
Automatic-speech-recognition (ASR) models, which transcribe spoken utterances, are a key component of voice assistants. They are increasingly being deployed on devices at the edge of the Internet, where they enable faster responses (since they don’t require cloud processing) and continued service even during connectivity interruptions.
But ASR models need regular updating, as new words and names enter the public conversation. If all locally collected data stays on-device, updating a global model requires federated learning, in which devices compute updates locally and transmit only gradients — or adjustments to model weights — to the cloud.
A central question in federated learning is how to annotate the locally stored data, so it can be used to update the local model. At this year’s International Conference on Acoustics, Speech, and Signal Processing (ICASSP), my colleagues and I presented an answer to that question. One part of our answer is to use self-supervision, or using one version of a model to label data for another version, along with data augmentation. The other part is to use noisy, weak supervision signals based on implicit customer feedback — such as rephrasing a request — and natural-language-understanding semantics determined across multiple turns in a session with the conversational agent.
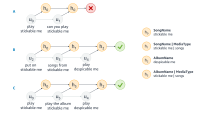
| Transcription | play Halo by Beyonce in main speaker |
| ASR hypothesis | play Hello by Beyond in main speaker |
| NLU semantics | PlaySong, Artist: Beyonce, Song: Halo, Device: Main Speaker |
| Semantic cost | 2/3 |
Table: Examples of weak supervision available for an utterance. Here, semantic cost (fraction of slots incorrect) is used as the feedback signal.
To test our approach, we simulated a federated-learning (FL) setup in which hundreds of devices update their local models using data they do not share. These updates are aggregated and combined with updates from cloud servers that replay training with historical data to prevent regressions on the ASR model. These innovations allow for 10% relative improvement in word error rate (WER) on new use cases with minimal degradation on other test sets in the absence of strong-supervision signals such as ground-truth transcriptions.
Noisy students
Semi-supervised learning often uses a large, powerful teacher model to label training data for a smaller, more efficient student model. In edge devices, which frequently have computational, communication, and memory constraints, larger teacher models may not be practical.
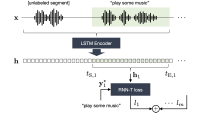
Instead, we consider the so-called noisy-student or iterative-pseudo-labeling paradigm, where the local ASR model acts as a teacher model for itself. Once the model has labeled the locally stored audio, we throw out the examples where the label confidence is too high (as they won’t teach the model anything new) or too low (likely to be wrong). Once we have a pool of strong, pseudo-labeled examples, we augment the examples by adding elements such as noise and background speech, with the aim of improving the robustness of the trained model.

We then use weak supervision to prevent error-feedback loops where the model is trained to predict erroneous self-labels. Users typically interact with conversational agents across multiple turns in a session, and later interactions can indicate whether a request has been correctly handled. Canceling or repeating a request indicates user dissatisfaction, and users can also be prompted for explicit feedback signals. These types of interactions add an additional source of ground-truth alongside the self-labels.
In particular, we use reinforcement learning to update the local models. In reinforcement learning, a model interacts repeatedly with its environment, attempting to learn a policy that maximizes some reward function.
We simulate rewards using synthetic scores based on (1) implicit feedback and (2) semantics inferred by an on-device natural-language-understanding (NLU) model. We can convert the inferred semantics from the NLU model to a feedback score by computing a semantic cost metric (e.g., fraction of named entities tagged by the NLU model that also appear in the ASR hypothesis).
To leverage this noisy feedback, we update the model using a combination of the self-learning loss and an augmented reinforcement learning loss. Since feedback scores cannot be directly used to update the ASR model, we use a cost function that maximizes the probability of predicting hypotheses with high reward scores.


In our experiments, we used data on 3,000 training rounds across 400 devices, which use self-labels and weak supervision to calculate gradients or model updates. A cloud orchestrator combines these updates with updates generated on 40 pseudo-devices on cloud servers, which compute model updates using historical transcribed data.
We see improvement of more than 10% on test sets with novel data — i.e., utterances where words or phrases are five times more popular in the current time period than in the past. The cloud pseudo-devices perform replay training that prevents catastrophic forgetting, or degradation on older data when models are updated.



