
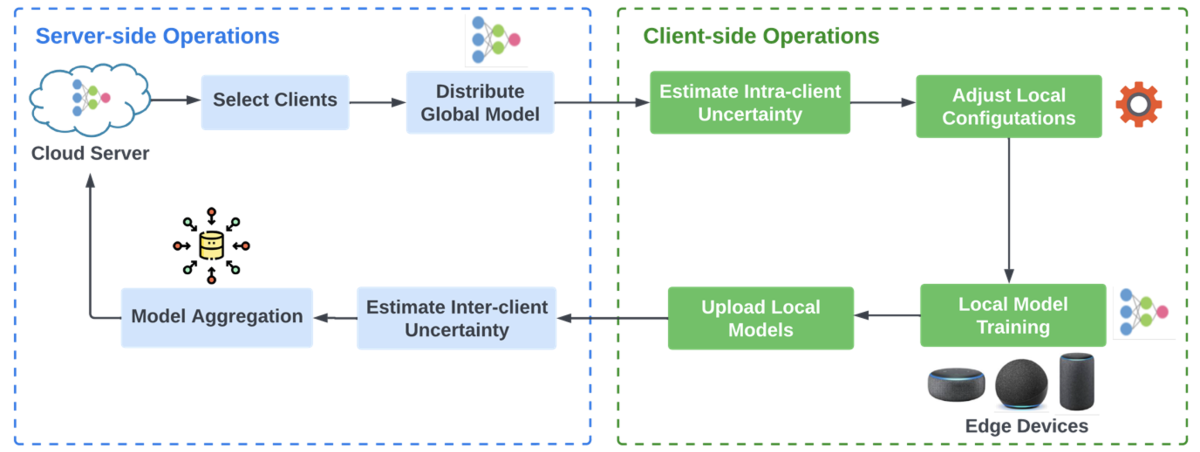
Federated learning (FL) is a framework that allows edge devices (e.g., Alexa devices) to collaboratively train a global model while keeping customers’ data on-device. A standard FL system involves a cloud server and multiple clients (devices). Each device has its local data and a local copy of the machine learning (ML) model being served.
In each round of FL training, a cloud server sends the current global model to the clients; the clients train their local models using on-device data and send the models to the cloud; and the server aggregates the local models and updates the global model. FL also has a personalization branch, which aims to customize local models to improve their performance on local data.
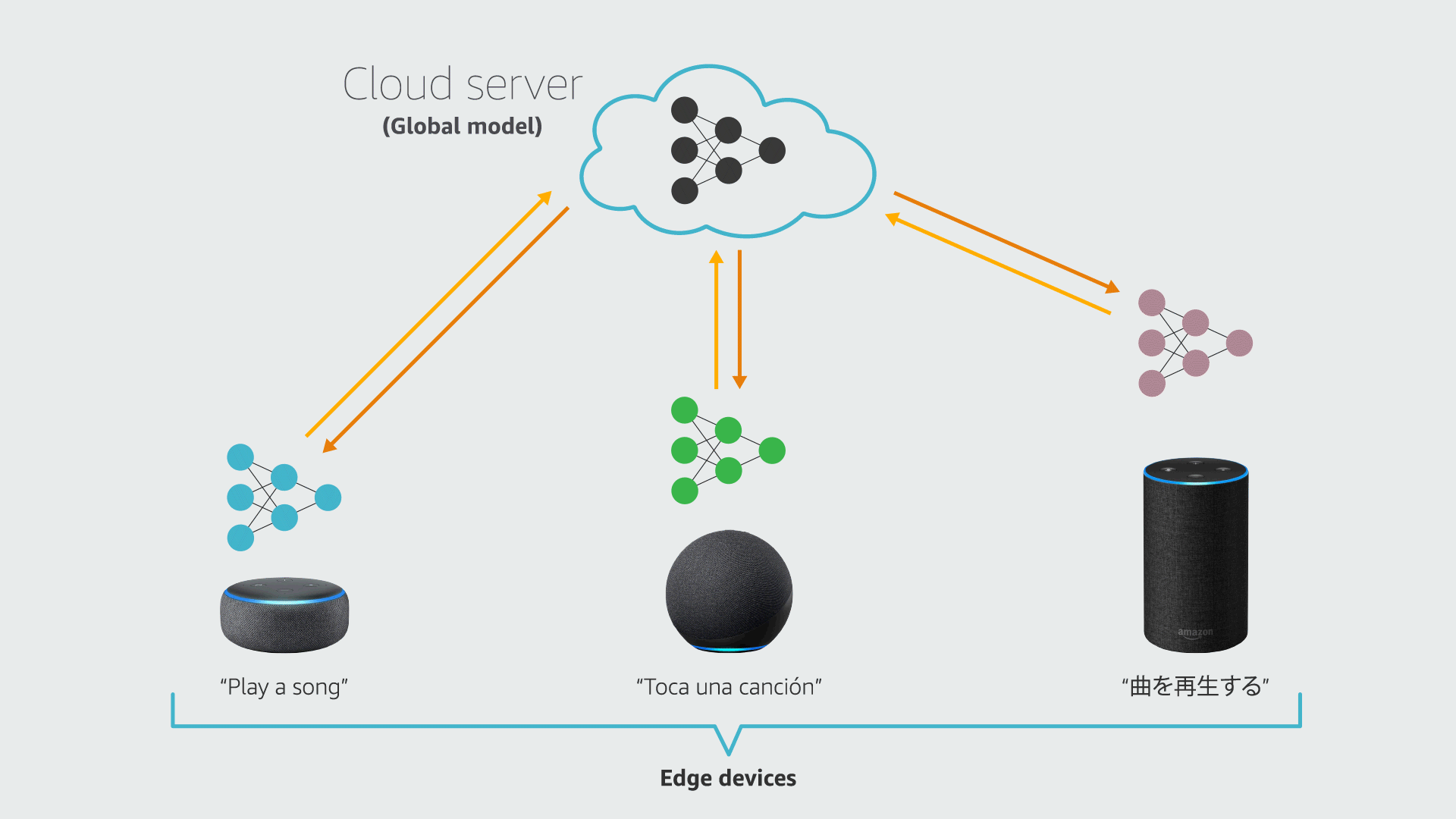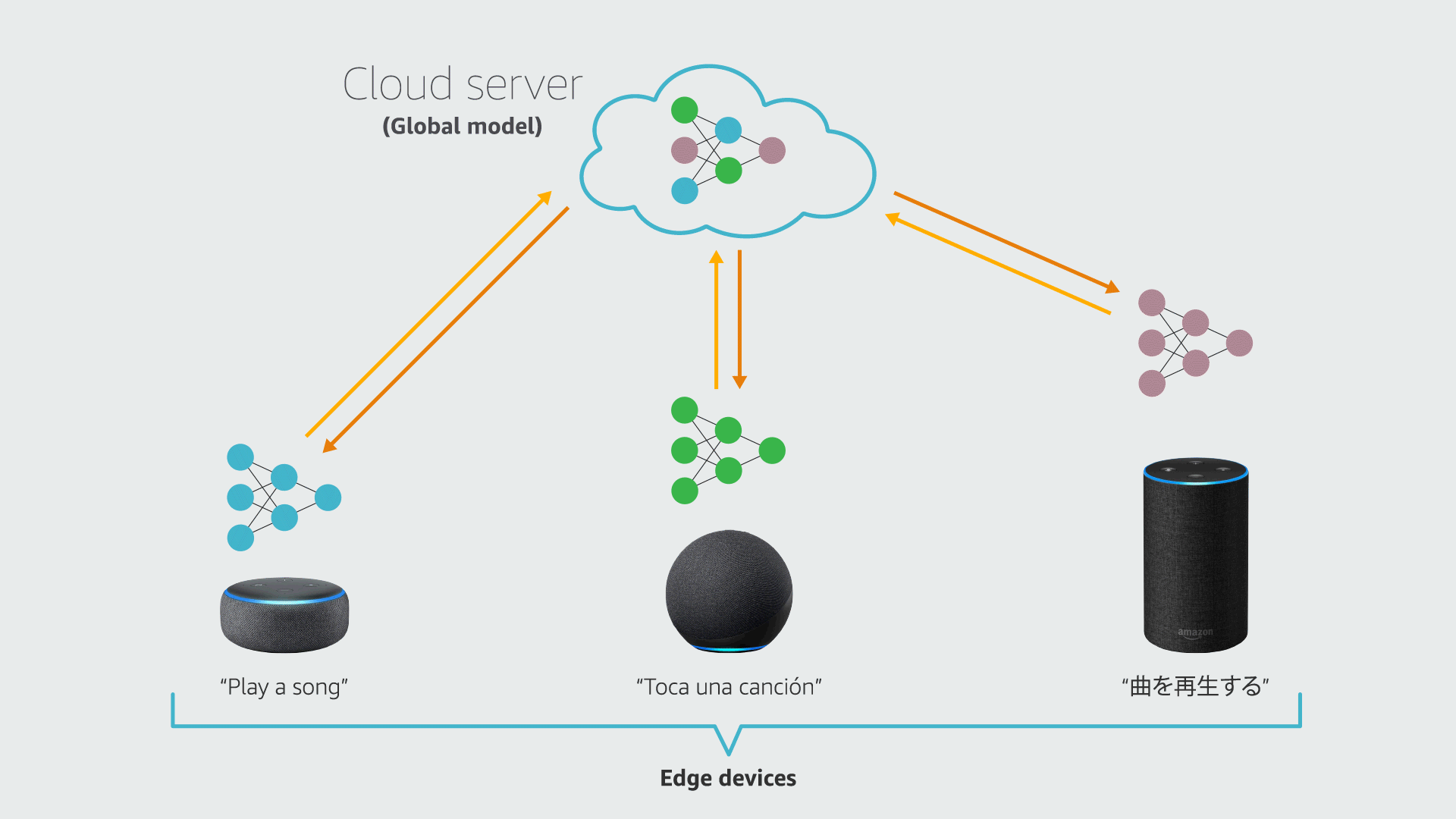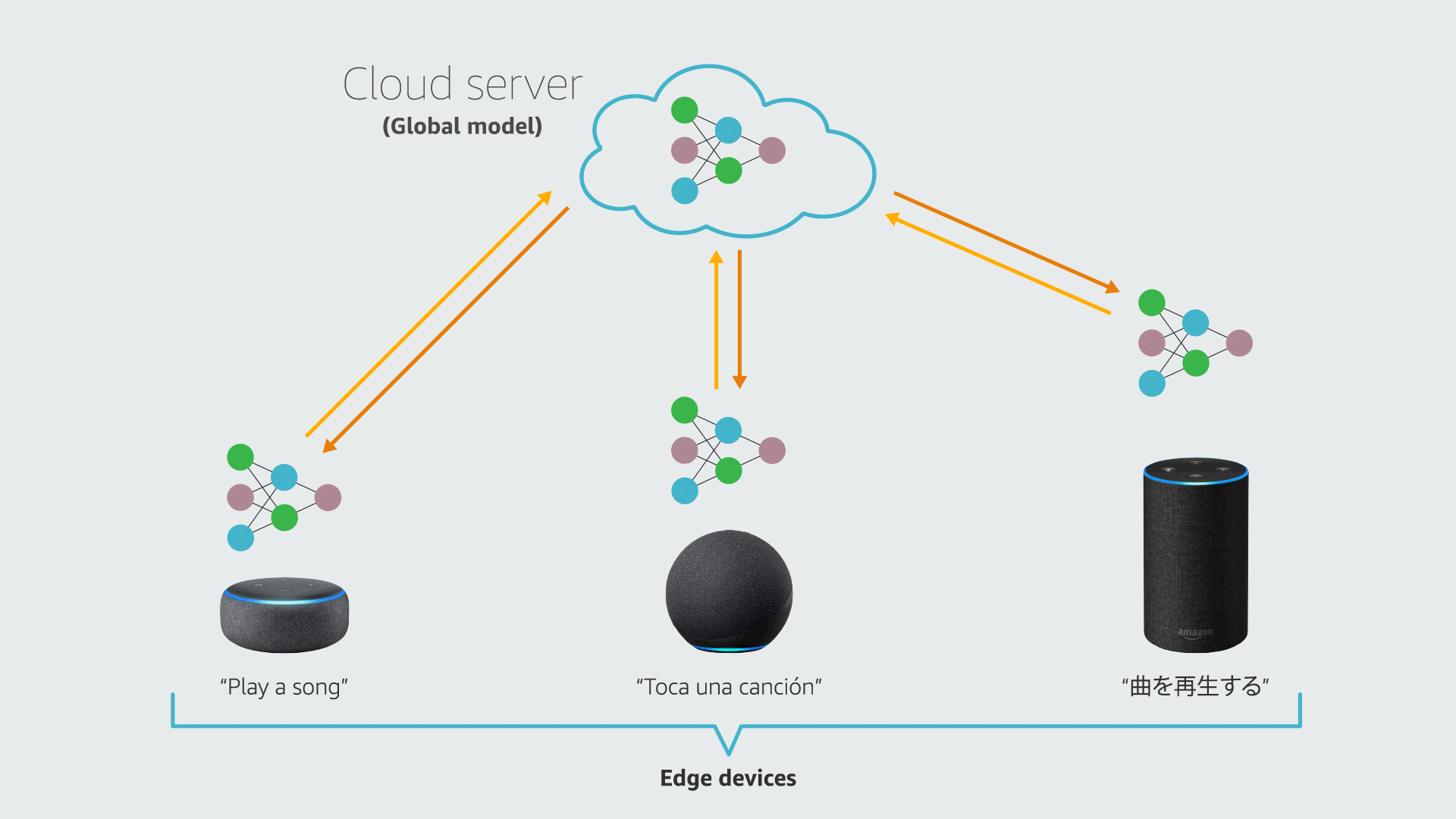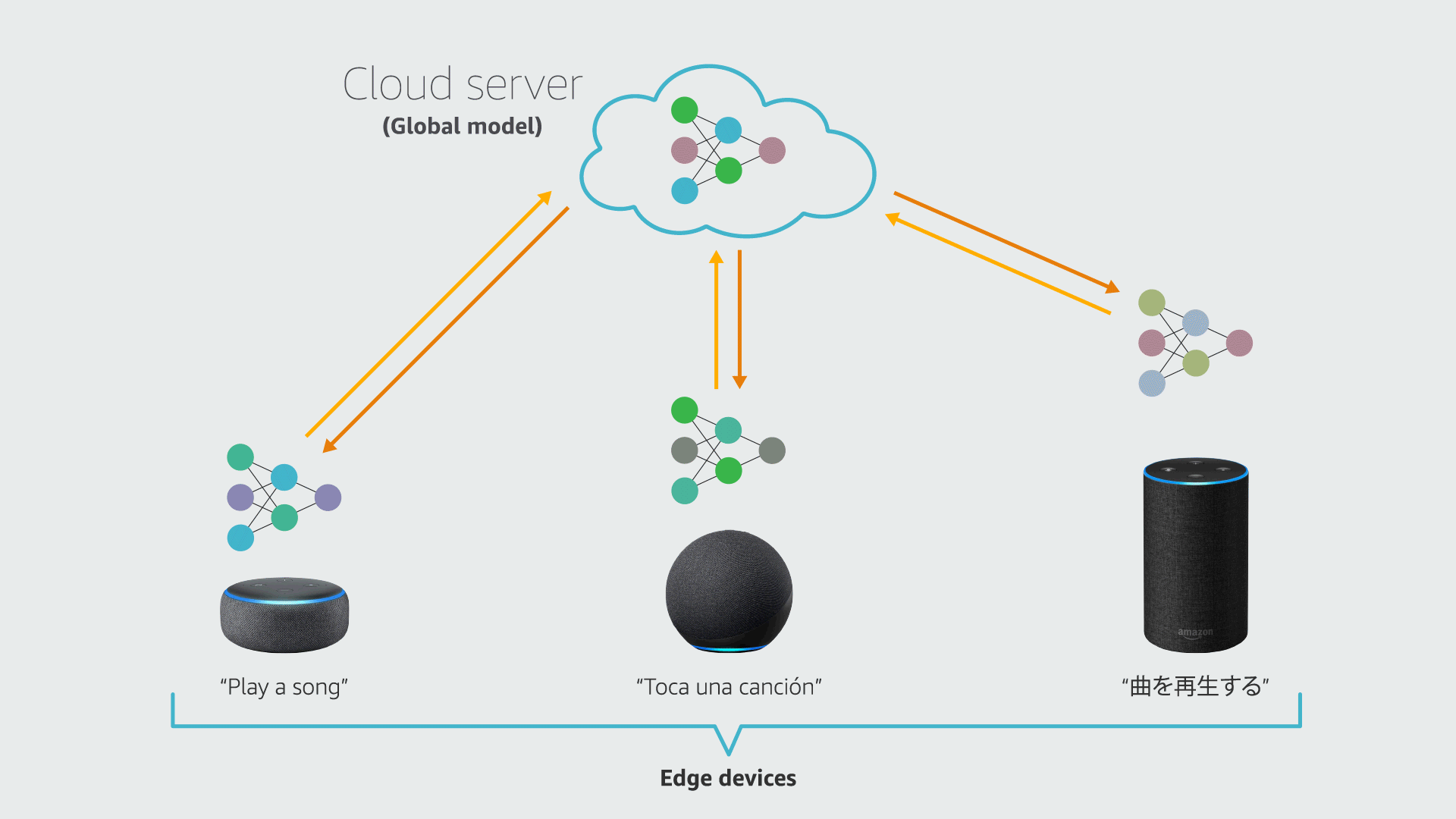
In many real-world applications, the local datasets for different clients may have heterogeneous distributions. In a paper we presented at the 36th Conference on Neural Information Processing Systems (NeurIPS), we show that a training procedure that accounts for that heterogeneity improves the efficiency and accuracy of both the local and global models in federated learning.

In particular, we consider two new measures of heterogeneity within an FL system: (1) intra-client uncertainty, which profiles the differences across time for a local model, and (2) inter-client uncertainty, which characterizes the differences between different users’ local models in the same time frame.
A larger inter-client uncertainty indicates a more heterogeneous local data distribution among the edge devices, which makes personalization more important. A larger intra-client uncertainty means that the local model (particularly, its learnable parameters) has large variations across different rounds of FL training. Accordingly, our method adjusts the local training configuration and the FL aggregation rule based on the two uncertainty values.
To evaluate our approach, we compared it with seven earlier FL algorithms on seven different datasets, spanning image and audio data. We found that our approach consistently delivered the highest accuracy, on both global and local models.
Accounting for uncertainty
Our intuition was that that when training a local model, selecting a proper initial model and an appropriate number of training steps is critical to minimizing the training loss, thus achieving the desired personalization.

Our method, which we call Self-FL, is rooted in a theoretical analysis using Bayesian hierarchical models, in which the intra-client and inter-client uncertainties define different layers of the hierarchy. From the Bayesian analysis, we derive equations relating these two uncertainty measures to three local configuration factors: (1) the local initial model, which is used as the starting point of local model training; (2) the learning rate, which determines how dramatically a single training example can affect network weights; and (3) the early-stop rule, which determines when the training procedure should stop to prevent overfitting.
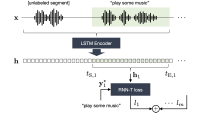
In practice, we don’t have accurate measurements of the intra-client and inter-client uncertainty quantities. But in the paper, we provide several different methods for estimating them. In our experiments, we use an estimate based on the variance in the parameter optimizations determined over the course of training.
To the best of our knowledge, this is the first work to connect personalized FL with hierarchical modeling and to use uncertainty quantification to drive personalization.
Adaptive FL aggregation rule
Existing FL algorithms typically update the global model using a weighted sum of local models, where the weight for each local model is proportional to the local dataset size. Our framework uses an adaptive aggregation rule to update the global model for better personalization. Particularly, we derive the aggregation rule from Bayesian hierarchical modeling, where the global model parameters are considered the ”root” of the statistical model.
The idea is, essentially, that the more a local model’s training data deviates from the global averages, the more responsive the model should be to training on that data. Conversely, the more uncertain the optimization of the local models’ parameters appear to be, the less weight they should be given when updating the global model.
Our method is designed to improve the accuracy of edge devices’ personalized models both directly, by better tailoring them to the types of data they’re likely to see, and indirectly, by making the global models distributed to all clients more accurate. Our empirical results indicate that relative to prior FL schemes, Self-FL improves performance for edge clients. As such, it promises to improve the experience of Amazon customers by making their devices more responsive to their particular needs.



