
Text classification is the most basic task in the field of natural-language understanding. Customer requests to Amazon Alexa, for example, are classified by domain — weather, music, smart home, information, and so on — and many natural-language-processing applications rely on parsers that classify words according to parts of speech.
For tasks in which the text classes are relatively few, the best-performing text classification systems use pretrained Transformer models such as BERT, XLNet, and RoBERTa.
But Transformer-based models scale quadratically with the input sequence length and linearly with the number of classes. For tasks with large numbers of classes — hundreds of thousands or even millions — they become impractically large.
In a paper we’re presenting this year at the Association for Computing Machinery’s annual conference on Knowledge Discovery and Data Mining (KDD), my colleagues and I describe a new method for applying Transformer-based models to the problem of text classification with large numbers of classes, or “extreme classification”.
Our model scales reasonably with the number of classes, and in experiments, we show that on the task of selecting relevant classes for a given input, it outperforms the state-of-the-art system on four different data sets.
Exploding classifiers
Typically, for natural-language-processing tasks, Transformer-based models are pretrained on large, general text corpora, learning embeddings for the words of the language, or vector representations such that associated words cluster together in the vector space. Those embeddings then serve as inputs to a new classifier, which is trained on the particular task.
Regardless of the task, the size of the Transformer model itself is fixed, usually at somewhere around 350 million parameters, where a parameter is the weight of a single connection (edge) in a neural network.
In our paper, we consider one component of the General Language Understanding Evaluation (GLUE) benchmark, the Multi-Genre Natural-Language Inference (MLNI) corpus, which contains sentence pairs that have three possible logical relationships: entailment, contradiction, or neutrality. A classifier trained to recognize these three types of relationships adds another 2,000 parameters to the model, a negligible difference.
We also consider an in-house system that suggests possible keywords for new items being added to the Amazon Store, based on their product titles (for instance, for a black digital kitchen timer, it suggests “black timer”, “kitchen timer”, “black digital timer”, and so on).
That system has about a million product categories. Training a classifier to sort product names into those categories adds more than a billion parameters to the model, almost quadrupling its size and making it much less efficient to train and operate.
We address this problem by training the Transformer-based model to assign each input to a cluster of classes instead of a single class. Then we use a simple linear classifier to select one class from the cluster. This drastically reduces the size of the Transformer-based model while preserving classification accuracy.
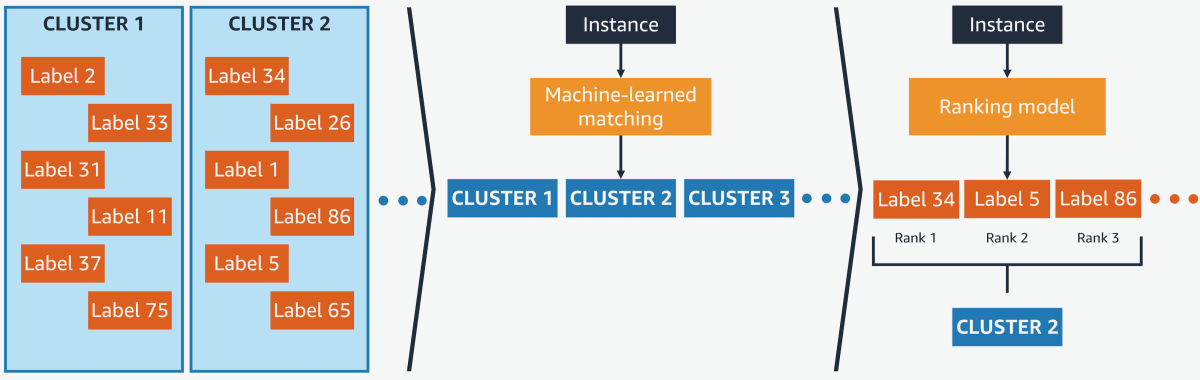
We experimented with two different methods for clustering classes. One used embeddings produced by a pretrained XLNet model, clustering class names that were near each other in the vector space. To embed a multiword class name, we averaged the embeddings of its component words.
Another method embedded sample inputs from each class, not just the names of the classes. Again, we averaged the embeddings of individual words to produce a single embedding for each input text; then we averaged the embeddings of input texts to produce an embedding for a particular task.
In our experiments, combining both of these approaches to cluster classes worked better than using either in isolation. But our model is agnostic as to which class-clustering technique we use.
To select one class from a cluster, we use a one-versus-all classifier, which, for each class in a cluster, learns to partition members of that class from non-members in the embedding space. The partition for each class is fairly inexact, but the intersection of multiple partitions can accurately identify a single class.
Negative examples
Learning partitions requires negative training examples as well as positive. We use two different methods to construct negative examples.
First, for each class in a cluster, we draw negative examples from the other classes in the same cluster. Because the classes in a given cluster are semantically related, this ensures that the negative examples will be challenging and therefore more informative to the classifier than easy examples.
We also use the Transformer-based clustering model to identify challenging negative examples. For each input, the Transformer-based model produces a list of possible cluster assignments, ranked by probability. For positive training examples in a particular class, we identify the incorrect clusters that the model consistently predicts with high probability. We then use those clusters as the basis for additional negative examples, weighted according to probability scores.
In experiments, we compared our system to nine benchmark systems on four different data sets. On the task of identifying the single best classification label for a given input, our system was the most accurate across the board.
The margin of improvement over the second-place finisher, a recent system called AttentionXML, was narrow — around 1% — and on one data set, AttentionXML was slightly more accurate on the tasks of identifying the top three labels and the top five labels. But some of the techniques that AttentionXML uses are complementary to our system’s, and it would be interesting to see whether combining the two approaches could improve performance still further.



