
Autonomous vehicles (AVs) such as the Zoox purpose-built robotaxi represent a new era in human mobility, but the deployment of AVs comes with many challenges. It’s essential to do extensive safety testing using simulation, which requires the creation of synthetic driving scenarios at scale. Particularly important is generating realistic safety-critical road scenarios, to test how AVs will react to a wide range of driving situations, including those that are relatively rare and potentially dangerous.

Traditional methods tend to produce scenarios of limited complexity and struggle to replicate many real-world situations. More recently, machine learning (ML) models have used deep learning to produce complex traffic scenarios based on specified map regions, but they offer limited means of shaping the resulting scenarios in terms of vehicle positionings, speeds, and trajectories. This makes it difficult to create specific safety-critical scenarios at scale. Designing huge numbers of such scenarios by hand, meanwhile, is impractical.
In a paper we presented at the 2023 Conference on Neural Information Processing Systems (NeurIPS), we address these challenges with a method we call Scenario Diffusion. Our system comprises a novel ML architecture based on latent diffusion, an ML technique used in image generation in which a model learns to convert random noise into detailed images.
Scenario Diffusion is able to output highly controllable and realistic traffic scenarios, at scale. It is controllable because the outputs of the Scenario Diffusion model are based not only on the map of the desired area but also on sets of easily produced descriptors that can specify the positioning and characteristics of some or all of the vehicles in a scene. These descriptors, which we call agent tokens, take the form of feature vectors. We can similarly specify global scene tokens, which indicate how busy the roads in a given scenario should be.
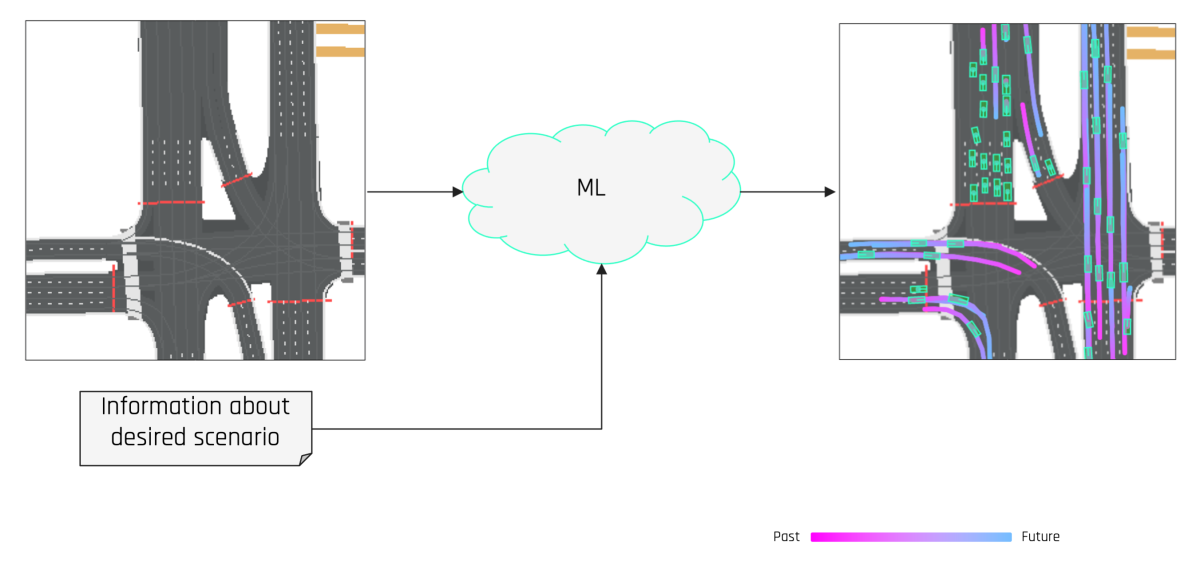
Combining a diffusion architecture with these token-based controls allows us to produce safety-critical driving scenarios at will, boosting our ability to validate the safety of our purpose-built robotaxi. We are excited to apply generative AI where it can have a big impact on the established practical challenge of AV safety.
Inside the Scenario Diffusion model
AV control software is typically divided into perception, prediction, and motion-planning modules. On the road, an AV’s cameras and other sensors perceive the road situation, which can be represented, for motion-planning purposes, as a simplified bird’s-eye-view image.

Each of the vehicles (“agents”) in this multi-channelled image, including the AV itself, is represented as a “bounding box” that reflects the vehicle’s width, length, and position on the local map. The image also contains information on other characteristics of the vehicles, such as heading and trajectory. These characteristics and the map itself are the two key elements of a synthetic driving scenario that are required to validate motion planning in simulation.
The Scenario Diffusion model has two components. The first is an autoencoder, which projects complex driving scenarios into a more manageable representational space. The second component, the diffusion model, operates in this space.
Like all diffusion models, ours is trained by adding noise to real-world scenarios and asking the model to remove this noise. Once the model is trained, we can sample random noise and use the model to gradually convert this noise into a realistic driving scenario. For a detailed exploration of our training and inference processes and model architecture, dive into our paper.
We trained the model on both public and proprietary real-world datasets of driving logs containing millions of driving scenarios across a variety of geographical regions and settings.
Prior ML methods for generating driving scenarios typically place the bounding boxes of agents on a map — essentially a static snapshot, with no motion information. They then use object recognition to identify those boxes before applying heuristics or learned methods to decide on suitable trajectories for each agent. Such hybrid solutions can struggle to capture the nuances of real-world driving.

A key contribution of our work is that it achieves the simultaneous inference of agent placement and behavior. When our trained model generates a traffic scenario for a given map, every agent it positions in the scene has an associated feature vector that describes its characteristics, such as the dimensions, orientation, and trajectory of the vehicle. The driving scenario emerges fully formed.
Our feature vector approach not only provides more-realistic scenarios but also makes it very easy to add information to the model, making it highly adaptable. In the paper, we deal only with standard vehicles, but it would be straightforward to generate more-complex scenarios that include bikes, pedestrians, scooters, animals — anything previously encountered by a Zoox robotaxi in the real world.
Creating safety-critical “edge cases” on demand
If we simply want to create many thousands of realistic driving scenarios, with no particular situation in mind, we let Scenario Diffusion freely generate traffic on a particular map. This type of approach has been explored in prior research. But randomly generated scenarios are not an efficient way to validate how AV software deals with rare, safety-critical events.
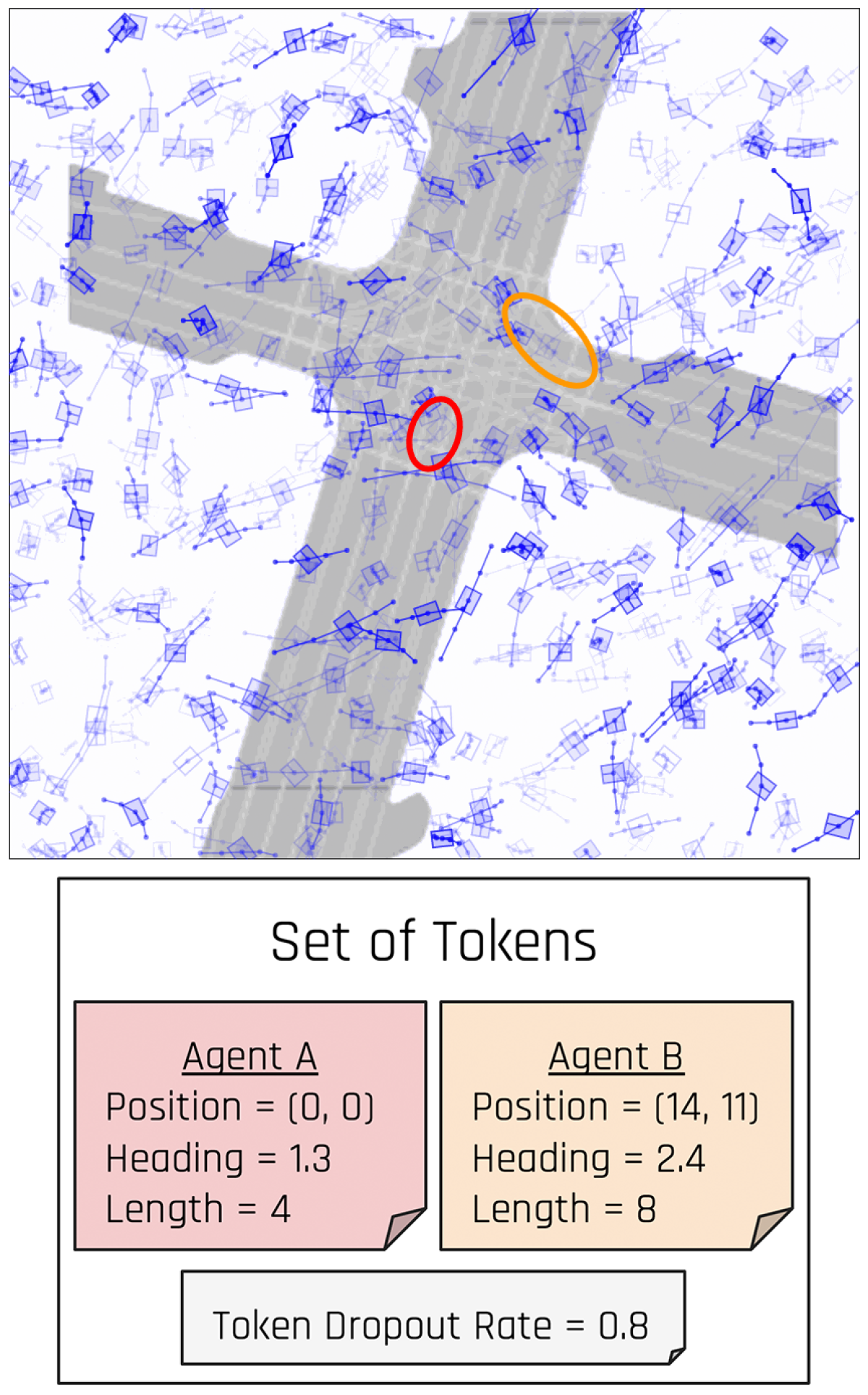
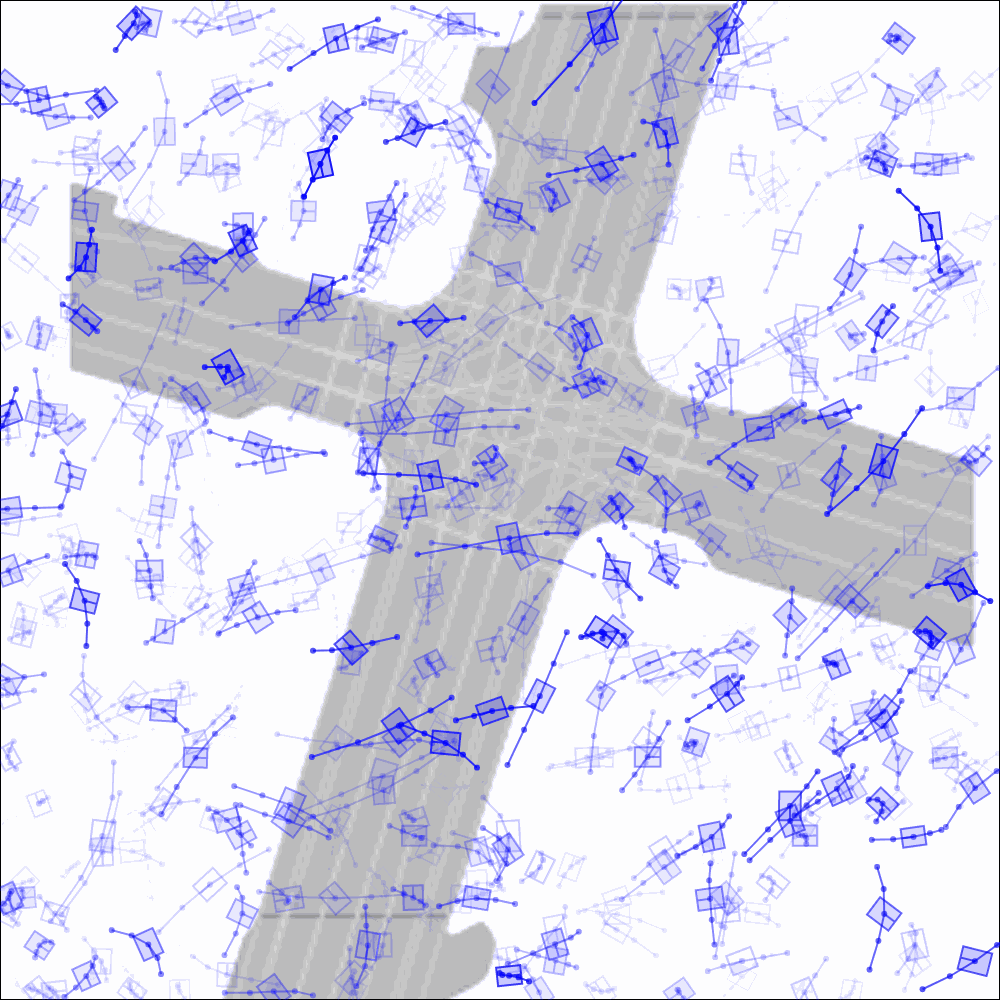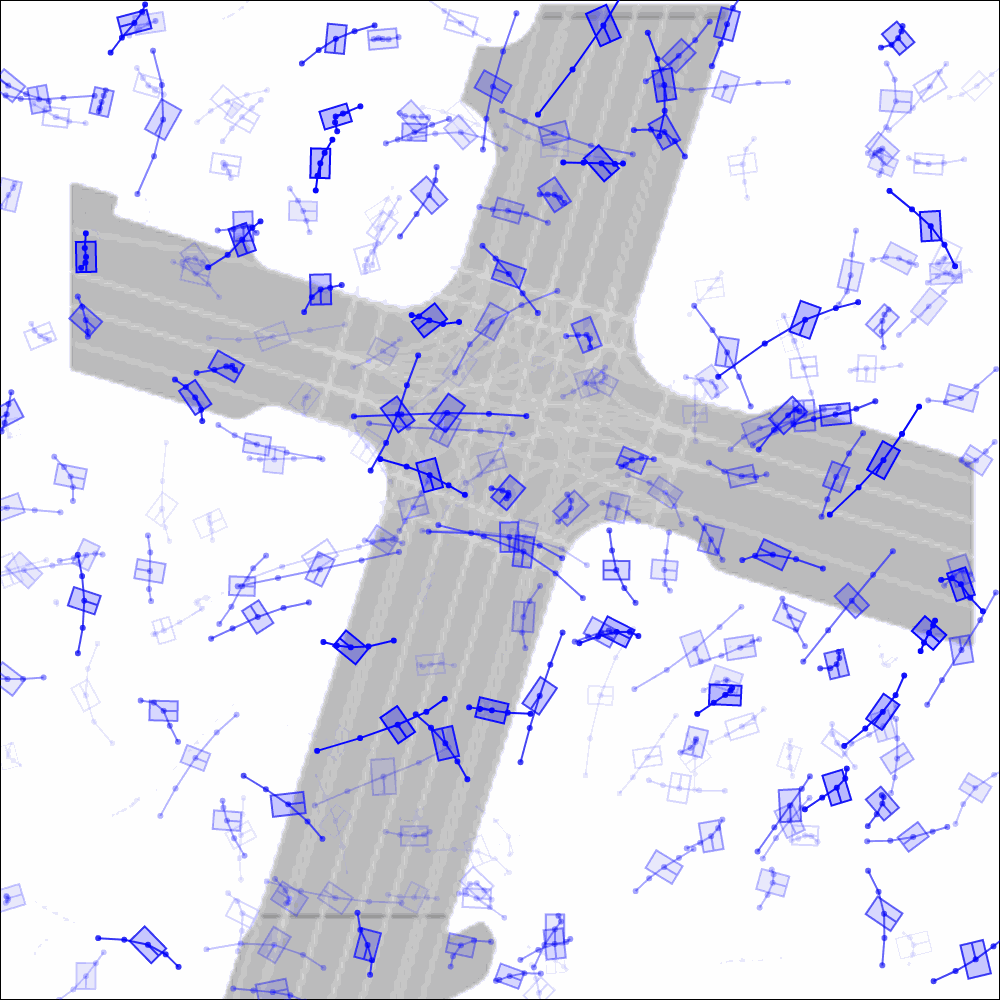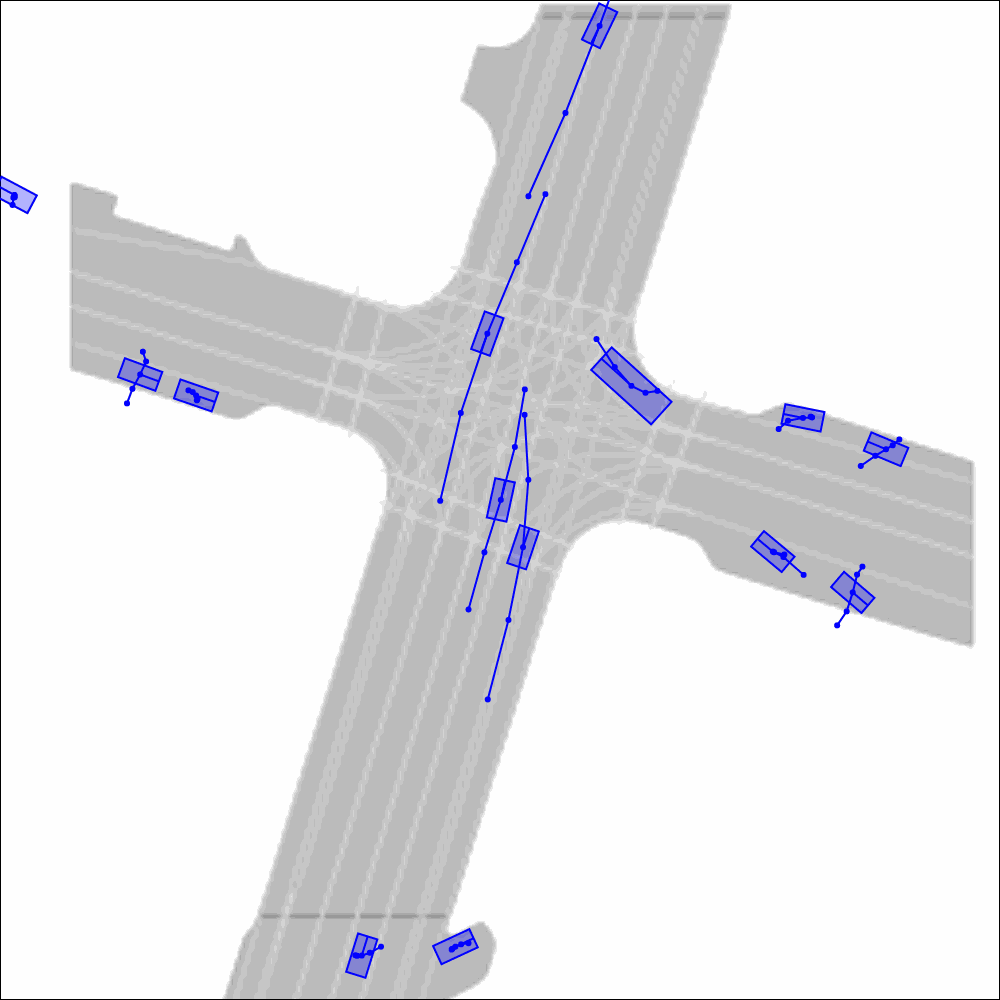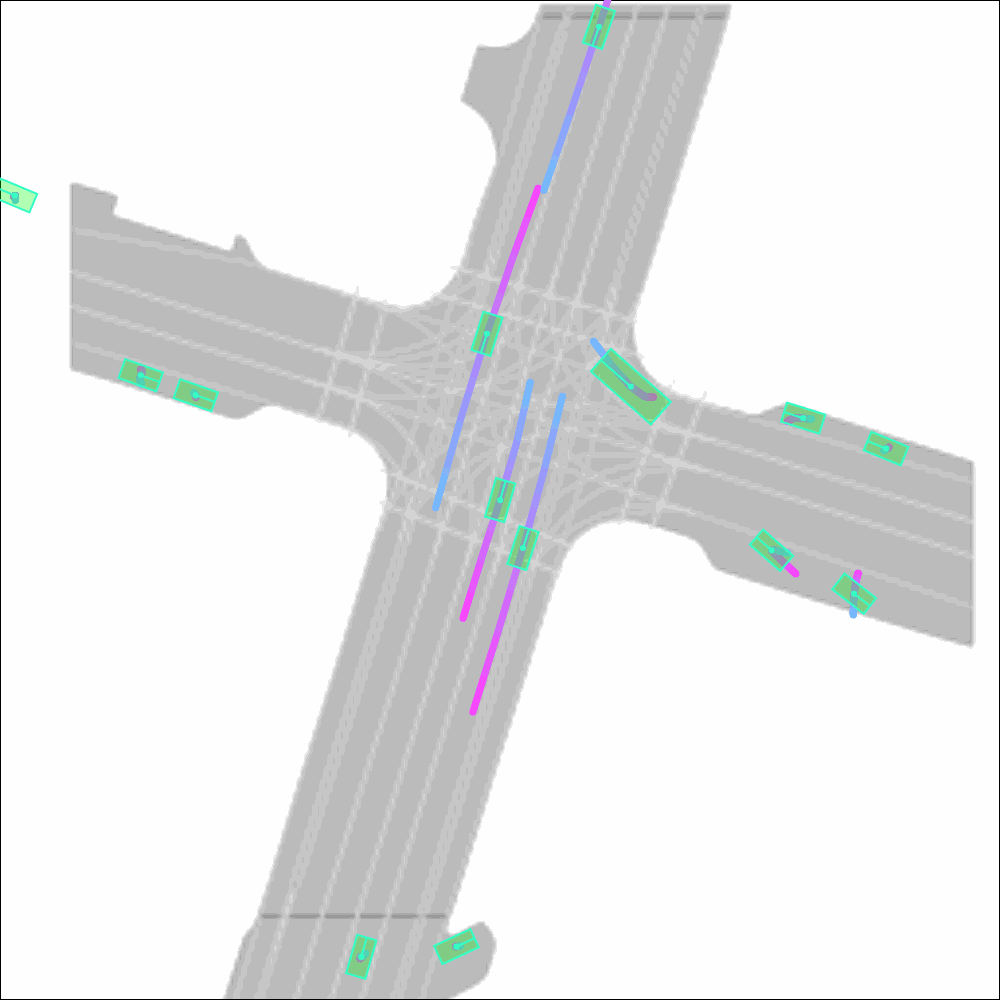
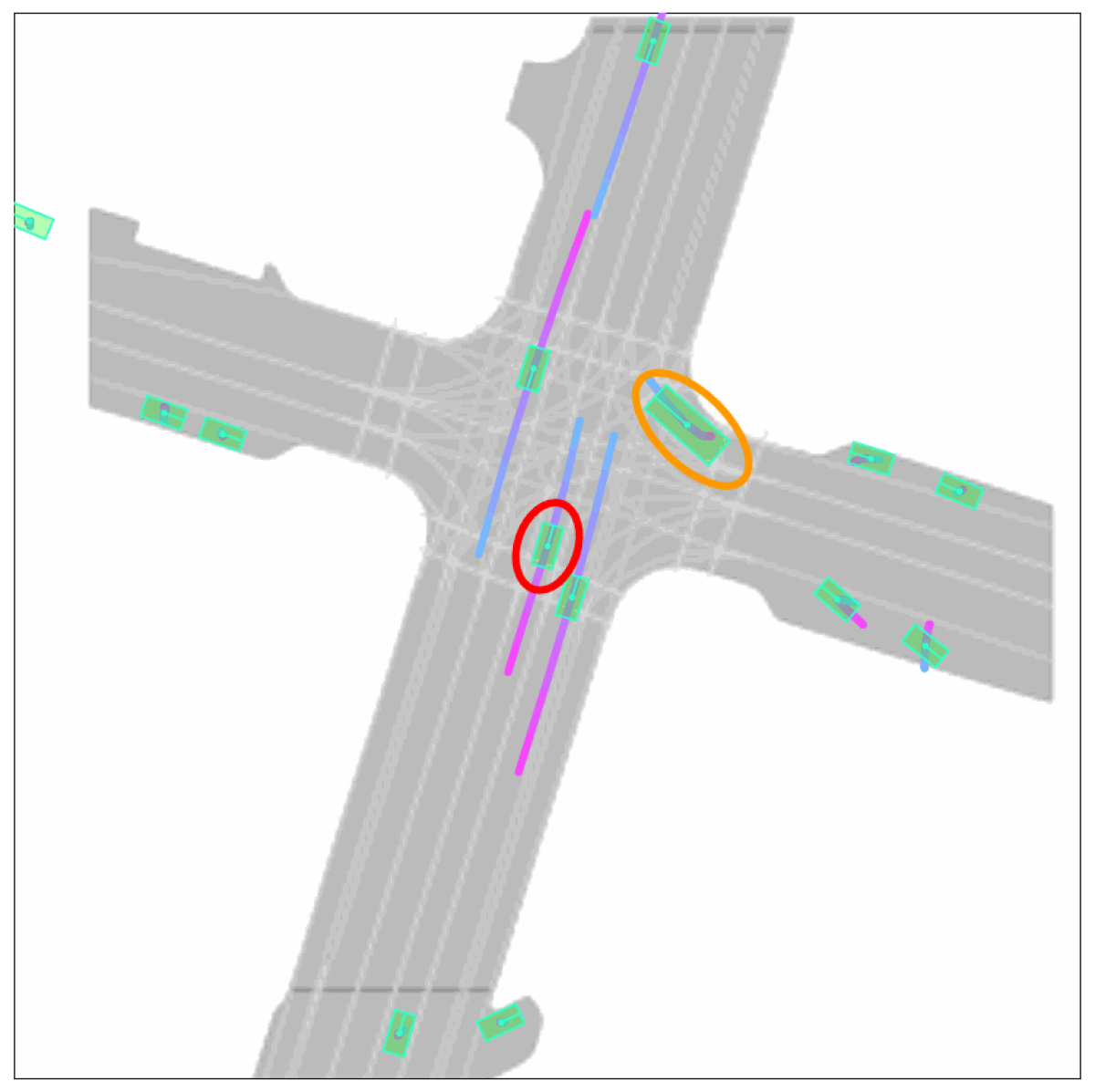
Imagine we want to validate how an AV will behave in a safety-critical situation — such as a bus turning right in front of it — on a given map. Creating such scenarios is straightforward for Scenario Diffusion, thanks to its use of agent tokens and global scene tokens. Agent tokens can easily be computed from data in real-life driving logs or created by humans. Then they can be used to prompt the model to place vehicles with desired characteristics in specific locations. The model will include those vehicles in its generated scenarios while creating additional agents to fill out the rest of the scene in a realistic manner.
With just one GPU, it takes about one second to generate a novel scenario.
Successful generalization across regions
To evaluate our model’s ability to generalize across geographical regions, we trained separate models on data from each region of the Zoox dataset. A model trained solely on driving logs from, say, San Francisco did better at generating realistic driving scenarios for San Francisco than a model trained on data from Seattle. However, models trained on the full Zoox dataset of four regions come very close to the performance of region-specialized models. These findings suggest that, while there are unique aspects of each region, the fully trained model has sufficient capacity to capture this diversity.
The ability to generalize to other cities is good news for the future of AV validation as Zoox expands into new metropolitan areas. It will always be necessary to collect real-world driving logs in new locations, using AVs outfitted with our full sensor architecture and monitored by a safety driver. However, the ability to generate supplementary synthetic data will shorten the time it takes to validate our AV control system in new areas.
We plan to build on this research by making the model’s output increasingly rich and nuanced, with a greater diversity of vehicle and object types, to better match the complexity of real streets. For example, we could ultimately design a model to generate highly complex safety scenarios, such as driving by a school location at dismissal time, with crowds of kids and parents near or spilling onto the road.
It is this powerful combination of flexibility, controllability, and increasing realism that we believe will make our Scenario Diffusion approach foundational to the future of safety validation for autonomous vehicles.
Acknowledgments: Meghana Reddy Ganesina, Noureldin Hendy, Zeyu Wang, Andres Morales, Nicholas Roy.



