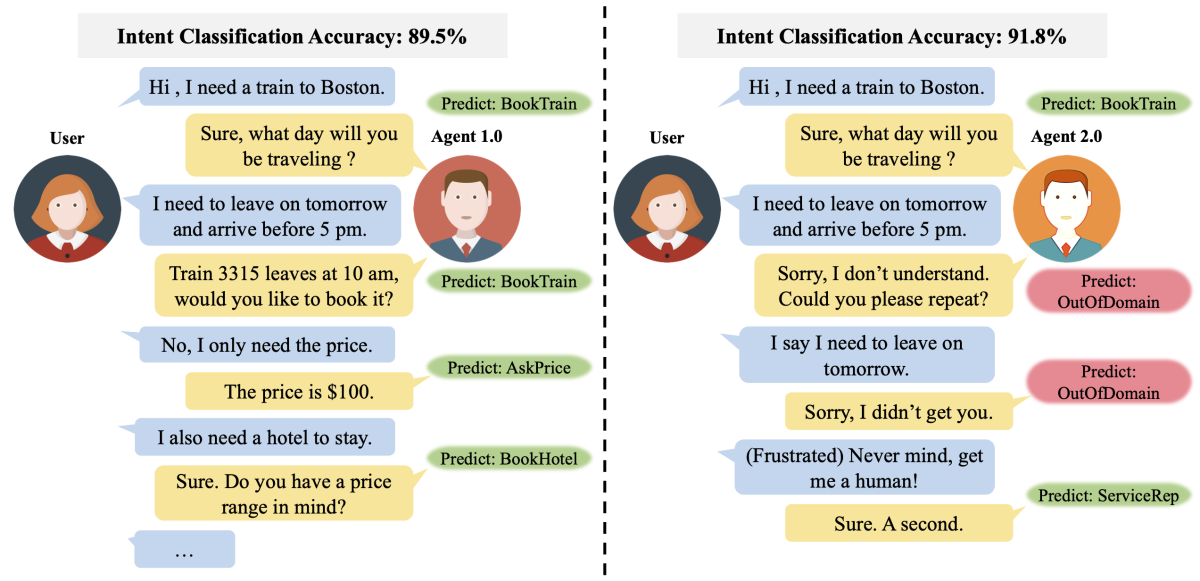
In a paper we’re presenting at this year’s meeting of the Association for Computational Linguistics (ACL), we describe a new approach to regression-free model updating in natural-language processing (NLP), which enables us to build new deep neural models that not only perform better in accuracy but consistently preserve legacy models’ correct classifications.
The paper has two parts: a study of model update regression and a proposal for mitigating it. In the study, we use public benchmark models based on the BERT language model and train them on the seven different NLP tasks of the General Language Understanding Evaluation (GLUE) framework. Then we train updated models using either different model parameters or a more powerful BERT model. We find that regression occurs on 1.9% to 7.6% of input cases, even though overall performance improves after retraining.
To mitigate regression, we formulate the problem of matching past performance as a constrained optimization problem, then relax the problem to be approximated via knowledge distillation, which encourages the new model to imitate the old one in the right context.
Our research is part of Amazon Web Services’ (AWS’s) recent work on “graceful AI”, machine learning systems that are not just accurate but also more transparent, more interpretable, and more compatible with their predecessors. We believe that regression-minimized model updating is a critical building block for successful ML services that are continuously improving and evolving gracefully.
Regression bugs are in your NLP model!
In our study, we measure model update regression by negative flip rate (NFR), or the percentage of cases in which the old classifier predicts correctly but the new classifier predicts incorrectly. For services with tens of millions of users, the types of NFRs we measure would translate to poor experiences for hundreds of thousands of users. When regression occurs at that scale, it often requires extensive, time-consuming error analysis and model patching.

Our study showed that in updated models, NFRs are often much higher than the total accuracy gains, from two to eight times as high. This implies that simply aiming for greater accuracy improvements in updated models will not ensure a decrease in regression; i.e., improving accuracy and minimizing regression are related but separate learning targets.
Finally, we also found that minor changes, such as using different random seeds (constants that introduce randomness into the training process) can cause significant variation in regression rate, a consideration that any mitigation strategy will need to account for.
How to mitigate regressions
Regression-free model updating requires a model to both learn the target task and comply with conditions posed by the old model, making it a constrained optimization problem. We relax the hard constraint into a soft inequality condition and propose a proxy to replace NFR: a continuous measure that uses Kullback-Leibler divergence — a standard similarity measure — over prediction logits, or the unnormalized outputs of both the old and new models. We can thus approximate the constrained optimization problem as optimizing a joint objective of classification loss and knowledge distillation penalty.
In evaluating our approach, we used two baselines. One was a model updated in the traditional way, without any attempt to control regression. The other was an ensemble that included both the original model and the updated model; the ensemble’s final classification was a combination of both models’ outputs.
Our results show that when updating involved changing language models — switching from BERT-base to BERT-large, for instance — our knowledge distillation approach was the most effective, cutting average NFR to 2.91%, versus 3.63% for the ensemble model and 4.57% for a conventional update. At the same time, our model was slightly more accurate than both baselines.
We also evaluated our models using the CheckList protocol, which assesses an NLP model’s performance using different classes of input data, designed to elicit different types behavior. We found that distillation can effectively reduce regressions across almost all types of behavioral tests, implying that our distillation method is actually aligning the new model’s behavior with the old model, rather than using short cuts in a few special cases.
When updating involved different random seeds, without a change of language model, the ensemble method worked better than ours, which was a surprise. This is possibly because ensembles naturally reduce output variance, making them less prone to overfitting, which could reduce regressions.
Given the results of our initial study, we hypothesized that single-model variance could be a function of the choice of random seeds. So we designed a simple model selection procedure in which we train 20 different models using 20 random seeds and pick out the one that offers the greatest NFR reduction. We found that in the cases in which updates preserve the same language model, this approach reduces regression as well as ensemble methods do, without the added operational overhead of running two models in parallel.
At AWS AI, we are committed to continuing to explore innovative solutions to this problem and to ensure that customers can always enjoy state-of-the-art technologies without painful transitions. We hope our work will inspire the AI community to develop more advanced methods and build easily maintainable, ever-improving systems.



