


Multitask learning (MTL) typically involves jointly optimizing the losses of a set of tasks. One naive approach is to simply minimize the sum of the losses. However, the convergence speeds of the tasks can differ according to task difficulty. This naive training approach is usually suboptimal, because the model can end up overfitting some tasks and underfitting others.
To address this issue, many existing methods aim to balance the learning speed across tasks, by facilitating or inhibiting the learning of each individual task, such that all tasks have roughly the same convergence rate. These methods include applying static loss weights, dynamically adjusting loss weights during training, and manipulating the gradients of different tasks.

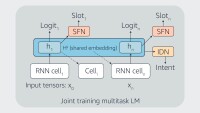
In a paper we presented in the NAACL 2022 industry track, we propose a method for achieving convergence in MTL that improves on approaches that artificially enforce the same convergence rate across tasks. Instead, we let the tasks converge on their own schedules, and when a task converges, we switch to a knowledge distillation (KD) loss in order to keep the task's performance at the best level while the model learns the remaining tasks. The figure below illustrates the idea.
We evaluate the proposed method in two five-task MTL setups consisting of proprietary e-commerce datasets. The results show that our method consistently outperforms existing loss-weighting and gradient-balancing approaches, achieving average improvements of 0.9% and 1.5%, respectively over the best-performing baseline model in the two setups.
Asynchronous convergence via knowledge distillation
Our proposed method works as follows:
- After the model converges on a task, we use its best-performing parameter values and run inference on the task’s training set, recording the predictions.
- For the remaining training steps, we use these predictions as soft labels to train the model on the converged task, while using real labels to train on the remaining tasks.
- We repeat this until all tasks converge.

With this method, we experiment with two different training settings:
- Joint setting: Train on all tasks together and switch to KD losses as the model converges on different tasks.
- Sequential setting: Start training on a single task and add one new task at a time after the previous task converges; use KD losses for all converged tasks, and use real labels for the new task.
Experiments and results
We evaluate our approach using two five-task setups, where the tasks are proprietary e-commerce tasks. The tasks in the first setup are more similar to each other and are all classification tasks, while the ones in the second setup are more diverse in terms of application and task type. We evaluate on these two benchmarks to test the effectiveness and robustness of our method in different MTL scenarios.
In both setups, both the joint and sequential settings substantially outperform the baseline methods. Our best results are, on average, higher by 0.9% and by 1.5% than the best-performing baseline, respectively, in the two setups.
Below are the validation curves of the baseline that simply minimizes the sum of task losses and of our proposed joint and sequential settings in the first five-task setup. We can observe that none of the tasks in the joint and sequential settings shows a downward trend, suggesting that the method is indeed effective in maintaining the performance of converged tasks at the best level while the model learns the remaining tasks.




