
When a customer clicks on an item in a list of product-search results, it implies that that item is better than those not clicked. “Learning to rank” models leverage such implicit feedback to improve search results, comparing clicked and unclicked results in either “pairwise” (comparing pairs of results) or listwise (judging a results position within the list) fashion.
A problem with this approach is the lack of absolute feedback. For instance, if no items in the selection are clicked, it’s a signal that none of the results was useful. But without clicked items for comparison, learning-to-rank models can do nothing with that information. Similarly, if a customer clicks on all the items in a list, it could indicate that all the results were useful — but it could also indicate a fruitless search to find even one useful result. Again, learning-to-rank models can’t tell the difference.
In a paper we’re presenting at this year’s International Conference on Knowledge Discovery and Data Mining (KDD), we describe a new approach to learning to rank that factors in absolute feedback. It also uses the type of transformer models so popular in natural-language processing to attend to differences among items in the same list to predict their relative likelihood of being clicked.
In experiments, we compared our approach to a standard neural-network model and to a model that used gradient-boosted decision trees (GBDTs), which have historically outperformed neural models on learning-to-rank tasks. On three public datasets, the GBDTs did come out on top, although our model outperformed the baseline neural model.
On a large set of internal Amazon search data, however, our approach outperformed the baselines across the board. We hypothesize that this is because the public datasets contain only simple features and that neural rankers become state-of-the-art only when the dataset is large and has a large number of features with complicated distributions.
Absolute feedback
Although the items in the public datasets are scored according to how well they match various search queries, we are chiefly interested in learning from implicit feedback, since that scales much better than learning from labeled data.

We thus assign each item in our datasets a value of 0 if it isn’t clicked on, a value of 1 if it is clicked on, and a value of 2 if it’s purchased. We define the absolute value of a list of items as the value of its single highest-value member, on the assumption that the purpose of a product query is to identify a single item for purchase. A list with one item that results in a purchase thus has a higher value than a list all of whose items were clicked without purchase.
As input, our transformer model receives information about each product in a list of products, but it also receives a class token. For each input, it generates a vector representation: the representations of the products capture information useful for assessing how well they match a product query, but the representation of the class token captures information about the list as a whole.
The representations pass to a set of scoring heads, which score them according to their relevance to the current query. During training, however, the score of the class token and the product scores are optimized according to separate loss functions.
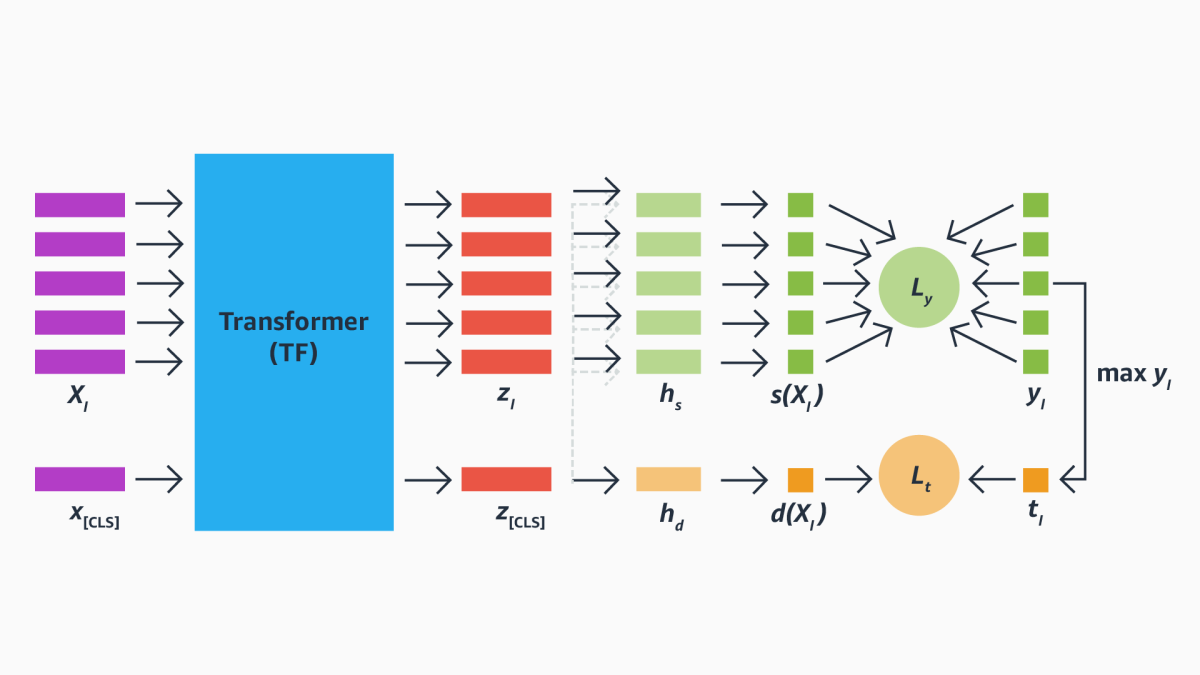
The transformer’s key design feature is its attention mechanism, which learns how heavily to weight different input features according to context. In our setting, the attention mechanism determines which product features are of particular import given a product query.

As an example, transformers are capable of learning that a 10-dollar item should be contextualized differently in a list of 20-dollar items than in a list five-dollar items. Like the scoring of the class token, this contextualization is trained on the overall, absolute feedback, which allows our model to learn from lists that generate no clicks or purchases.
Does it help?
Although our results on proprietary data were more impressive, we evaluated our proposal on publicly available datasets so that the research community can verify our results. On the internal data at Amazon Search, where a richer set of features is available, our model achieves better performance than any of the other methods, including strong GBDT models.
On the strength of those results, we are encouraged to keep learning from customer feedback. The user’s perspective is central to ranking problems, and click and purchase data appears to be a signal ripe for further research.



