
Most state-of-the-art computer vision models depend on supervised learning, in which labeled data is used for training. But labeling is costly, and the cost is compounded in the case of semantic segmentation, where every pixel in an image is associated with a label.
Even costlier is semantic-segmentation labeling in video. In fact, it’s so costly that, so far, there is no public video dataset with per-frame labels; only a sparse sampling of frames is labeled. But per-frame annotation would enable more robust model training and evaluation.
At this year’s Winter Conference on Applications of Computer Vision (WACV), my colleagues and I will propose a novel human-in-the-loop framework for generating semantic-segmentation annotations for full videos that uses annotators’ time much more efficiently.
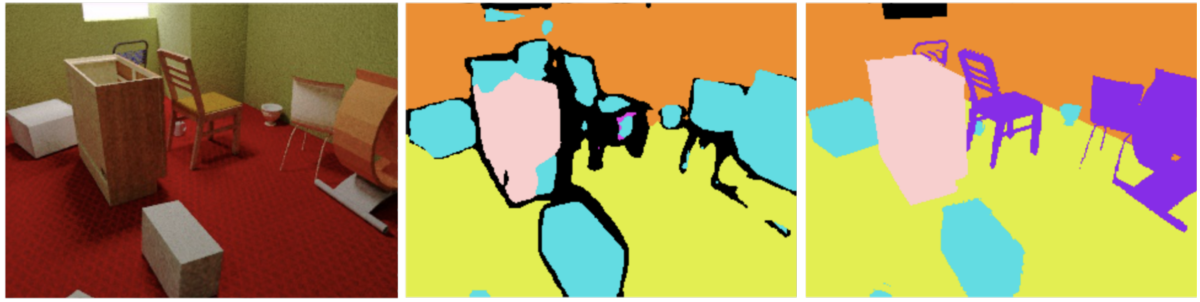
Our method alternates between active sample selection, which picks the most important samples for manual annotation, and test-time fine-tuning, which propagates the manual annotations to neighboring frames of video. The two steps are repeated multiple times to ensure annotation quality.
In experiments, our approach reduced the number of clicks required for annotation of an entire video by up to 73% while preserving label accuracy (a mean intersection over union greater than 95% of ground truth).
Test-time fine-tuning
We begin with a network that has been pretrained to perform semantic segmentation on video, and our goal is to adapt it to a particular input video, so that it can help label that video with very high accuracy.

Our approach is inspired by how human annotators handle video annotation tasks. Given a target frame, an annotator will naturally analyze neighboring frames to determine the correct categories of objects. The annotator will also refer to existing annotations within the same video.
We propose a new loss function that factors in these two information sources to adapt the pretrained model to the input video. One part of the loss penalizes inconsistent semantic prediction between consecutive frames. (The correspondence between frames is built from optical flow, which represents the relative motion of objects across frames.) The second part penalizes predictions that are inconsistent with existing human annotations.
Active sample selection
In each iteration of our procedure, the model is fine-tuned on samples that are actively selected by our algorithm and labeled by annotators. This is a type of active learning, which seeks to automatically identify information-rich training examples, reducing the number of examples that need to be labeled.
One basic idea in active learning is uncertainty sampling. The idea is that if a network predicts a sample’s label with little confidence, the sample should be selected for manual annotation.

By itself, however, uncertainty sampling has shortcomings. For instance, a number of samples might yield low-confidence predictions because they have the same visual features, and uncertainty sampling will add them all to the dataset, when a representative sampling of them would be adequate.
To make our selection strategy comprehensive, we further require our samples to be different from each other, an approach known as diversity sampling. We adopt a technique known as clustering-based sampling, which naturally yields a diverse selection of samples.
First, using the feature set that the segmentation network has learned so far, we cluster unlabeled samples in the embedding space. Then we select centroid samples — the samples closest to the centers of the clusters — for annotation.
To combine uncertainty sampling and diversity sampling, we first select the most uncertain half of the samples and cluster them into b clusters, where b is the annotation budget (the maximum allotted number of annotations) for one iteration. Then, we select the b cluster centroids and send them to human annotators. In this way, we select samples of high uncertainty that are different from each other.

Annotate frame, rectangular patch, or superpixel?
During active sample selection, we experimented with multiple sample granularities. The user could determine whether to annotate whole frames (pixel by pixel), rectangular patches, or superpixels — irregularly shaped clusters of pixels that are grouped together according to visual similarity.

We observed that the optimal granularity is not fixed but depends on the desired level of annotation quality. For example, to achieve a label accuracy of 80% mean intersection over union (mIoU), annotating 16-by-16-pixel rectangular samples require the fewest annotation clicks. To achieve a label accuracy of 95% mIoU, on the other and, annotating frame samples required the fewest annotation clicks.

Another interesting finding from our experiments involves the quality of object boundaries in the network’s predictions. Models trained on frame samples outperform models trained on samples with different granularities. This is probably because frame-level annotation provides the richest semantic/boundary information. Superpixels, on the other hand, are usually composed of pixels from the same objects, so they impart less information about object boundaries. This is another factor to consider when you decide which annotation granularity to use for your task.



