
If two people are talking in a noisy environment, and one doesn’t hear the other clearly or doesn’t quite understand what the other person meant, the natural reaction is to ask for clarification. The same is true with voice agents like Alexa. Rather than taking a potentially wrong action based on inaccurate or incomplete understanding, Alexa will ask a follow-up question, such as whether a requested timer should be set for fifteen or fifty minutes.
Typically, the decision to ask such questions is based on the confidence of a machine learning model. If the model predicts multiple competing hypotheses with high confidence, a clarifying question can decide among them.
Our analysis of Alexa data, however, suggests that 77% of the time, the model’s top-ranked prediction is the right one, even if alternative hypotheses also get high confidence scores. In those cases, we'd like to reduce the number of clarifying questions we ask.
Last week, at the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), we presented work in which we attempt to reduce unnecessary follow-up questions by training a machine learning model to determine when clarification is really necessary.
In experiments, we compared our approach to one in which the decision to ask follow-up questions was based on confidence score thresholds and other similar heuristics. We found that our model improved the F1 score of clarification questions by 81%. (The F1 score factors in both false positives — here, questions that didn’t need to be asked — and false negatives — here, questions that should have been asked but weren’t.)
HypRank model
With most voice agents, the acoustic signal of a customer utterance first passes to an automatic-speech-recognition (ASR) model, which generates multiple hypotheses about what the customer said. The top-ranked hypotheses then pass to a natural-language-understanding (NLU) model, which identifies the customer’s intent — the action the customer wants performed, such as PlayVideo — and the utterance slots — the entities on which the intent should act, such as VideoTitle, which might take the value “Harry Potter”.
In the setting we consider in our paper, hypotheses generated by our ASR and NLU models pass to a third model, called HypRank, for hypothesis ranker. HypRank combines the predictions and confidence scores of ASR, intent classification, and slot-filling with contextual signals, such as which skills a given customer has enabled, to produce an overall ranking of the different hypotheses.
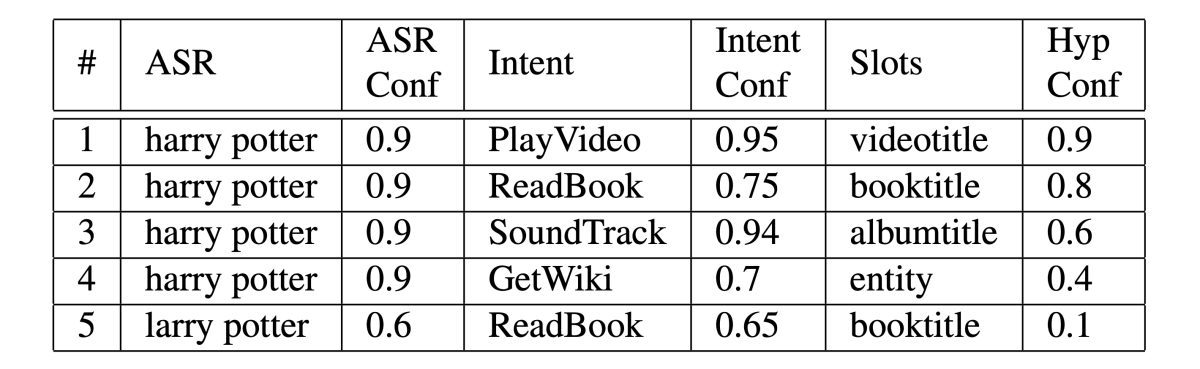
With this approach, there are three possible sources of ambiguity: similarity of ASR score, similarity of intent classification score, and similarity of overall HypRank score. In a traditional scheme, a small enough difference in any of these scores would automatically trigger a clarification question.
To clarify or not to clarify
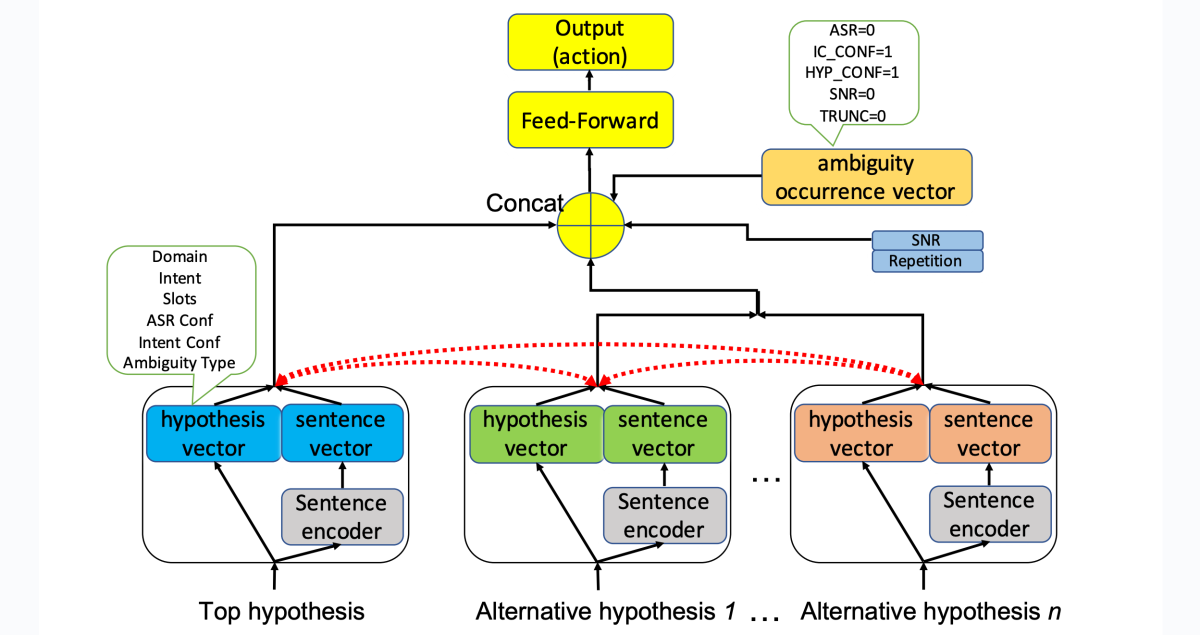
Instead, in our method, we train yet another machine learning model to decide whether a clarification question is in order. In addition to similarity of ASR, NLU, or HypRank score, the model considers two other sources of ambiguity: signal-to-noise ratio (SNR) and truncated utterances. A truncated utterance is one that ends with an article (“an”, “the”, etc.), one of several possessives (such as “my”), or a preposition. For instance, “Alexa, play ‘Hello’ by” is a truncated utterance.
As input, the model receives the top-ranked HypRank hypothesis; any other hypotheses with similar enough scores on any of the three measures; the SNR; a binary value indicating whether the request is a repetition (an indication that it wasn’t satisfactorily fulfilled the first time); and binary values indicating which of the five sources of ambiguity pertain.
The number of input hypotheses can vary, depending on how many types of ambiguity pertain. So the vector representations of all hypotheses other than the top-ranked hypothesis are combined to form a summary vector, which is then concatenated with vector representations of the other inputs. The concatenated vector passes to a classifier, which decides whether to issue a clarification question.
Experiments
To our knowledge, there are no existing datasets that feature multiple ASR and NLU hypotheses labeled according to accuracy. So to train our model, we used data that had been automatically annotated by a model that my Amazon colleagues presented last year at the NeurIPS Workshop on Human-in-the-Loop Dialogue Systems.
Their model was trained on a combination of hand-annotated data and data labeled according to feedback from customers who were specifically asked, after Alexa interactions, whether they were satisfied with their results. We used the model to label additional utterances, with no human involvement.
Since all the samples in the dataset featured at least one type of ambiguity, our baseline was asking clarification questions in every case. That approach has a false-negative rate of zero — it never fails to ask a clarification question when necessary — but it could have a high false-positive rate. Our approach may increase the false-negative rate, but the increase in F1 score means that it strikes a much better balance between false negatives and false positives.



