
SQL database queries often include repetitions of the same operation. For instance, finding an entry in a table that corresponds to a particular person might involve pulling up all the entries with the person’s first name and all the entries with the person’s last name and computing their intersection. If the first- and last-name searches require querying the same database table twice, it’s a redundancy that can increase retrieval time.
In a paper we presented last week at the IEEE International Conference on Data Engineering (ICDE), we describe a method for rewriting complex SQL queries so as to eliminate such redundancies. Sometimes, that involves retrieving a superset of entries and then winnowing them down according to additional criteria. But in general, a little extra computation after retrieval is more efficient than multiple queries of the same table.
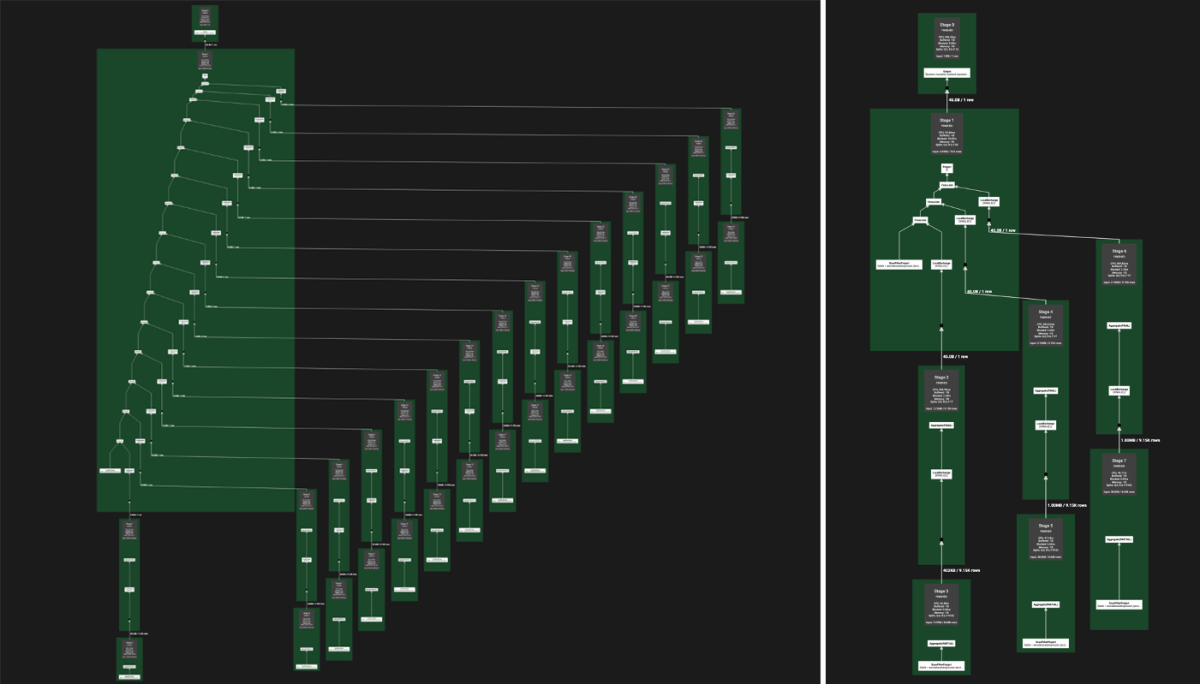
In experiments on the TPC-DS benchmark database, with 3TB of data, our techniques improved the overall execution time on 99 queries by 14%, compared to the baseline. When restricted to those queries that are directly transformed by our rewrite rules, we observed 60% improvement in performance, with some queries executing more than six times as quickly.
Query rewrite
A query plan is a sequence of steps such as data scans and aggregations that are used to execute a query. Query plan optimization is the process of choosing the most efficient query plan from a large number of possible alternatives.

The focus of our work is to identify subqueries computing on overlapping data and fuse them into a single computation with compensating actions (post-retrieval computations) to reconstruct the original results. It does not require the subqueries to be syntactically the same or to produce the same output.
Consider the below query as an example:
WITH cte as (...complex_subquery...) SELECT customer_id FROM cte WHERE fname = 'John' UNION ALL SELECT customer_id FROM cte WHERE lname = 'Smith'
The query uses the block cte twice in the FROM clause. This is suboptimal, especially if the duplicated computation is expensive. Our technique can identify such patterns and rewrite them. For instance, the above query becomes
WITH cte as (...complex_subquery...) SELECT customer_id FROM cte, (VALUES (1), (2)) T(tag) WHERE (fname = 'John' AND tag=1) OR (lname = 'Smith' AND tag=2)
Although the common expressions are not exactly the same (there are different filter conditions in the WHERE clause), we are able to rewrite the query into a fragment that generates a superset of the required rows and columns and handles the differences via compensating actions.
Note that in general, not all queries with repeated expressions can be rewritten by eliminating the duplicated work. However, beyond the query pattern shown here, there are several scenarios in which rewrites are applicable.
Building blocks of the rewriting rules

Here are the primitives that will be used in our new query plan optimization rules. Specifically, we define a function Fuse that takes two input plans and returns either ⊥ (when fusion is not possible) or a 4-tuple fused result. If Fuse(P1, P2) = (P, M, L, R), then
- P is the resulting fused plan. The schema of P includes all output columns in P1 and, optionally, additional output columns from P2.
- M is a mapping from the output columns of P2 to output columns of P.
- L and R are two filter conditions defined over the output columns of P to restore P1 and P2, respectively.
Semantically, we can reconstruct P1 and P2 as follows:
P1 = ProjectoutCols(P1)(FilterL(P)) P2 = ProjectM(outCols(P2))(FilterR(P))
where outCols(P) denotes the output columns of plan P.
Fuse is a recursive function that can handle different operators such as table scan, filter, projection, join, aggregation, and distinct aggregation.
Optimization rules
We have introduced several optimization rules that rewrite the query plan based on the primitives defined above. New rules can be added if we find prevalent enough patterns, and a semantically equivalent representation is available.
- GroupByJoinToWindow
This rule transforms a common pattern in which an expression is aggregated and joined back to itself to obtain additional information on the aggregated rows. Intuitively, it is a calculation that extends an input relation with aggregates computed on a subset of columns. Window functions operate in this manner and can be used to rewrite the original pattern.
- JoinOnKeys
This rule addresses a common pattern in which similar subqueries, which return different views of the same data, are self-joined together. Because of the existence of keys, each row from the left matches with at most one row from the right. Therefore, we are extending each row that matches with columns from both sides.
- UnionAllOnJoin
This rule handles scenarios in which customers combine results of two computations that are very similar overall but differ on a single table (e.g., they union together some analytical insight applied over different fact tables).
- UnionAll
This rule corresponds to the example query in the preceding section. It is a common pattern that customers use to compute a common expression and then union non-necessarily disjoint subsets of the result with different projections.
The work presented in the paper is already used in production. It is worth noting that although Athena benefits from it, the same techniques are applicable to other database systems, since they do not require implementing new operators or execution models.
We are glad to see that, as a result, our customers are running their queries faster and, because of less data scanned, lowering their bills.



