

Semantic segmentation is the task of automatically labeling every pixel of a digital image as belonging to one of many classes (person, cat, airplane, table, etc.), with applications in content-based image retrieval, medical imaging, and object recognition, among others.

Machine-learning-based semantic segmentation systems are typically trained on images in which object boundaries have been meticulously hand-traced, a time-consuming operation. Object detection systems, on the other hand, can be trained on images in which objects are framed by rectangles known as bounding boxes. For human annotators, hand-segmenting an image takes, on average, 35 times as long as labeling bounding boxes.
In a paper we presented last week at the European Conference on Computer Vision (ECCV), we describe a new system, which we call Box2Seg, that learns to segment images using only bounding-box training data, an example of weakly supervised learning.
In experiments, our system provided a 2% improvement over previous weakly supervised systems on a metric called mean intersection over union (mIoU), which measures the congruence between the system’s segmentation of an image and manual segmentation. Our system’s performance was also comparable to that of one pretrained on general image data and then trained on fully segmented data.
Furthermore, when we trained a system using our weakly supervised approach, then fine-tuned it on fully segmented data, it improved upon the performance of the system pretrained on general image data by 16%. This suggests that, even when segmented training data is available, pretraining with our weakly supervised approach still has advantages.
Noisy labels
Our approach is to treat the bounding boxes as noisy labels. We treat each pixel inside a box as having been labeled as part of the object whose boundary we are trying to find; some of those pixels, however, have been labeled incorrectly. All the pixels outside a box we treat as correctly labeled background pixels.
During training, inputs to our system pass through three convolutional neural networks: an object segmentation network and two ancillary networks. During operation, we discard the ancillary networks, so they don’t add to the complexity of the deployed system.
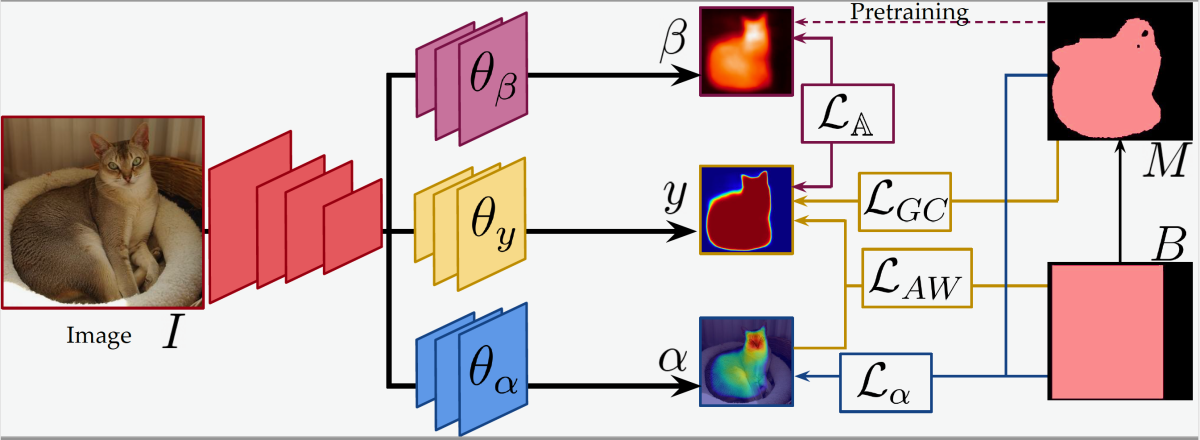
One of the ancillary networks performs pairwise comparisons between pixels in an image, attempting to learn general methods of distinguishing background and foreground. Intuitively, it’s looking for pixels inside the bounding box that are similar to the correctly labeled background pixels outside the box and clusters of pixels inside the box that are dissimilar from each other. We call this network the embedding network because it learns a vector representation — an embedding — of pixels that captures just those properties useful for distinguishing background and foreground.
We pretrain the embedding network using the relatively coarse segmentations provided by a standard segmentation algorithm called GrabCut. During training, the embedding network’s output provides a supervisory signal to the object segmentation network; that is, one of the criteria we use to evaluate the embedding network’s performance is the accord of its output with that of the embedding network.

The other ancillary network is a label-specific attention network. It learns to identify visual properties that recur frequently across pixels inside bounding boxes with the same labels. It could be thought of as an object detector whose output is not an object label but rather an image map highlighting pixel clusters characteristic of a particular object class.

The label-specific attention network is useful only for object classes that it sees during training; its output could be counterproductive with classes of objects it wasn’t trained on. But during training, it — like the embedding network — provides a useful supervisory signal, which can help the object segmentation network learn to perform more general segmentations.
In experiments using a standard benchmark data set, we found that, using only bounding-box training data, Box2Seg outperformed 12 other systems trained on fully segmented training data. When a network trained using Box2Seg was fine-tuned on fully segmented data, the performance improvement was even more dramatic. This suggests that weakly supervised training of object segmentation could be useful when fully segmented training data is not available — and even when it is.



