
The field of machine learning is evolving at a rapid pace, with the regular release of new models that promise improvements over their predecessors. Evaluating a new model for a particular use case, however, is a time-consuming and resource-intensive process. That poses a conundrum for online services like Amazon’s store, which are committed to offering their customers state-of-the-art technology but operate at high volume 24 hours a day.
In a paper we presented at this year’s Web Conference, we propose a solution to this conundrum. Rather than use a single model — or a pair of models, a language model and a graph neural network — to process customers’ queries, we propose using an ensemble of models, whose outputs are aggregated by gradient-boosted decision trees (GBDTs).
By using Shapley values to determine how much each model contributes to the GBDTs’ final decision, we can rank the models by utility. Then, depending on the computational resources available, we keep only as many of the most-useful models as are practical to run in parallel.
A new model, which hasn’t yet been thoroughly evaluated for a particular use case, can be trained on whatever data is available and added to the ensemble, where it takes its chances with the existing models. Shapley value analysis may remove it from the ensemble, or it may determine that the new model has rendered an existing model obsolete. Either way, the customer gets the benefit of the best current technology.
We tested our approach using our Shopping Queries Dataset, a public dataset that we released as part of a 2022 challenge at the Conference on Knowledge Discovery and Data Mining. The dataset consists of millions of query-product pairs in three languages, where the relationships between queries and products have been labeled according to the ESCI scheme (exact, substitute, complement, or irrelevant). We trained three large language models (LLMs) and three graph neural networks (GNNs) on the dataset and then used three different metrics (accuracy, macro F1, and weighted F1) to compare them to an ensemble of all six, which used our GBDT-based approach. Across the board, the ensemble outperformed the individual models, often dramatically.

ESCI classification
Historically, information retrieval models have been evaluated according to the relevance of the results they return; Amazon developed the ESCI scheme as a finer-grained alternative. Given a query, a product can be classified as an exact match (the brand and/or make specified in the query); as a substitute (a product in the same product class, but from a different manufacturer); as a complement (a complementary product, such as a phone case when the query is for a phone); or as irrelevant (an important classification, as it applies to the large majority of products for a given query).
There are two principal ways to do ESCI classification: one is to fine-tune a language model, which bases its output solely on the text of the product description and the query, and the other is to use a GNN, which can factor in observed relationships between products and between products and queries.
For instance, at Amazon’s store, we build graphs that capture information about which products in different categories tend to be purchased together, which products tend to be viewed together in the course of a single search session, which products are most frequently purchased in connection with particular query terms, and so on.
GNNs map graph information to a representation space in an iterative process, first embedding the data associated with each node; then creating new embeddings that combine the embeddings of nodes, their neighbors, and the relationships between them; and so on, usually to a distance of one to four hops. GNNs fine-tuned on the ESCI task thus factor in information beyond the semantic content of queries and product descriptions.
Model ensembles
At Amazon, we’ve found that combining the outputs of fine-tuned LLMs and GNNs usually yields the best performance on the ESCI task. In our WebConf paper, we describe a general method for expanding the number of models we include in our ensemble.
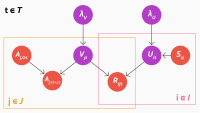
The outputs of the separate models are aggregated by GBDTs. A decision tree is a model that makes a series of binary decisions — usually, whether the value of a particular data feature exceeds some threshold. The leaves of the tree are correlated with particular data classifications.
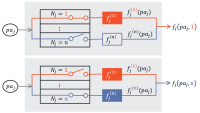
To calculate how much each model in our ensemble contributes to the final output, we use Shapley additive explanations, a method based on the game-theoretical concept of Shapley values. With Shapley values, we systematically vary the inputs to the GBDT model and track how each variation propagates through the decision trees; the Shapley value formalism provides a way to use that data to estimate aggregate effects across all possible inputs.
This, in turn, allows us to calculate how much each model in the ensemble contributes to the GBDT model’s output. On that basis, we can select only the most useful models for inclusion in our ensemble — up to whatever threshold we deem computationally practical.
Of course, running an ensemble of models is more computationally expensive than running a single model (or a pair of models, one language model and one GNN). But in our paper, we describe several techniques for making ensemble models more efficient, such as caching the labels of previously seen query-product pairs, for later reuse, and precomputing the GNN embeddings for the neighborhoods around frequently retrieved products. Our experiments show that ensemble models should be practical for real-time deployment.



