Alexa’s Conversation Mode — which we announced last year and are launching today — represents a major milestone in voice AI. Conversation Mode will let Echo Show 8 and Echo Show 10 customers interact with Alexa more naturally, without the need to repeat the wake word.
Using a combination of visual and acoustic cues, the feature’s AI will recognize when customer speech is directed at the device and whether a reply is expected. A customer can invoke Conversation Mode by saying, “Alexa, turn on Conversation Mode” and exit by saying, “Turn off Conversation Mode”. Alternatively, Alexa will exit the mode if there is no interaction for a short period of time.

Conversation Mode enables one or more customers to engage with Alexa simultaneously. This makes detecting device directedness even harder, since a question like ‘How about a comedy?’ could be directed at Alexa or at another customer.
The feature also needs to have a low latency, to accurately detect the start of a device-directed utterance; otherwise, Alexa might not capture the full utterance. This is easier in wake-word-based interactions, as the detection of the wake word provides a defined starting point for processing an utterance.
Enabling wake-word-free interactions for Conversation Mode required innovations in several areas, including visual device directedness detection, audio-based voice activity detection, and audiovisual feature fusion.
Visual device directedness detection (CVDD)
In human communication, one cue for determining whom an utterance is directed to is the speaker’s physical orientation. Similarly, we developed a method for measuring visual device directedness by estimating the head orientation of each person in the device’s field of view.
Learn more
Read more about Alexa's new Conversation Mode on About Amazon.
The standard approach to this problem is to detect a coarse set (typically five) of facial landmarks and then estimate face orientation from them using a geometry-based technique called perspective-n-point (PnP). This method is fast but has low accuracy in real-world scenarios. An alternative is to directly train a model that classifies each image region as device directed or not and apply it to the output of a face detector. But this requires a large, annotated dataset that is expensive to collect.
Instead, we represent each head as a linear combination of template 3-D heads with different attributes. We trained a deep-neural-network model to infer the coefficients of the templates for a given input image and to determine the orientation of the head in the image. Then we quantized the weights of the model, to reduce its size and execution time.
In our experiments, this approach reduced the false-rejection rate (FRR) for visual device directedness detection by almost 80% relative to the PnP approach.
Audio-based device voice activity detection (DVAD)
In addition to visual directedness, Conversation Mode leverages audio cues to determine when speech is directed at the device. To process the audio signal, we use a type of model known as a separable convolutional neural network (CNN). A standard CNN model works by sliding fixed-size filters across the input, looking for telltale patterns wherever they occur. In a separable CNN, the matrices that encode the filters are decomposed into smaller matrices, which are multiplied together to approximate the source matrix, reducing the computational burden.
We conducted experiments to fine-tune the architecture and optimize the filter size and the matrix decomposition to minimize latency.
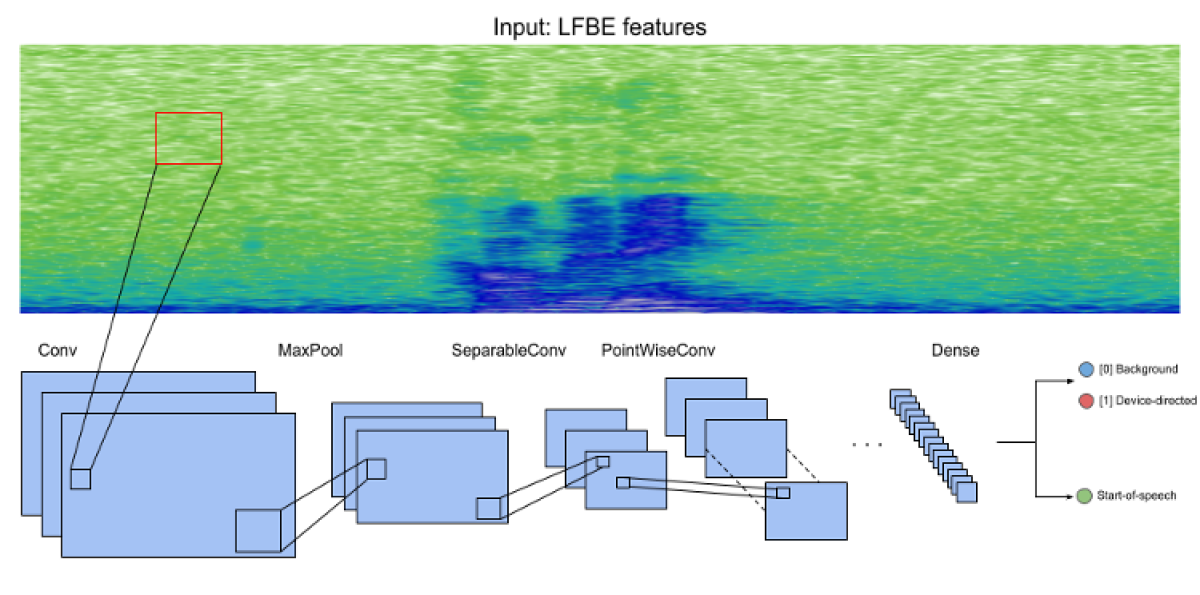
With the initial launch of Conversation Mode, in 2021, the addition of the DVAD model reduced the FRR by 83% relative to a model that used visual data only. The DVAD model is especially effective in reducing false wakes triggered by ambient noise or Alexa’s own responses when the customer is looking at the device but not speaking. Relative to the visual-only model, the addition of DVAD achieved an 80% reduction in false wakes due to ambient noise and a 42% reduction in false wakes triggered by Alexa’s own responses, all without increasing latency.
We are excited to bring Conversation Mode to our customers and look forward to their feedback. We are continuing to work on multiple improvements, such as “anaphoric barge-ins”, which would allow customers to interrupt a list of options with an exclamation like “That one!” We hope to delight our customers with updates to the feature, while breaking new scientific ground to enable them.