In an Amazon Science blog post earlier this summer, we presented MiCS, a method that significantly improves the training efficiency of machine learning models with up to 175 billion parameters. But there is a continuing push to scale natural-language-processing models to a trillion parameters, to enable reliable few-shot learning for new tasks.
In this post, we introduce two new augmentations to MiCS, to allow AWS customers to train and fine-tune models at the trillion-parameter scale: (1) contiguous parameter management and (2) prefetched activation offloading.
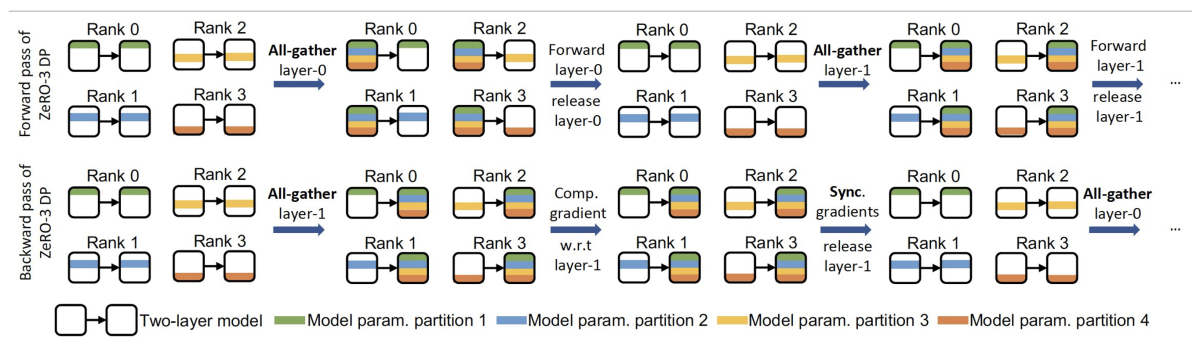
The figure above illustrates the process of parameter gathering during forward and backward passes for a two-layer deep-learning neural-network model. Before we start the forward step, each worker (rank) holds only a part of the model parameters. In order to compute the activations for the first layer, we use the all-gather operation to gather its parameters.

Once we obtain the output of the first layer, we immediately partition its parameters to release memory and proceed to the next neural-network layer. These two steps are repeated in a reverse order when we compute the gradient.
Repeated all-gather and partitioning processes result in heavy use of collective communication, which causes severe memory fragmentation and cache flush in Pytorch. To address this issue, we pre-allocate a contiguous parameter buffer to hold the complete parameter tensors after the gathering and to self-manage the tensor liveness and defragmentation without affecting the behavior of the Pytorch memory allocator. We observed that this approach greatly improved the performance of the memory-bounded tasks.
In addition, we have developed prefetched activation offloading to further save GPU memory, which we enable in conjunction with activation checkpointing. Each checkpointed activation is offloaded to CPU memory and prefetched when needed during backpropagation, using a dedicated stream opened using the CUDA parallel-computing platform. Since the data transfer is asynchronous, we observed only about a 1-2% speed loss using prefetched activation offloading.
AWS recently announced a preview of Amazon EC2 P4de GPU instances powered by 400 Gbps networking and 80GB GPU memory. P4de provides twice as much GPU memory as P4d, enabling fewer nodes to hold a large model in GPU memory and thus lowering communication overhead. The new hardware enables us to even more efficiently scale to larger models with MiCS.
Our experimental results show that we achieve a best ever 176 teraflops per GPU (56.4% of the theoretical peak) for training a 210-layer 1.06-trillion-parameter model on 64 P4de instances in the public cloud. In this setting, the model has a hidden size of 20,480 and a vocabulary size of 50,264. We use a sequence length of 1,024, a batch size of eight per GPU, bfloat16 precision for forward and backward passes, and a float32 Adam optimizer.
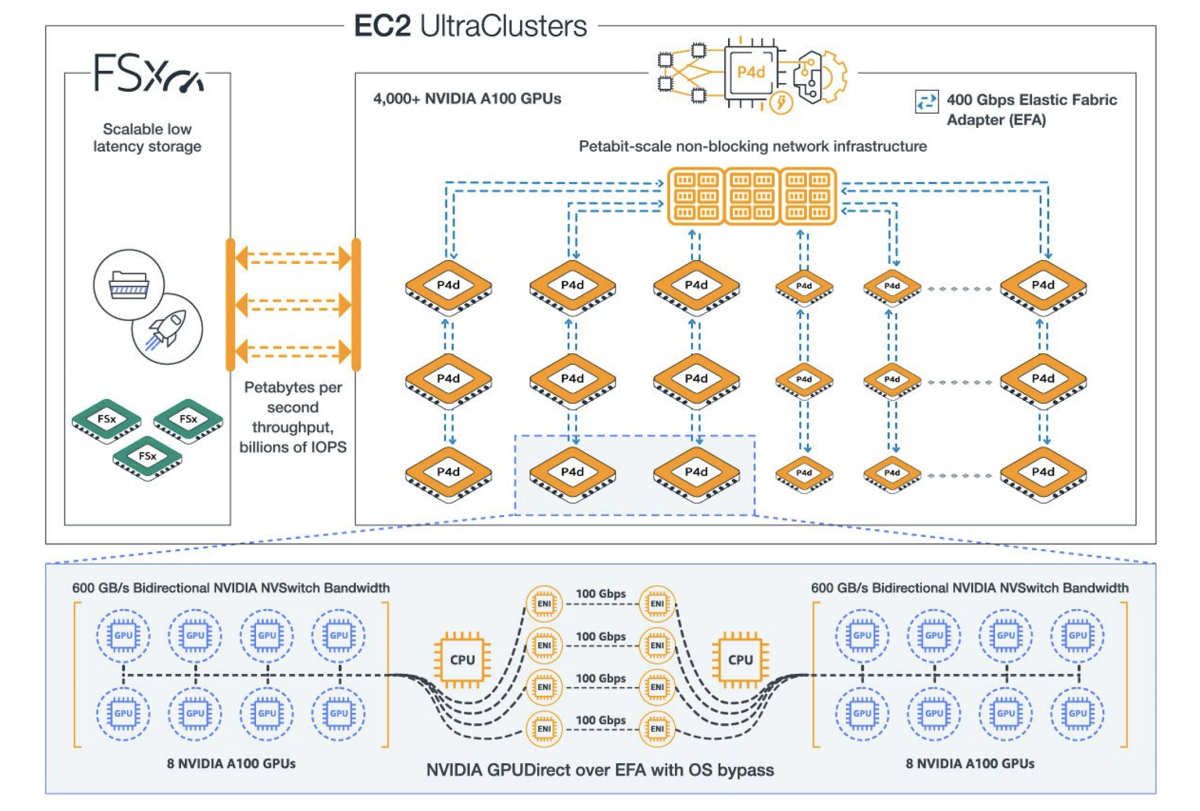
A preview of MiCS is now available in AWS Pytorch DLC and in SageMaker as sharded data parallelism. By leveraging the new techniques, AWS customers can break the GPU memory barrier and empower trillion-parameter model training with one-fourth as much networking bandwidth as an on-premise DGX-A100 cluster.
Acknowledgements: Yida Wang, RJ