
Machine learning (ML) models need regular updates to improve performance, but retraining a model poses risks, such as the loss of backward compatibility or behavioral regression, in which a model, while improving on average, backslides on particular tasks. This predicament often hinders the rapid adoption of state-of-the-art ML models in production AI systems.
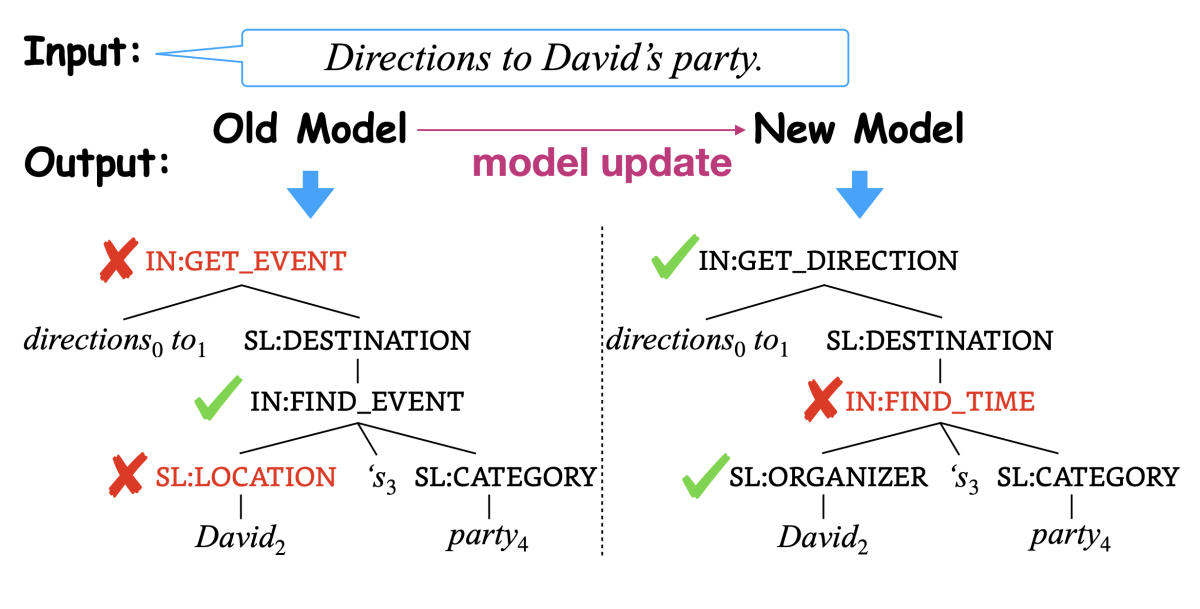

Previous work on preventing model regression has focused on classification tasks. But the resulting techniques have not generalized well to structured-prediction tasks, such as natural-language parsing, which maps an input sentence into a structured representation (either syntax or semantics, typically in graph or tree form). With structured prediction, any differences in local predictions will lead to incompatible global structures. Even when parsers share the same factorization paradigm, differences in parameterization and training procedure can still lead to substantial behavioral incongruence.
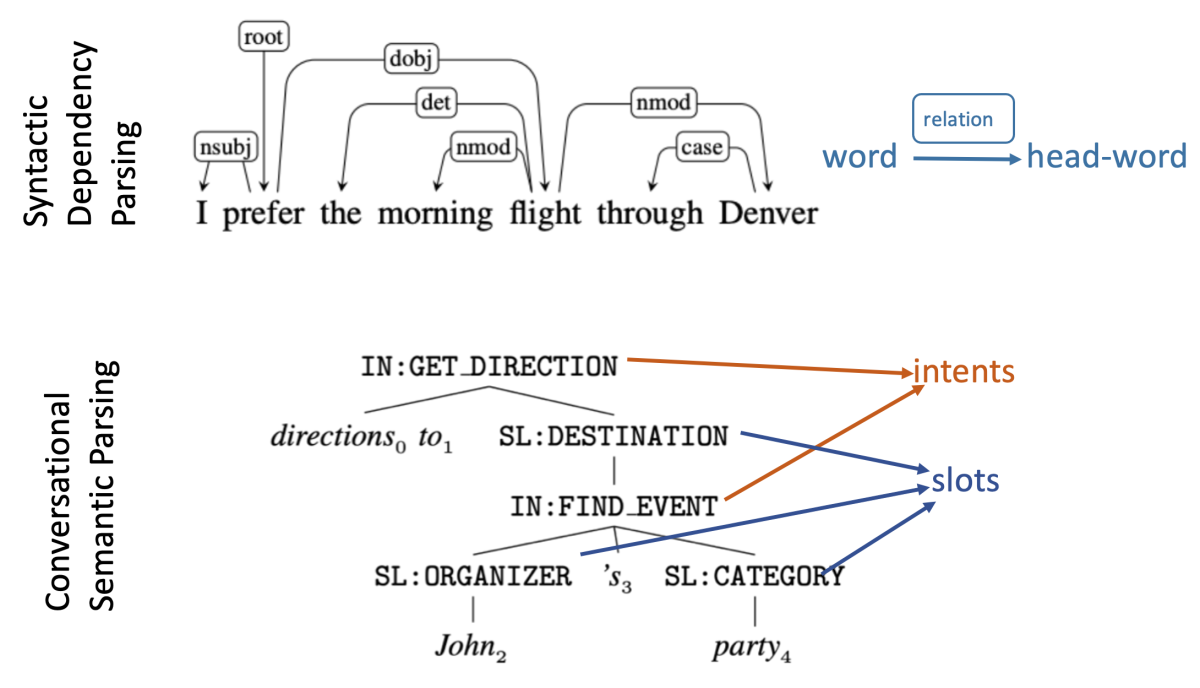
In a paper we’re presenting at this year’s Conference on Neural Information Processing Systems (NeurIPS), we explore a new backward-compatible model-training approach called backward congruent reranking (BCR), which generalizes better to structured prediction. BCR adapts the idea of discriminative reranking, which is a well-known method for improving parsing accuracy. Specifically, we leverage the old model as a discriminative reranker, which scores the n-best hypotheses produced by the new model.
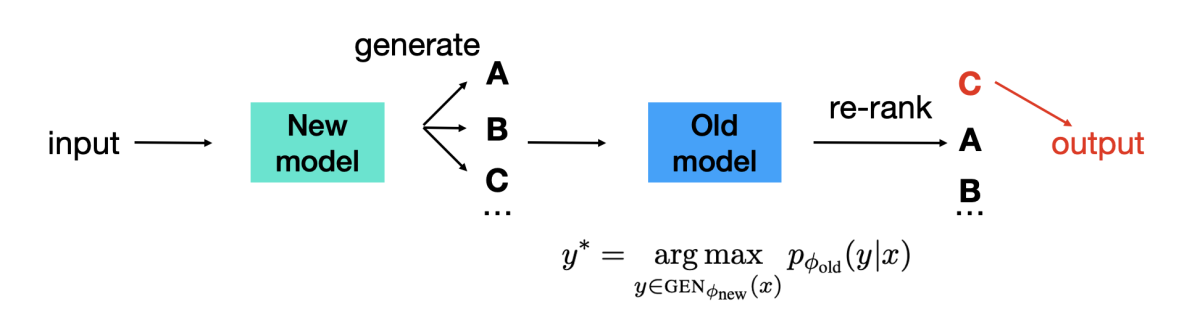
To quantify backward compatibility, we extend the notion of negative flip rate (NFR), or the rate at which the updated model backslides on tasks it previously executed successfully, measuring regression errors on both global and local prediction levels. We further introduce negative flip impact (NFI) as a relative compatibility measure, defined as the ratio of negative flips to total prediction errors.

To evaluate our approach, we compared it to state-of-the-art parsing models on two natural-language parsing tasks, dependency parsing and conversational semantic parsing. We saw a consistent reduction in both NFR and NFI without compromising the new-model accuracy. Previous methods, such as knowledge distillation and model ensembles, achieved an NFI relative reduction of 3% and 28%, respectively. In comparison, BCR is able to reduce NFR and NFI across all model update settings with an average of 58% relative reduction in NFI.

Dropout-p sampling
The output of a parsing model is a graph that represents all possible parses of the input, together with their probabilities. The top-ranked parse is typically the most probable path through the graph.
But there are different ways to decode the n best candidate parses. Interestingly, we found that traditional methods — beam search, top-k, and nuclear/top-p sampling — do not enable BCR to reach its full potential. Methods that simply maximize probability yield candidates that are too homogeneous, while methods that randomly sample paths through the graph yield candidates that are too weak.
We propose a new method for decoding the n-best candidates, which we call dropout-p sampling. In deep learning, dropout is a broadly used regularization technique, in which some neurons from the neural network are randomly dropped during training. This prevents the network from becoming overly reliant on particular inferential pathways, which may prevent it from generalizing well.
Normally, dropout is used only during training. In dropout-p sampling, however, we use it during inference, with a dropout rate of p. Deactivating some nodes during inference increases the heterogeneity of the outputs without sacrificing quality.
Compared to traditional sampling methods, dropout-p sampling has the following advantages: (1) it leaves the default decoding algorithm unchanged; (2) it can be regarded as sampling globally instead of sampling locally at each decoding step, potentially improving the formality of the output structure; (3) its applicability is not limited to sequence generation models.

Inference speed
For dropout-p sampling, the overall computation overhead of the decoding step grows linearly with the number of candidates, but different runs of sampling can be done in parallel. We experimented with two different dependency parsers, deepbiaf and stackptr. With the same inference hardware (one Nvidia V100 GPU) and the same batch size of 32, the decoding and reranking speeds are 171 and 244 sentences per second, respectively, for deepbiaf and 64 and 221 sentences per second for stackptr.

On the semantic-parsing task, we found that reranking was about five times as fast as decoding. In practice, the reranking step can be made even faster, as it generally allows for larger batch sizes.
In summary, we are sharing promising new results in our journey toward smooth and regression-free ML updates, where AI evolves gracefully over time. We believe that such findings are generic and have broad real-world applications at Amazon and beyond.



