Visual product inspection is crucial in manufacturing, retail, and many other industries. Shipping damaged items erodes customer trust and incurs additional costs for refunds or replacements. Today, there is a growing interest in automating the inspection process to increase throughput, cut costs, and accelerate feedback loops.
Anomaly detection is predicting whether a product deviates from the norm, indicating possible defects; anomaly localization is the more complex task of highlighting anomalous regions using pixel-wise anomaly scores. Despite advances in computer vision, there is a gap between research and the deployment of anomaly localization methods to real-world production environments. Most existing models focus on product-specific defects, so they’re of limited use to manufacturers dealing with different products.

In a paper we recently published in Elsevier’s Journal of Manufacturing Systems, we present the first benchmarking framework — a newly labeled product-agnostic dataset and suggested evaluation protocol — for real-world anomaly localization. We relabeled anomalous examples from existing datasets, capturing higher-level human-understandable descriptions, to produce a new dataset that can be used to evaluate models in a general, product-agnostic manner.
We also identified optimal modeling approaches, developed efficient training and inference schemes, and performed an ablation study on various techniques for estimating the optimal pixel-intensity thresholds for segmenting anomalous and non-anomalous regions of an image. Users from diverse industries can use this benchmarking framework to deploy automated visual inspection in production pipelines.
Benchmarking framework
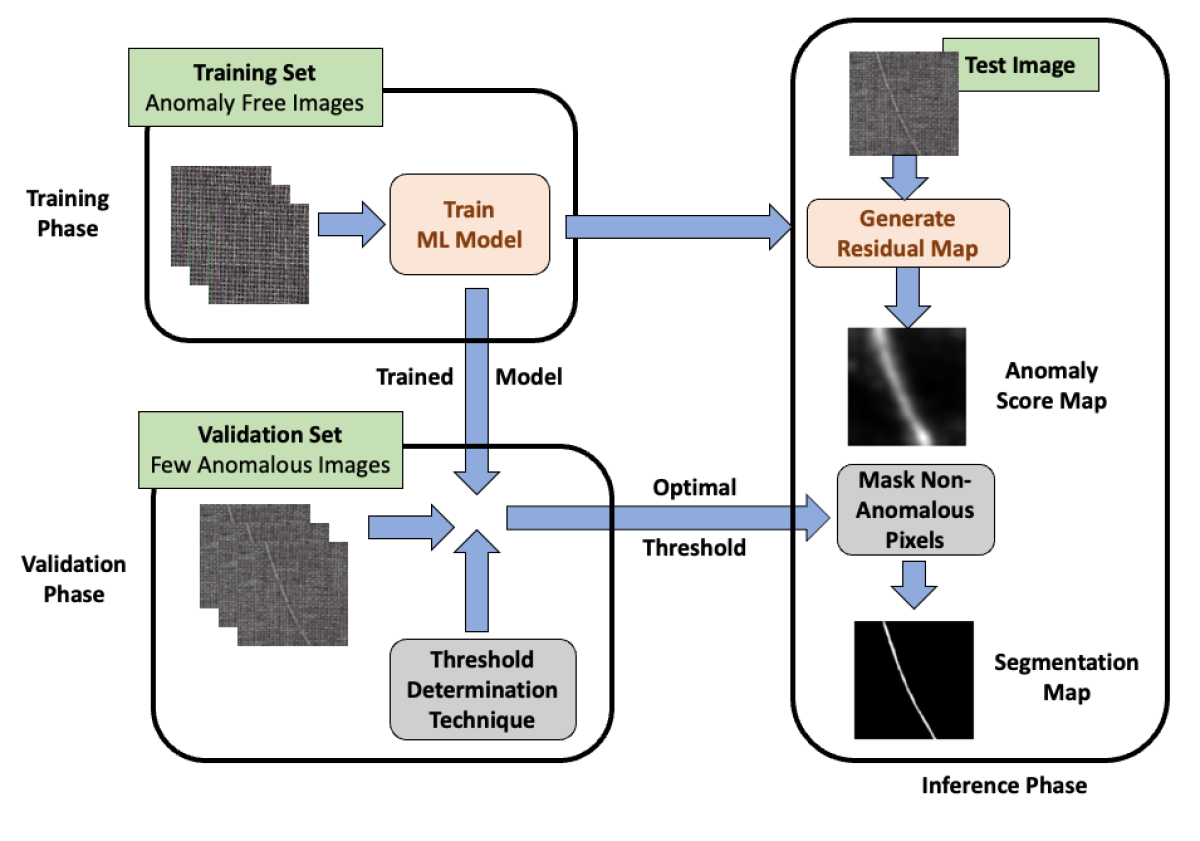
Using supervised learning to train anomaly localization models has major drawbacks: compared to images of defect-free products, images of defective products are scarce; and labeling defective-product images is expensive. Consequently, our benchmarking framework doesn’t require any anomalous images in the training phase. Instead, from the defect-free examples, the model learns a distribution of typical image features.
Then, during the validation phase, we need only a few anomalous images to determine where on the distribution of anomaly scores the boundary between normal and anomalous pixels should fall. At inference time, the trained model generates an anomaly score map to highlight anomalies in each input image. Then, using the optimal pixel-intensity threshold, it computes a segmentation map, masking the non-anomalous pixels.
Our benchmarking framework has three main building blocks: the product-agnostic dataset, a set of models, and a set of evaluation approaches. We sort modeling approaches into four broad categories, depending on how they generate the anomaly score map: reconstruction, attribution map, patch similarity, and normalizing flow. The framework includes a state-of-the-art representative of each category.

For practical use, anomaly localization should follow a twofold evaluation procedure: validation metrics don’t require a threshold value, but inference metrics do. We emphasize efficient determination of threshold values, addressing a gap in previous research. Different metrics have advantages in different real-world use cases: our benchmark provides a detailed analysis of inference (threshold-dependent) metrics, comparing four modeling approaches with five different threshold estimation techniques.
Product-agnostic dataset
To create a product-agnostic dataset, we reclassify the anomalous images in two existing datasets (MVTec and BTAD) according to higher-level, more-general categories. The anomalous images in both datasets include pixel-precise anomaly segmentation maps highlighting defects and masking defect-free regions.
We first categorize product images based on the presence or absence of a background. An image with a background features a product (e.g., a bottle or a hazelnut) against a backdrop. In an image without a background, a close-up of the product (e.g., the weave of a carpet or the texture of wood) accounts for all the pixels in the image.

We further label anomalous product images according to four product-agnostic defect categories:
| Structural | Distorted or missing object parts or some considerable damage to product structure. Examples: holes, bends, missing parts, etc. |
| Surface | Defects mostly restricted to smaller regions on product surface, requiring relatively less repair. Examples: scratches, dents, iron rust, etc. |
| Contamination | Defects indicating the presence of some foreign material. Examples: glue slip, dust, dirt, etc. |
| Combined | Defects that combine any of the above three types, with multiple connected components in the ground truth segmentation map. Example: a hole in a contaminated background. |

The labeling was done by a team of annotators using a custom-built user interface. The annotators manually labeled each anomalous image by comparing it to a defect-free product image, consulting the corresponding ground truth segmentation map for an appropriate defect categorization. These product-agnostic labels are now available in the paper’s supplementary materials. Researchers can use these labels to perform new experiments and develop product-agnostic benchmarks.
Benchmarking a new product
The benchmarking framework offers valuable insights and guidance in the choice of modeling approach, threshold estimation method, and evaluation process. As an efficient starting point for a manufacturer coming in with a new product, we suggest using the patch distribution model (PaDiM), a patch-similarity-based approach, and estimating the threshold from the IoU (intersection over union) curve. If surface defects are more likely to appear, the conditional-normalization-flow (CFLOW) model, a normalizing-flow-based approach, may be preferable to PaDiM. While highlighting the limitations of validation metrics, we underscore that IoU is a more reliable inference metric for estimating segmentation performance.
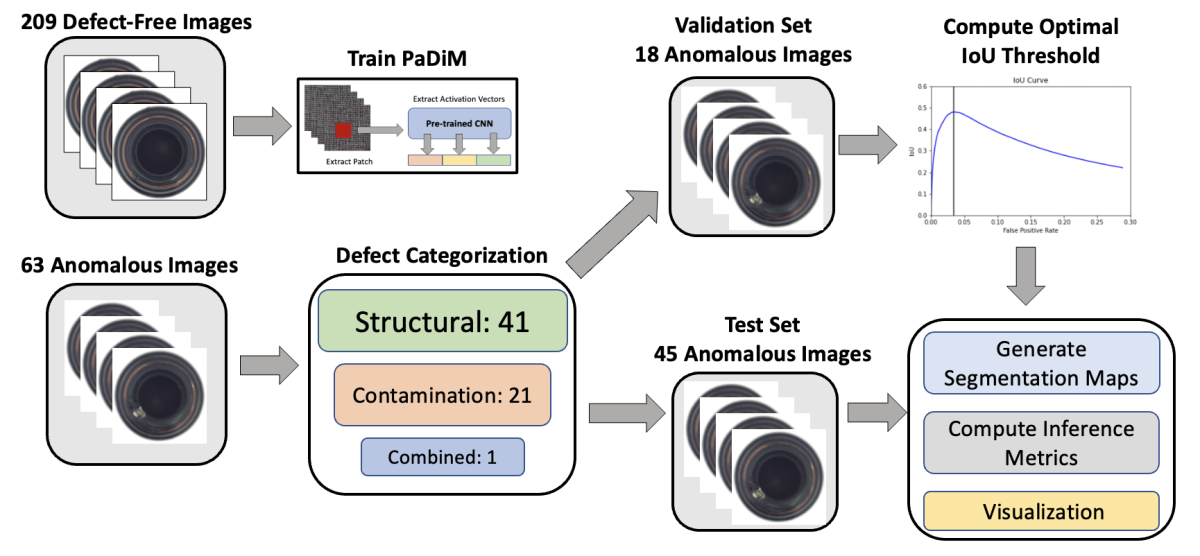
To illustrate the process, consider the product bottle from the MVTec dataset. The dataset features 209 normal and 63 anomalous images of the bottle. The first step is to annotate the anomalous images as per the product-agnostic categorization; this yields 41 images featuring structural defects, 21 featuring contamination, and one featuring combined defects. Given this proportion of defects, PaDiM should be the appropriate modeling approach, with the optimal threshold determined from the IoU curve. The next steps involve training PaDiM on normal images, estimating the threshold using the validation set, generating segmentation maps for test set images, and visually confirming defective regions for domain understanding.
We have released our benchmark in the hope that other researchers will expand on it, to help bridge the gap between the impressive progress on anomaly localization in research and the challenges of real-world implementation.