
A text-to-speech system, which converts written text into synthesized speech, is what allows Alexa to respond verbally to requests or commands. Through a service called Amazon Polly, text-to-speech is also a technology that Amazon Web Services offers to its customers.
Last year, both Alexa and Polly evolved toward neural-network-based text-to-speech systems, which synthesize speech from scratch, rather than the earlier unit-selection method, which strung together tiny snippets of pre-recorded sounds.
In user studies, people tend to find speech produced by neural text-to-speech (NTTS) systems more natural-sounding than speech produced by unit selection. But the real advantage of NTTS is its adaptability, something we demonstrated last year in our work on changing the speaking style (“newscaster” versus “neutral”) of an NTTS system.
At this year’s Interspeech, two new papers from the Amazon Text-to-Speech group further demonstrate the adaptability of NTTS. One is on prosody transfer, or synthesizing speech that mimics the prosody — shifts in tempo, pitch, and volume — of a recording. In essence, prosody transfer lets you choose whose voice you will hear reading back recorded content, with all the original vocal inflections preserved.
The other paper is on universal vocoding. An NTTS system outputs a series of spectrograms, snapshots of the energies in different audio frequency bands over short periods of time. But spectrograms don’t contain enough information to directly produce a natural-sounding speech signal. A vocoder is required to fill in the missing details.
A typical neural vocoder is trained on data from a single speaker. But in our paper, we report a vocoder trained on data from 74 speakers in 17 languages. In our experiments, for any given speaker, the universal vocoder outperformed speaker-specific vocoders — even when it had never seen data from that particular speaker before.
Our first paper, on prosody transfer, is titled “Fine-Grained Robust Prosody Transfer for Single-Speaker Neural Text-to-Speech”. Past attempts at prosody transfer have involved neural networks that take speaker-specific spectrograms and the corresponding text as input and output spectrograms that represent a different voice. But these tend not to adapt well to input voices that they haven’t heard before.
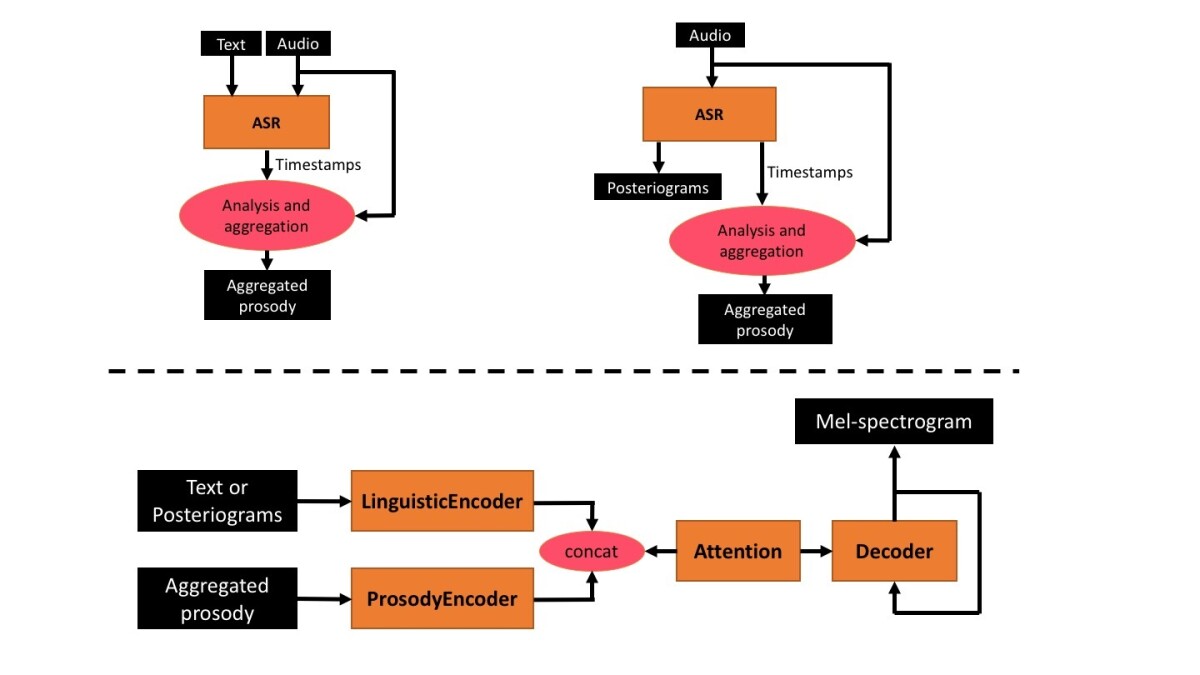
We adopted several techniques to make our network more general, including not using raw spectrograms as input. Instead, our system uses prosodic features that are easier to normalize.
First, our system aligns the speech signal with the text at the level of phonemes, the smallest units of speech. Then, for each phoneme, the system extracts prosodic features — such as changes in pitch or volume — from the spectrograms. These features can be normalized, which makes them easy to apply to new voices.
| “But Germany thinks she can manage it … ” | Original | Transferred | Synthesized |
| "I knew of old its little ways ... " | Original | Transferred | Synthesized |
| “Good old Harry … ” | Original | Transferred | Synthesized |
Three different versions of the same three text excerpts. "Original" denotes the original recording of the text by a live speaker. "Transferred" denotes a synthesized voice with prosody transferred from the original recording by our system. And "Synthesized" denotes the synthesis of the same excerpt from scratch, using existing Amazon TTS technology.
This approach works well when the system has a clean transcript to work with — as when, for instance, the input recording is a reading of a known text. But we also examine the case in which a clean transcript isn’t available.
In that instance, we run the input speech through an automatic speech recognizer, like the one that Alexa uses to process customer requests. Speech recognizers begin by constructing multiple hypotheses about the sequences of phonemes that correspond to a given input signal, and they represent those hypotheses as probability distributions. Later, they use higher-level information about word sequence frequencies to decide between hypotheses.
When we don’t have reliable source text, our system takes the speech recognizer’s low-level phoneme-sequence probabilities as inputs. This allows it to learn general correlations between phonemes and prosodic features, rather than trying to force acoustic information to align with transcriptions that may be inaccurate.
In experiments, we find that the difference between the outputs of this textless prosody transfer system and a system trained using highly reliable transcripts is statistically insignificant.
Our second paper is titled “Towards Achieving Robust Universal Neural Vocoding”. In the past, researchers have used data from multiple speakers to train neural vocoders, but they didn’t expect their models to generalize to unfamiliar voices. Usually, the input to the model includes some indication of which speaker the voice belongs to.
We investigated whether it is possible to train a universal vocoder to attain state-of-the-art quality on voices it hasn’t previously encountered. The first step: create a diverse enough set of training data that the vocoder can generalize. Our data set comprised about 2,000 utterances each from 52 female and 22 male speakers, in 17 languages.
The next step: extensive testing of the resulting vocoder. We tested it on voices that it had heard before, voices that it hadn’t, topics that it had encountered before, topics that it hadn’t, languages that were familiar (such as English and Spanish), languages that weren’t (Ahmaric, Swahili, and Wolof), and a wide range of unusual speaking conditions, such as whispered or sung speech or speech with heavy background noise.
We compared the output of our vocoder to that of four baselines: natural speech, speaker-specific vocoders, and generalized vocoders trained on less diverse data — three- and seven-speaker data sets. Five listeners scored every output utterance of each vocoder according to the multiple stimuli with hidden reference and anchor (MUSHRA) test. Across the board, our vocoder outperformed the three digital baselines and usually came very close to the scores for natural speech.
Acknowledgments: Thomas Drugman, Srikanth Ronanki, Jonas Rohnke, Javier Latorre, Thomas Merritt, Bartosz Putrycz, Roberto Barra-Chicote, Alexis Moinet, Vatsal Aggarwal



