
Today’s large machine learning models — such as generative language models or vision-language models — are so big that the process of training them is typically divided up across thousands or even tens of thousands of GPUs. Even with all that parallelism, training still frequently takes months.
With such a massive deployment of resources, hardware and software failures are common, often occurring multiple times a day. To reduce wasted work when resources fail, the large-model training procedure involves checkpointing, or regularly copying the model states to storage servers on the network. That way, if a resource fails, its most recent checkpoint can be retrieved and either reloaded or copied to a new machine, and training can continue.

Because the models are so large, checkpointing to remote storage can take a while — maybe 30 or 40 minutes. So it’s done sparingly, usually around every three hours. If a resource fails, and the training has to back up to the last checkpoint, it could mean the loss of several hours’ work. And on top of that, it can take 10 to 20 minutes just to retrieve checkpoints from storage. If failures happen several times a day, they can seriously slow down training.
In a paper my colleagues and I are presenting at this year’s Symposium on Operating System Principles (SOSP), we describe a checkpointing procedure that, instead of relying on remote storage, stores checkpoints in the CPU memory of the machines involved in model training. This makes both checkpointing and retrieval much more efficient, to the point that we can checkpoint after every training step, so that failures don’t set training back as far. In our experiments, this approach reduces the training time lost to hardware or software failures by about 92%.
In our paper, we explain how we address two major challenges to our approach: optimal checkpoint placement on machines and optimal traffic scheduling to accommodate both checkpointing and training.
GPU training
A typical GPU machine includes CPUs for general processing tasks — including allocating work to the GPUs — and eight or so GPUs, which have a special-purpose architecture optimized for massively parallel tasks such as model training. Each GPU has its own memory, but the CPU memory is much larger.

Training a large machine learning (ML) model — or foundation model — requires clusters of thousands of such GPU machines. Communication between machines in a cluster is much higher bandwidth than communication with remote storage servers, which is one of the reasons that CPU checkpointing is so efficient.
Optimal checkpoint placement
In our approach, which we call Gemini, each machine checkpoints to an onboard “RAM drive” — that is, a dedicated portion of its own CPU memory. This is sufficient for recovery from software failures, which typically don’t compromise the content of RAM drives. To recover from hardware failures, each machine also checkpoints to the CPU memory of at least one other machine in the cluster.
The person training the model can specify how many copies of each checkpoint should be stored on the network. Typically, that number will be two or three, but let’s call it M. Gemini divides the training cluster into groups of M machines each, and each machine checkpoints to the CPU memories of the other machines in its group.
In our paper, we prove that if the number of machines is evenly divisible by M, this checkpoint placement is optimal. If the number of machines is not evenly divisible by M, we create as many M-machine groups as possible without creating a one-machine group (which can result in one group with M + 1 machines).
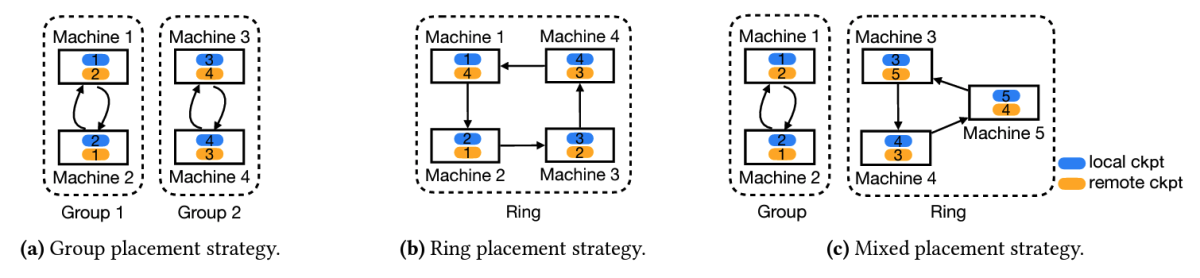
Gemini stores checkpoints for failure recovery in CPU memory, while storing checkpoints for other purposes, such as transfer learning and model debugging, in remote storage. This procedure is tiered, so that if the checkpoint is not in local CPU memory, Gemini attempts to retrieve it from the CPU memory of adjacent machines; if it is still unavailable, Gemini looks for it in remote storage.
Interleaved communication
During large-model training, GPUs will share model weights for computation. Checkpointing to CPU memory uses the same communication network that training traffic does. We need to make sure that the two uses don’t get in each other’s way.
Our approach includes a system profiler that learns the lengths of the idle time spans between training traffic and schedules checkpoint traffic for those time spans.
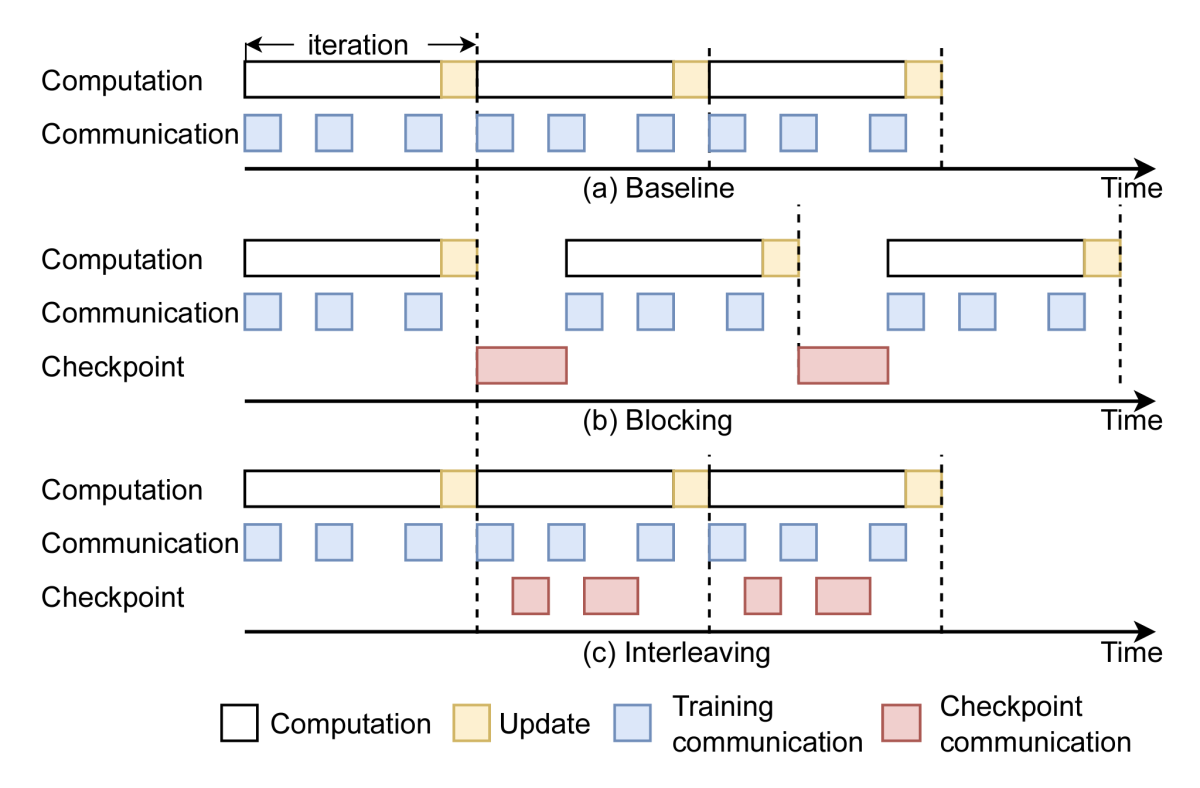
This approach poses some difficulties, though. A GPU receiving part of a checkpoint transmission must store it locally before copying it to CPU memory, but GPU memory is limited. We allocate a small amount of each GPU’s memory to checkpointing and send checkpoints in small enough chunks that they won’t overflow those allocations.

That means, however, that before the GPU can receive the next checkpoint transmission, it needs to free up its memory allocation by copying the contents to CPU memory. If we wait for that copying to complete before sending another checkpoint transmission, we waste valuable time.
So we further subdivide each GPU memory allocation into two halves and pipeline the transfer of data to CPU memory, constantly refilling one half of the allocation while emptying the other. This optimizes our use of the precious idle time between bursts of training traffic for checkpoint traffic.

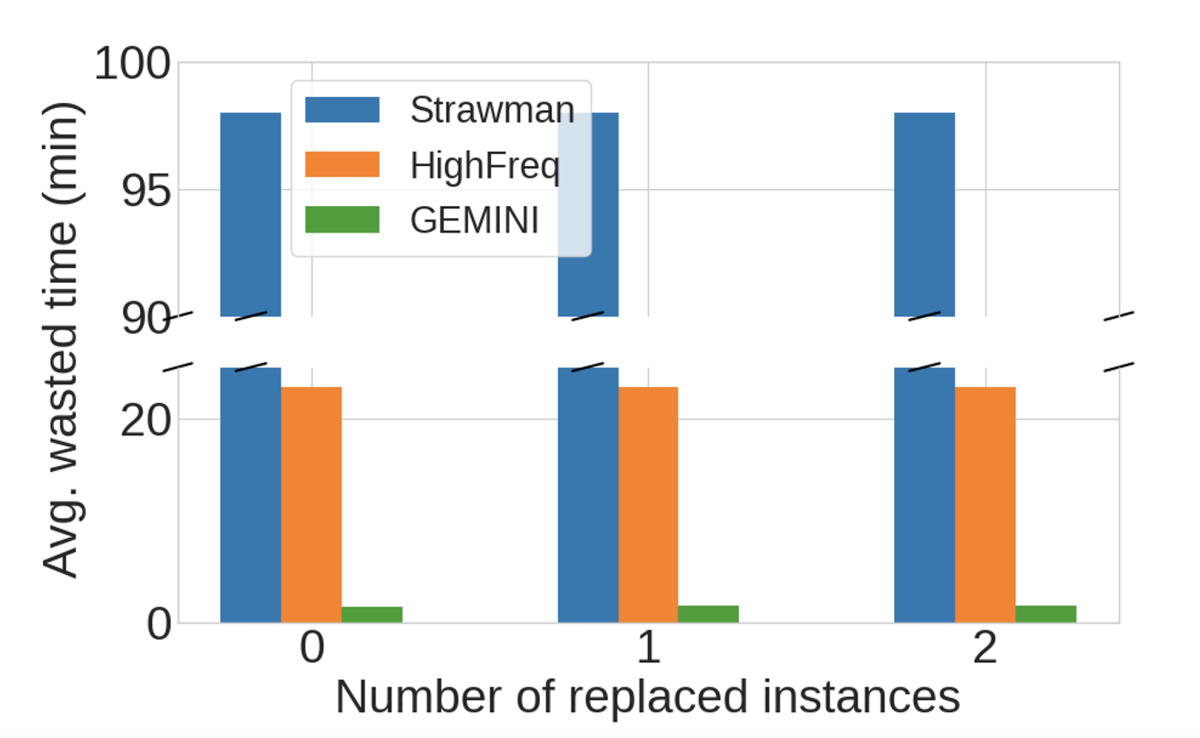
To evaluate Gemini, we used it for checkpointing during the training of three popular large language models, and as baselines, we trained the same models using two prior checkpointing procedures. In our evaluation, Gemini could checkpoint model states for every iteration, and as a consequence, it reduced the training time lost because of hardware or software failures by more than 92% relative to the best-performing baseline.
Acknowledgments: Zhen Zhang, Xinwei Fu, Yida Wang



