
The idea of using arrays of microphones to improve automatic speech recognition (ASR) is decades old. The acoustic signal generated by a sound source reaches multiple microphones with different time delays. This information can be used to create virtual directivity, emphasizing a sound arriving from a direction of interest and diminishing signals coming from other directions. In voice recognition, one of the more popular methods for doing this is known as “beamforming”.
Usually, such microphone array techniques address only the speech enhancement problem, or separating speech from noise. Speech recognition — converting speech to text — has been treated as a separate problem. But the literature suggests that tackling each problem separately yields a suboptimal solution.
In a pair of papers at this year’s International Conference on Acoustics, Speech, and Signal Processing, we present a new acoustic modeling framework that unifies the speech enhancement and speech recognition optimization processes. The unified acoustic model is optimized solely on the speech recognition criterion. In experiments, we found that a two-microphone system using our new model reduced the ASR error rate by 9.5% relative to a seven-microphone system using existing beamforming technology.
The first paper describes our multi-microphone — or “multichannel” — modeling method. Classical beamforming technology is intended to steer a single beam in an arbitrary direction, but that’s a computationally intensive approach. With the Echo smart speaker, we instead point multiple beamformers in different directions and identify the one that yields the clearest speech signal. That’s why Alexa can understand your request for a weather forecast even when the TV is blaring a few yards away.
Traditionally, the tasks of computing the beamformers’ directions and identifying the speech signal are performed by separate, hand-coded algorithms. We replace both with a single neural network.
When one of today’s Echo devices is deployed to a new acoustic environment, it adapts its beamformers accordingly, on the fly. Training our model on a large amount of data from various acoustic environments eliminates the need for this type of adaptation.
In the traditional model, the output of the beamformer passes to a feature extractor. Most ASR systems — including the ones we’ve been using for Alexa — represent input signals using the log filter-bank energy (LFBE). LFBEs are snapshots of the signal energies in multiple frequency bands, but the sizes of the bands are irregular. This is an attempt to capture the dynamics of the human auditory system, which can make finer discriminations in lower frequency ranges than in higher ones.
After extraction, the LFBEs are normalized against an estimate of the background noise. Again, we replace both of these steps with a single neural network.
In both the traditional model and ours, the output of the feature extractor passes to a neural network that computes the probabilities that the features correspond to different “phones”, the shortest units of phonetic information. Our model thus consists of three stacked neural networks, which can be jointly optimized during training.
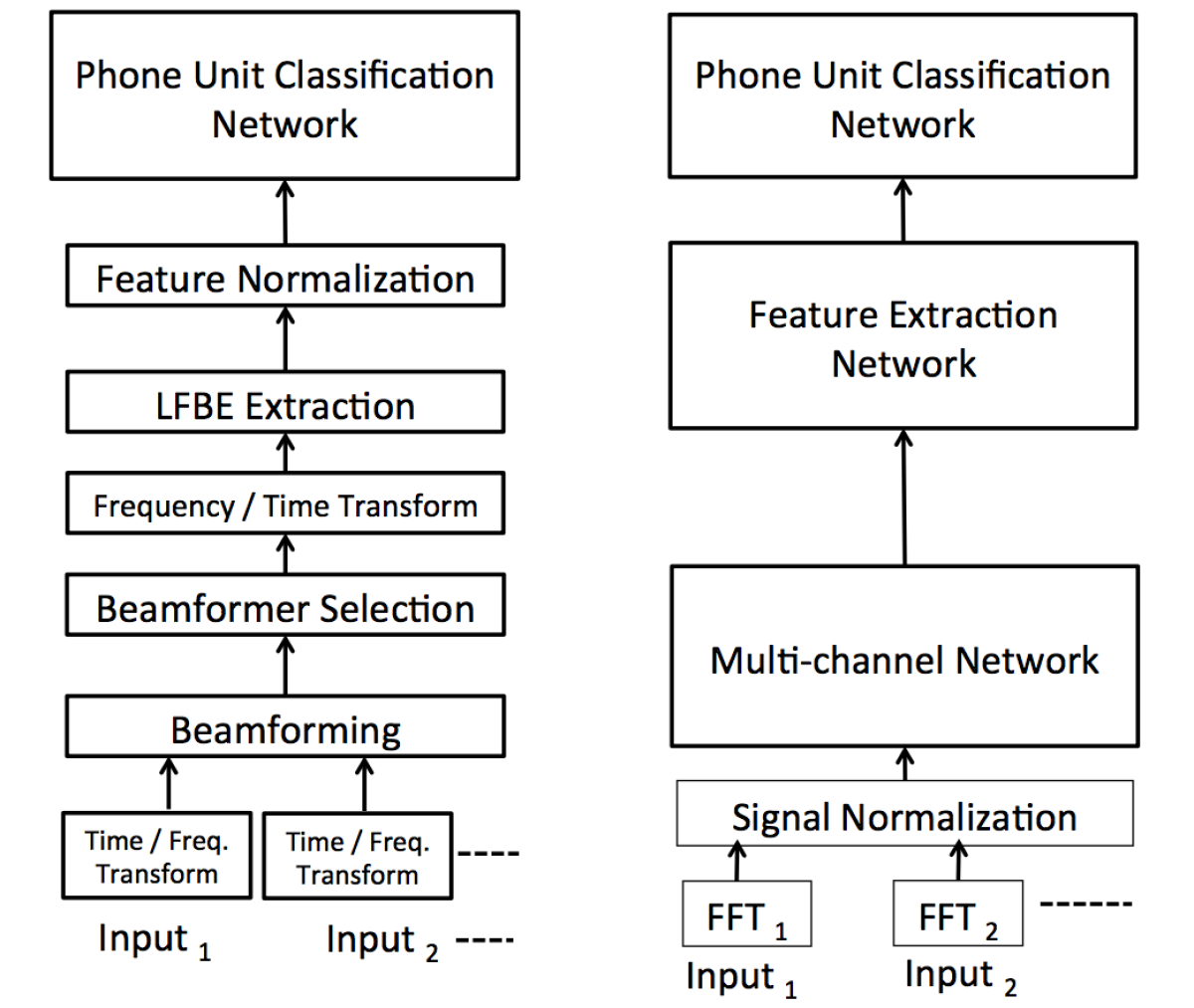
We find that performance improves, however, if we initialize each component of the model separately. So, for instance, before training the whole model end to end, we initialize the first network with specific beamformers' look directions. Similarly, we initialize the feature extractor on LFBEs. The feature extraction and speech recognition networks can also be initialized with single-channel data, which may be more plentiful than multichannel data, to further improve their performance.
In the same way that diverse training data enables the model to handle diverse acoustic environments, it also enables it to handle diverse microphone configurations. In our second paper, we show that, by training the network on data from devices with different microphone arrangements, and different distances between microphones, we render it versatile enough to improve ASR on a range of devices.
Among other advantages, this means that the ASR systems of new devices, or less widely used devices, can benefit from interaction data generated by devices with broader adoption.
Acknowledgments: Arindam Mandal, Brian King, Chris Beauchene, Gautam Tiwari, I-Fan Chen, Jeremie Lecomte, Lucas Seibert, Roland Maas, Sergey Didenko, Zaid Ahmed



