
Millions of customers around the world rely on Amazon's vast online catalogue, containing information on hundreds of millions of products, to make informed purchase decisions. To ensure that catalogue data is comprehensive, consistent, and accurate, the Amazon Catalog team uses a wide range of machine learning models — including generative-AI models that synthesize textual and visual information from seller listings, manufacturer websites, customer reviews, and other sources to enrich catalogue data.
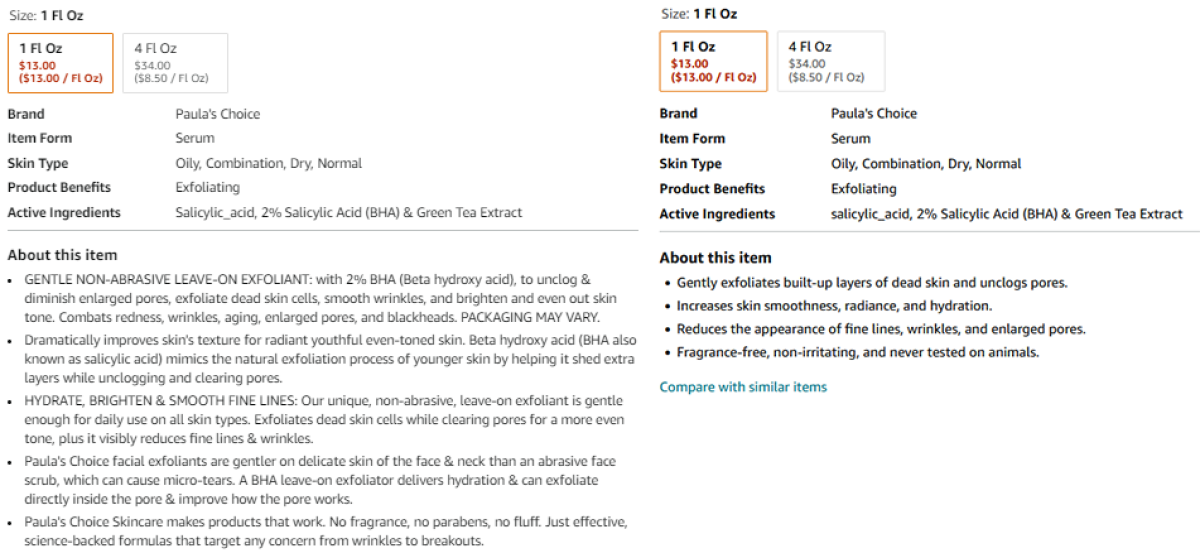
To ensure that the enriched data improves the customer experience, Amazon Catalog conducts A/B experiments that expose some of our customers to the enriched information, while others encounter the current alternative.
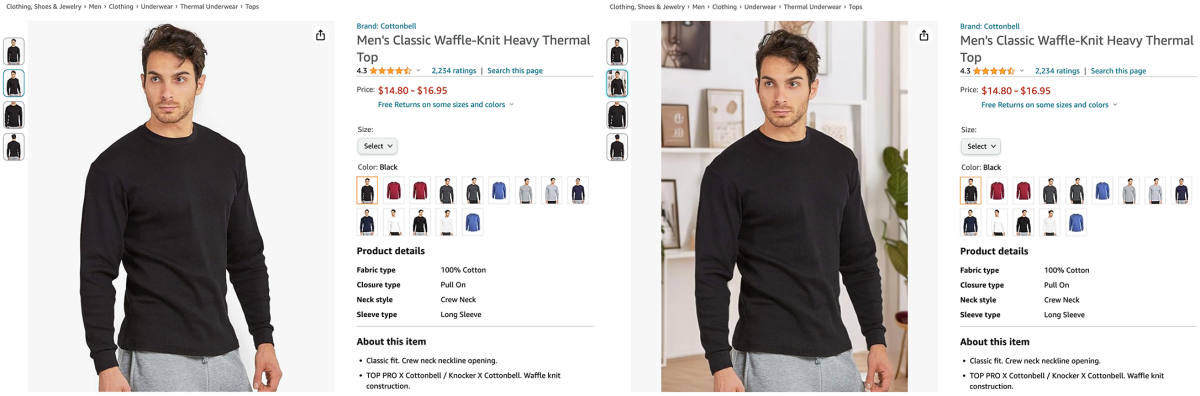
But A/B testing can incur opportunity costs, as we delay the rollout of catalogue improvements for some of our customers, and maintaining two backend systems is resource intensive. To tackle these challenges, we propose two different scientific approaches.
Machine-learning-based extrapolation model
First, we seek to run as few experiments as possible. We have developed a scalable machine-learning-based extrapolation model that effectively incorporates insights gained from prior experiments on enrichment initiatives and applies them to new contexts. We tailor the causal-random-forest approach, which is itself an extension of the classical random-forest algorithm, to our setting.
During training on our existing A/B experiments, the algorithm randomly selects training and validation datasets and generates an ensemble of causal decision trees. Each tree splits the products involved in the experiments into smaller subgroups, sorted by similarity of features, balancing the within-sample fit of the observed outcomes by treatment status and the out-of-sample performance on the validation dataset. We then aggregate the different predictions from all causal trees to generate one prediction about the effect of enrichments given different product features. After training the model, we can validate it in additional experiments to compare predicted to actual treatment effects.
The validated model lets us test whether there are differences in the responses to an enrichment across products. If that is the case, we can focus our enrichment efforts on those product groups that respond particularly well. In addition, we can use the estimates to predict and document the impact of our planned enrichments on our customers as we tackle different product groups throughout the year. As an example, we can use the model to assess the impact of our efforts to correct and complete product information across the catalogue with only a limited set of experiments.
Bayesian structural time series
When conducting A/B experiments is not feasible, we can turn to observational modeling techniques such as Bayesian structural-time-series modeling. This approach synthesizes ideas from time-series analysis, the synthetic control method, and Bayesian statistics.

As we monitor sales of all our products over time, we can pair any product group with a synthetic twin that mirrors its sales performance, accounting for sales trends and seasonality. If we then enrich a group of products and observe a noticeable difference in sales performance, we can attribute the change to our enrichment efforts. Operating within the Bayesian framework enables us to integrate prior knowledge from our various analyses, including our A/B experiments, and effectively communicate uncertainty to our business stakeholders.
We have validated our observational model against our A/B experiments for selected use cases where both methods are feasible and have used this approach to evaluate the impact of our large-scale machine learning systems, which automatically classify products to improve their discoverability by customers through search or browsing.
With enriched catalogue data, Amazon customers are able to make better-informed and more-confident shopping decisions.
Acknowledgements: Philipp Eisenhauer



