
Graphs are a useful way to represent data, since they capture connections between data items, and graph neural networks (GNNs) are an increasingly popular way to work on graphs. Common industry applications of GNNs include recommendation, search, and fraud detection.
The graphs used in industry applications are usually massive, with billions of nodes and hundreds of billions or even trillions of edges. Training GNNs on graphs of this scale requires massive memory storage and computational power, with correspondingly long training times and large energy footprints.
In a paper we’re presenting at this year’s KDD, my colleagues and I describe a new approach to distributed training of GNNs that uses both CPUs and GPUs, optimizing the allocation of tasks to different processor types to minimize training times.
In tests, our approach — DistDGLv2 — offered an 18-fold speedup over Euler, another distributed GNN training framework, on the same hardware. DistDGLv2 also achieves a speedup of up to 15-fold over distributed CPU training in a cluster of the same size.
Graph neural networks
In the GNN setting, graph nodes typically represent objects, and the graph edges represent relationships between objects. Both nodes and edges may have associated features — data such as object properties or types of relationships between objects.

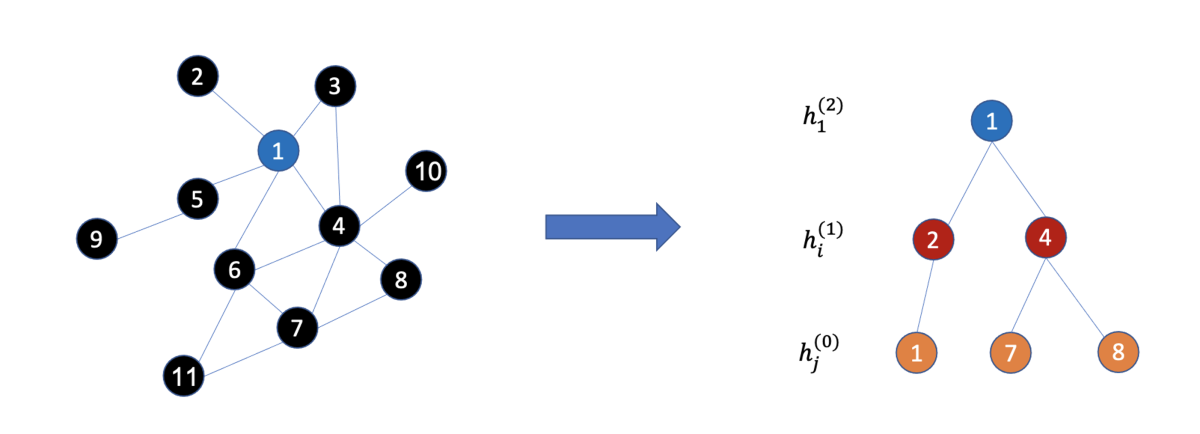
For each node in a graph, a GNN produces a vector representation (an embedding) that encodes information about the node and its neighborhood — often its one- or two-hop neighborhood, but sometimes larger regions. With the large graphs common in industrial applications, it can be time consuming to factor in all of a node’s one-hop neighbors, let alone its more distant neighbors. So when producing node embeddings, GNNs will often use minibatches of nodes sampled from the target node’s neighborhood.
There are many research works on minibatch sampling — for example, our global-neighbor-sampling technique, presented at KDD 2021. In our new paper, we implement a popular minibatch-sampling algorithm proposed by GraphSage, shown in the figure below. It first samples the target nodes (such as the blue node) and then samples their neighbor nodes (such as the red nodes and orange nodes). DistDGLv2, however, has the flexibility to implement other sampling algorithms.
DistDGLv2
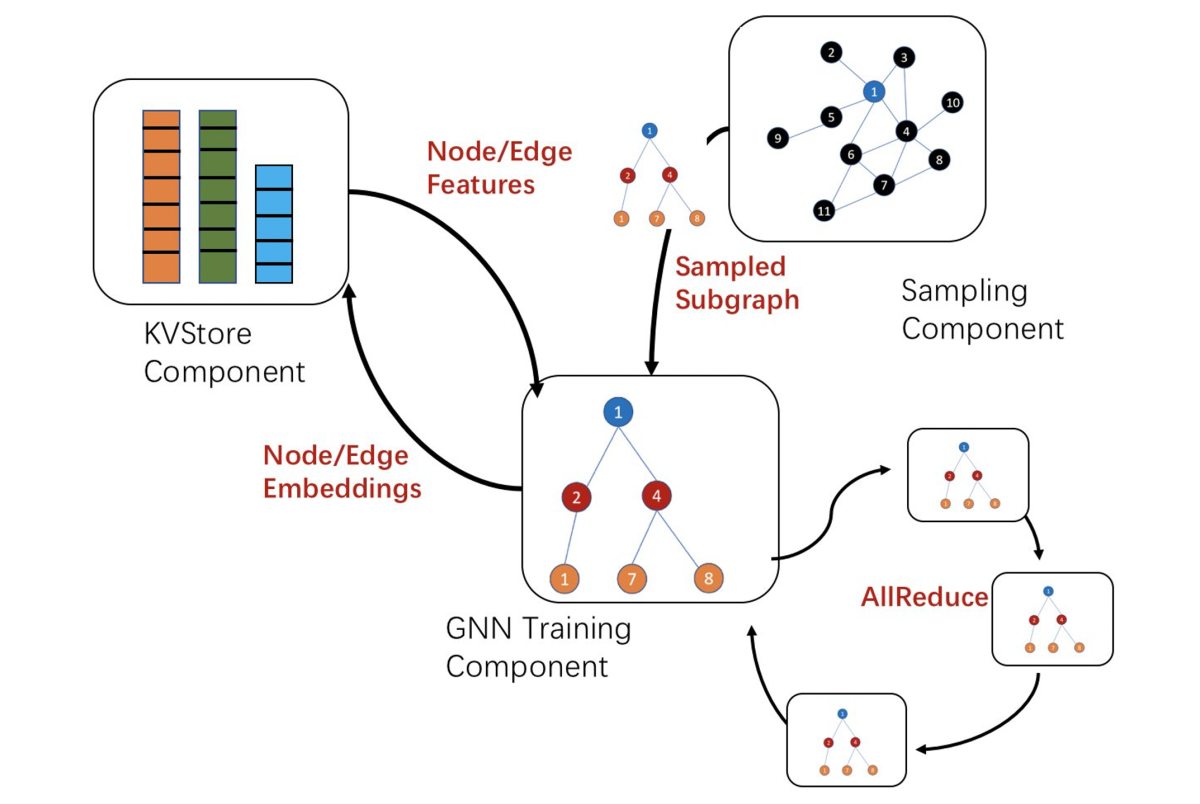
DistDGLv2 has three main components:
- a distributed key-value database (KVStore) to store node/edge features and learnable embeddings;
- a distributed graph store to keep the partitioned graphs for minibatch sampling; and
- a set of trainers to run forward and backward computation on minibatches to estimate the gradients of the model parameters.
To optimize the use of computational resources and scale to very large graphs, we divide these components between CPUs and GPUs. The distributed KVStore and graph store use CPU memory, and CPUs generate the minibatches. The trainers read the minibatch data into GPUs for minibatch computations.
The key to accelerating minibatch training in DistDGLv2 is efficiently moving minibatches from CPU to GPU. To do this, DistDGLv2 deploys three strategies:

- First, it uses the METIS graph-partitioning program (codeveloped by Amazon senior principal scientist George Karypis) to generate graph partitions with minimal edge cuts, and it collocates data with computation to reduce network communication;
- It builds an asynchronous minibatch training pipeline to overlap computation and data movement in all hardware;
- It moves as many computations to GPU as possible to take advantage of GPUs’ computational power.
To collocate data with computation, DistDGLv2 runs KVStore servers, distributed graph store servers, and trainers on the same set of machines. When a graph partition is loaded, its node and edge features go to the KVStore, and the graph structure goes to the graph store server. Each trainer is assigned a training set, where most training nodes and edges belong to the graph partition assigned to the same machine. In this way, most of the data associated with a minibatch will come from the local machine during the minibatch training.

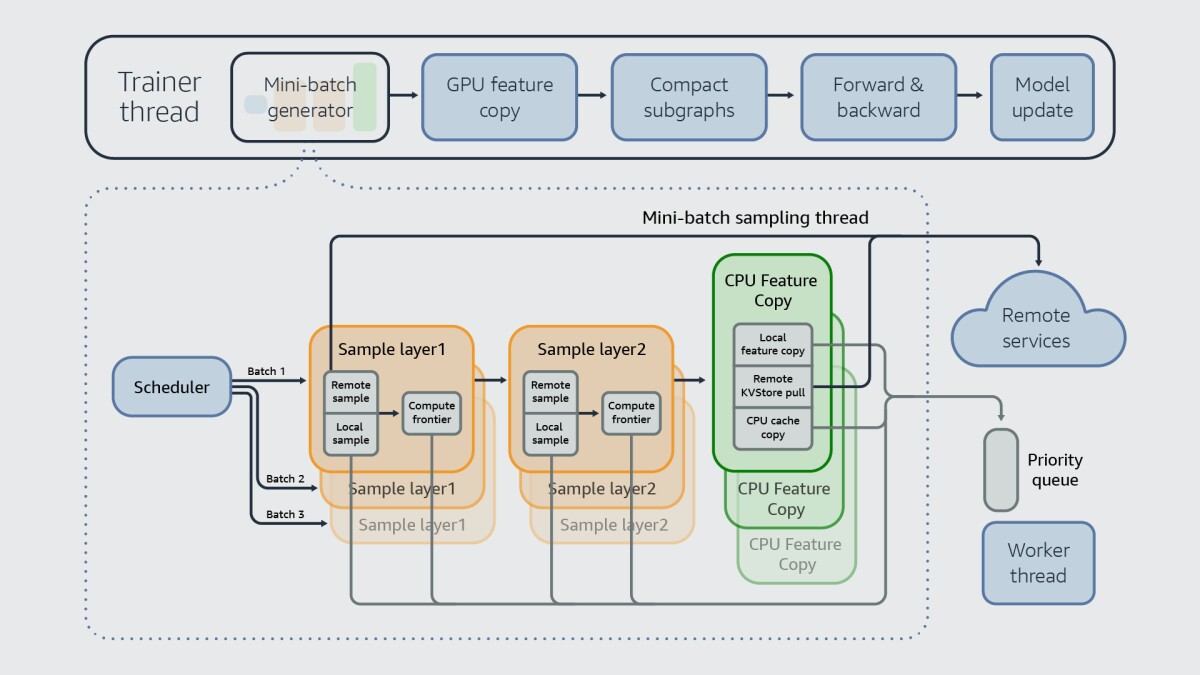
DistDGLv2 implements the second and the third strategies by splitting the minibatch pipeline into seven stages, five of which help prepare a minibatch. We keep as many stages as possible on GPU to take advantage of GPUs’ computational power, while placing the minibatch sampling stages in CPU in another thread. This allows us to overlap minibatch computation in GPU and minibatch sampling in CPU.
As illustrated in the figure below, we run the last four stages in GPU; some of those stages are still involved in minibatch preparation.
In addition to this, we further overlap network communication and CPU computation. We have the sampling pipeline “look ahead” and sample multiple minibatches simultaneously. Thus, when a minibatch is being generated, while a given CPU is waiting for remote neighbor sampling (from another machine) or feature copy (to a GPU), it can move to another minibatch to sample neighbors or copying data locally. In this way, we can effectively hide network communication latency.
With these optimizations, DistDGLv2 can effectively perform distributed GNN training in a cluster of CPUs and GPUs. We demonstrate the efficiency of DistDGLv2 on a cluster of g4dn.metal instances with various GNN workloads. DistDGLv2’s performance relative to CPU-only methods indicates that GPUs can be more effective for distributed GNN minibatch training on massive graphs than CPUs.
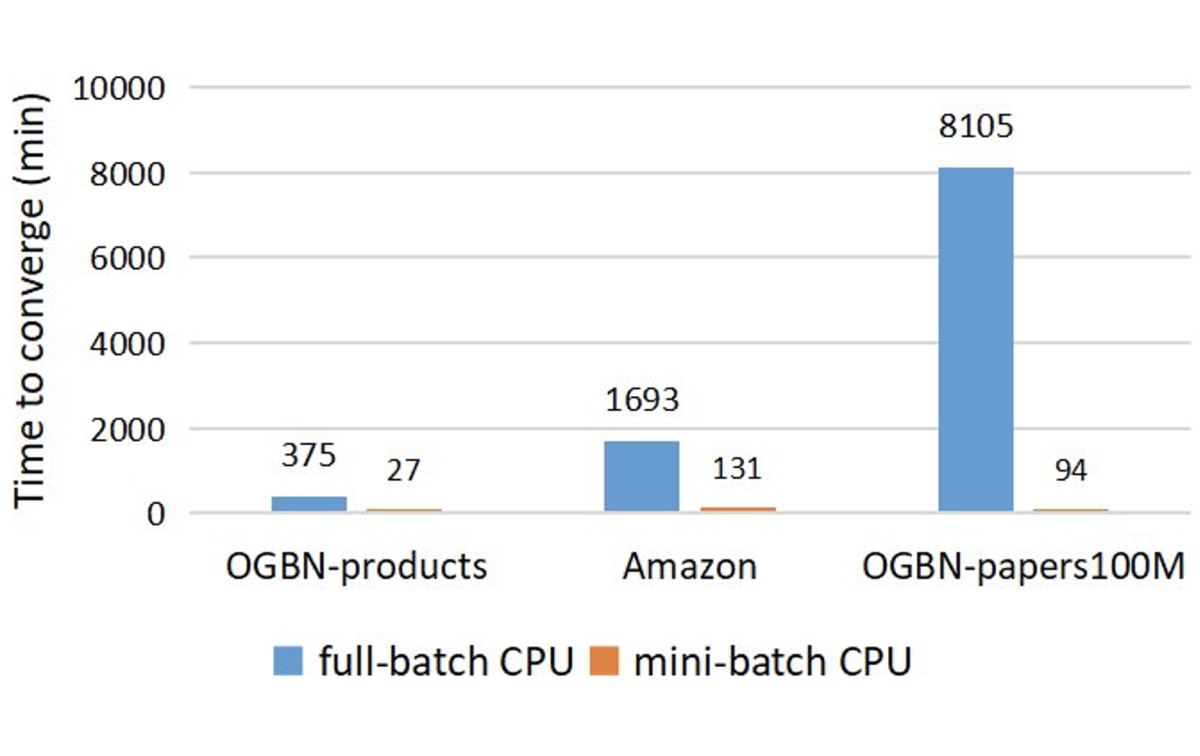
Researchers have also proposed using full graph training for GNN models. This method runs forward and backward computation on the entire graph. We did a comparison between minibatch training and full-graph training on the same graph datasets with the same hardware. We show that minibatch training is much more efficient to train GNN models, and the speed gap gets larger the larger the graphs grow.
On a graph built from the OGBN-papers100M dataset, which has 100 million nodes, minibatch training is about 100 times as fast. After six day’s training, full-graph training still cannot reach the same accuracy as minibatch training, while minibatch training takes 1.5 hours to reach the state-of-the-art performance on the same CPU.



