
Relational databases are typically composed of many different tables: one table might store contact data for a company’s customers; another might store data about all the company’s retail stores; another might store individual customers’ purchase histories; another might log details about customer service calls; and so on.
Customers who use the Amazon Redshift cloud data warehouse service from Amazon Web Services often have databases that consist of thousands of tables, which are constantly being updated and expanded. These tables naturally have to be distributed across multiple servers in AWS data centers.
At the 46th International Conference on Very Large Databases (VLDB), my colleagues — Yonatan Naamad, Peter Van Bouwel, Christos Faloutsos, and Michalis Petropoulos — and I presented a new method for allocating data across servers. In experiments involving queries that retrieved data from multiple tables, our method reduced communications overhead by as much as 97% relative to the original, unoptimized configuration.
For the last year, Amazon Redshift Advisor has used this method to recommend data storage configurations to our customers, enabling them to perform more-efficient database queries.
To get a sense of the problem our method addresses, consider a company that wishes to inform customers about sales at their local stores. That requires a database query that pulls customer data from the customer table and sale data from a store table.
To find the right store for each customer, the query matches entries from both tables by city. The query thus performs a join operation using the attribute “city”.
One standard way to distribute database tables across servers is to use distribution keys. For each data entry in a table (that is, each row of the table), a hash function is applied to one value of the entry — the distribution key. The hash function maps that value to the address of a server on the network, which is where the table row is stored.
In our example of a join operation, if the distribution key for both the customer table and the store table is the attribute “city”, then all customer entries and store entries that share a city will be stored on the same server. Each server then contains enough information to perform the join independently and in parallel with the other servers, without the need for data reshuffling at query time.
This is the basis of our method. Essentially, we analyze the query data for a particular database and identify the attributes whose joins involve the largest data transfers; then we use those attributes as the distribution keys for the associated tables.
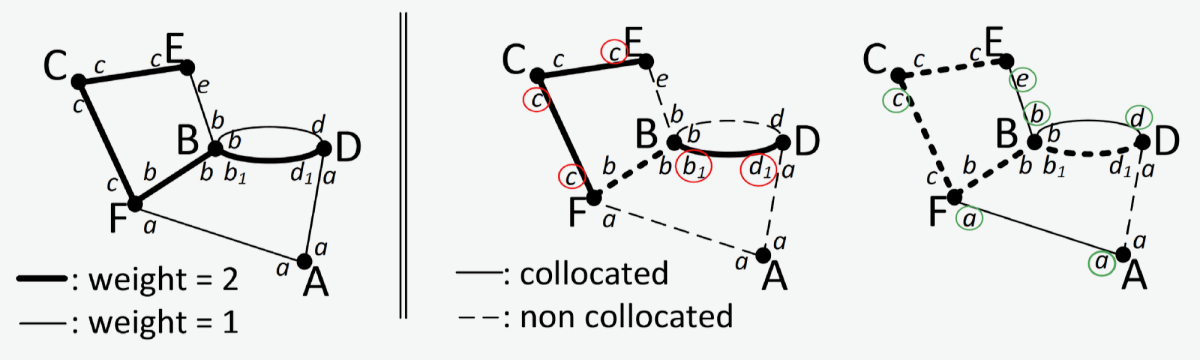
The join multigraph
The first step in this process is to create what we call a join multigraph. This is a graph in the graph-theoretical sense: a data structure consisting of vertices — often depicted as circles — and edges — usually depicted as line segments connecting vertices. The edges may also have numbers associated with them, known as weights.
In the join multigraph, the vertices are tables of a database. The edges connect attributes of separate tables on which join operations have been performed, and the edge weights indicate the data transfer required by joins between these attributes.
Our goal is now to partition the graph into pairs of vertices, each connected by a single edge (a single attribute pair), such that we maximize the cumulative weight of all the edges. Unfortunately, in our paper, we show that this problem is NP-complete, meaning that solving it exactly isn’t computationally practical.
We also show, however, that the optimization technique known as integer linear programming may, for any given instance of the problem, yield an optimal solution in a reasonable amount of time. So the first step in our method is to try to partition the graph using integer linear programming, with a limit on how much time the linear-programming solver can spend on the problem.
If the solver times out, then our next step is to use four different heuristics to partition the graph, and we select the one that yields the greatest cumulative weight. We call our method the best-of-all-worlds approach, since it canvasses five different possibilities and chooses the one that works best.
All four heuristics are approximate solutions of the maximum-weight matching problem, which we prove to be a special case of the problem we’re trying to solve (the distribution key recommendation problem).
Heuristics
We begin with two empty sets of distribution key recommendations. Then we select a vertex of the graph (a table) at random and identify its most heavily weighted edge. The attributes that define that edge become the recommended distribution key for the tables the edge connects, and that recommendation is added to the first empty set.
Then we repeat the process, with another randomly selected vertex, and add the resulting recommendation to the second empty set of clustering recommendations. We repeat this process, alternating between the two sets of recommendations, until none of the vertices in the graph remain unaccounted for.
Now we have two different sets of recommendations, with two different sets of vertices, and we select the one with the greater cumulative edge weights. The differences between our four heuristics lie in the processes we use to add back the edges missing from the recommendation set we’ve selected — processes we’ve dubbed greedy matching, random choice, random neighbor, and naïve greedy. (Details are in the paper.)
In tests on four different data sets, our method reduced communication overhead by between 80% and 97%, savings that would directly translate to performance improvements for our customers.



